
Abstract
Referring image segmentation aims at segmenting out the object or stuff referred to by a natural language expression. The challenge of this task lies in the requirement of understanding both vision and language. The linguistic structure of a referring expression can provide an intuitive and explainable layout for reasoning over visual and linguistic concepts. In this paper, we propose a structured attention network (SANet) to explore the multimodal reasoning over the dependency tree parsed from the referring expression. Specifically, SANet implements the multimodal reasoning using an attentional multimodal tree-structure recurrent module (AMTreeGRU) in a bottomup manner. In addition, for spatial detail improvement, SANet further incorporates the semantics-guided low-level features into high-level ones using the proposed attentional skip connection module. Extensive experiments on four public benchmark datasets demonstrate the superiority of our proposed SANet with more explainable visualization examples.
