
Abstract
Video self-supervised learning is a challenging task, which requires significant expressive power from the model to leverage rich spatial-temporal knowledge and generate effective supervisory signals from large amounts of unlabeled videos. However, existing methods fail to increase the temporal diversity of unlabeled videos and ignore elaborately modeling multiscale temporal dependencies in an explicit way. To overcome these limitations, we take advantage of the multi-scale temporal dependencies within videos and proposes a novel video selfsupervised learning framework named Temporal Contrastive Graph Learning (TCGL), which jointly models the inter-snippet and intra-snippet temporal dependencies for temporal representation learning with a hybrid graph contrastive learning strategy. Specifically, a Spatial-Temporal Knowledge Discovering (STKD) module is first introduced to extract motion-enhanced spatialtemporal representations from videos based on the frequency domain analysis of discrete cosine transform. To explicitly model multi-scale temporal dependencies of unlabeled videos, our TCGL integrates the prior knowledge about the frame and snippet orders into graph structures, i.e., the intra-/inter- snippet Temporal Contrastive Graphs (TCG). Then, specific contrastive learning modules are designed to maximize the agreement between nodes in different graph views. To generate supervisory signals for unlabeled videos, we introduce an Adaptive Snippet Order Prediction (ASOP) module which leverages the relational knowledge among video snippets to learn the global context representation and recalibrate the channel-wise features adaptively. Experimental results demonstrate the superiority of our TCGL over the state-of-the-art methods on large-scale action recognition and video retrieval benchmarks. The code is publicly available at https://github.com/YangLiu9208/TCGL.
Framework
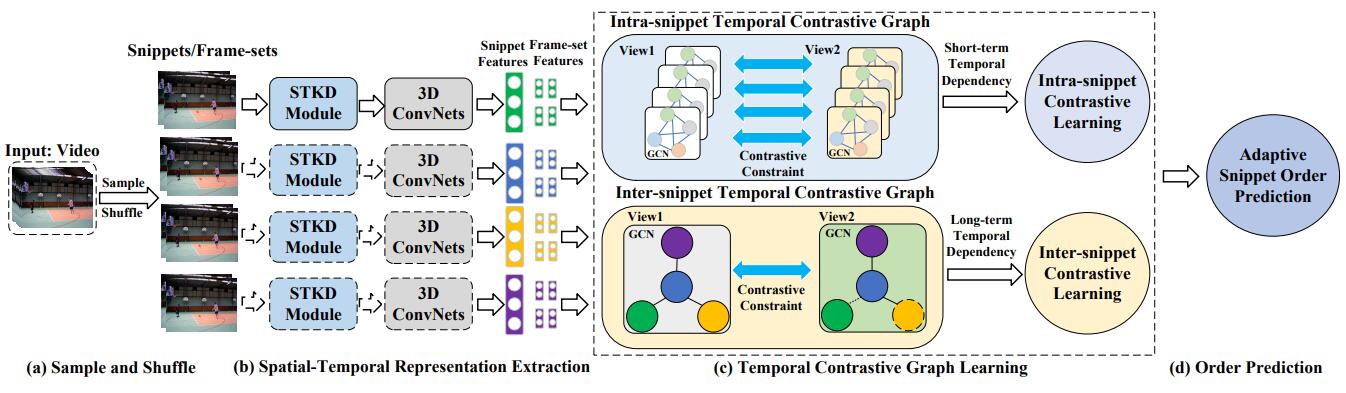
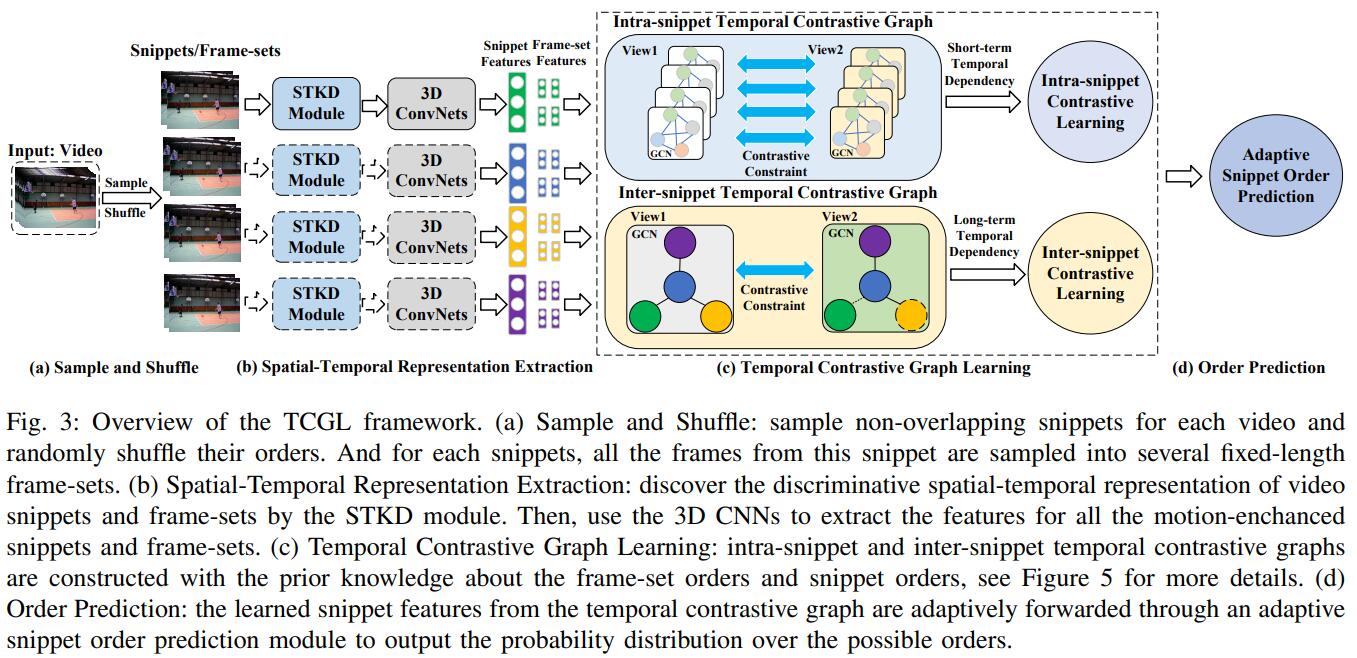
We present the overall framework in Figure 3, which mainly consists of four stages. (1) In sample and shuffle, for each video, several snippets are uniformly sampled and shuffled. For each snippet, all of its frames are sampled into several fixed-length frame-sets. (2) In feature extraction, we discover motionenhanced spatial-temporal representation of video snippets and frame-sets by the Spatial-Temporal Knowledge Discovering (STKD) module. Then, 3D CNNs are utilized to extract spatial-temporal features for these motion-enhanced snippets and frame-sets, and all 3D CNNs share the same weights. (3) In temporal contrastive learning, we build two kinds of temporal contrastive graph structures (intra-snippet graph and inter-snippet graph) with the prior knowledge about the frameset orders and snippet orders. To generate different correlated graph views for specific graphs, we randomly remove edges and mask node features of the intra-snippet graphs or intersnippet graphs. Then, we design specific contrastive losses for both the intra-snippet and inter-snippet graphs to enhance the discriminative capability for discriminative temporal representation learning. (4) In the order prediction, the learned snippet features from the temporal contrastive graph are adaptively forwarded through an adaptive snippet order prediction module to output the probability distribution over the possible orders.
Experiment

Conclusion
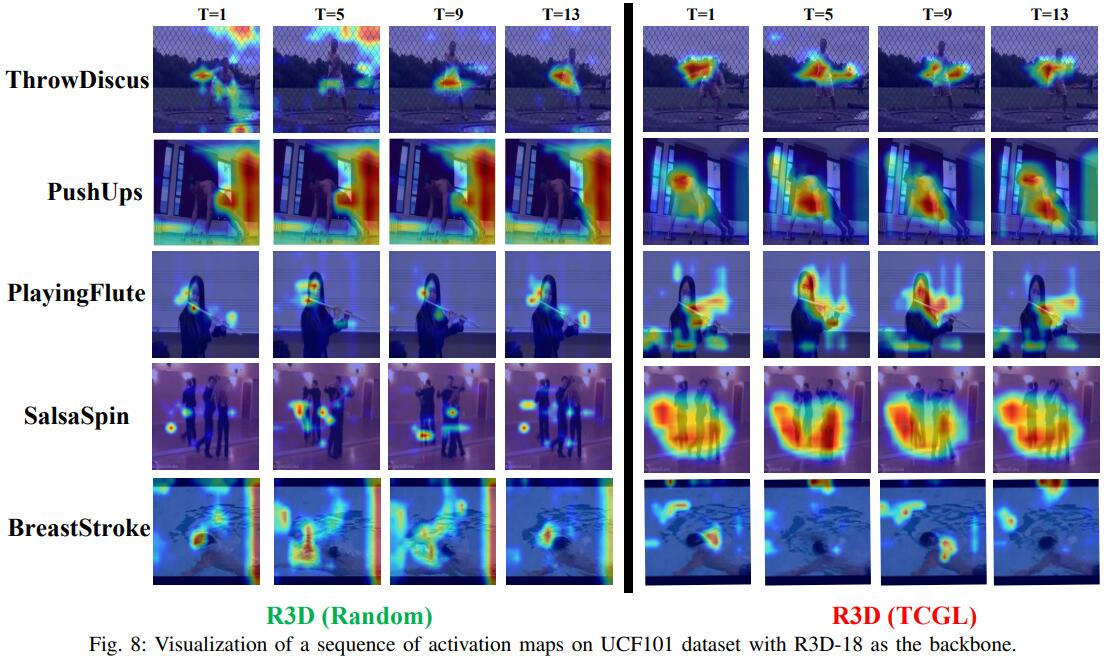
In this paper, we proposed a novel Temporal Contrastive Graph Learning (TCGL) approach for self-supervised video representation learning. We fully discover discriminative spatial-temporal representation by strict theoretical analysis in the frequency domain based on discrete cosine transform. Integrated with intra-snippet and inter-snippet temporal dependencies, we introduced intra-snippet and inter-snippet temporal contrastive graphs to increase the temporal diversity among video frames and snippets in a graph contrastive self-supervised learning manner. To learn the global context representation and recalibrate the channel-wise features adaptively for each video snippet, we proposed an adaptive video snippet order prediction module, which employs the relational knowledge among video snippets to predict orders. With interintra snippet graph contrastive learning strategy and adaptive video snippet order prediction task, the temporal diversity and multi-scale temporal dependency can be well discovered. The proposed TCGL is applied to video action recognition and video retrieval tasks with three kinds of 3D CNNs. Extensive experiments demonstrate the superiority of our TCGL over the state-of-the-art methods on large-scale benchmarks. Future direction will be the evaluation of our method with more powerful backbones, larger pretrained datasets, and more downstream tasks.
Acknowledgement
This work is supported in part by the National Natural Science Foundation of China under Grant No.62002395, in part by the National Natural Science Foundation of Guangdong Province (China) under Grant No. 2021A15150123, and in part by the China Postdoctoral Science Foundation funded project under Grant No.2020M672966.
References
D. Xu, J. Xiao, Z. Zhao, J. Shao, D. Xie, and Y. Zhuang, “Selfsupervised spatiotemporal learning via video clip order prediction,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 10 334–10 343.
Y. Yao, C. Liu, D. Luo, Y. Zhou, and Q. Ye, “Video playback rate perception for self-supervised spatio-temporal representation learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 6548–6557.
J. Xiao, L. Li, D. Xu, C. Long, J. Shao, S. Zhang, S. Pu, and Y. Zhuang, “Explore video clip order with self-supervised and curriculum learning for video applications,” IEEE Transactions on Multimedia, 2020.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab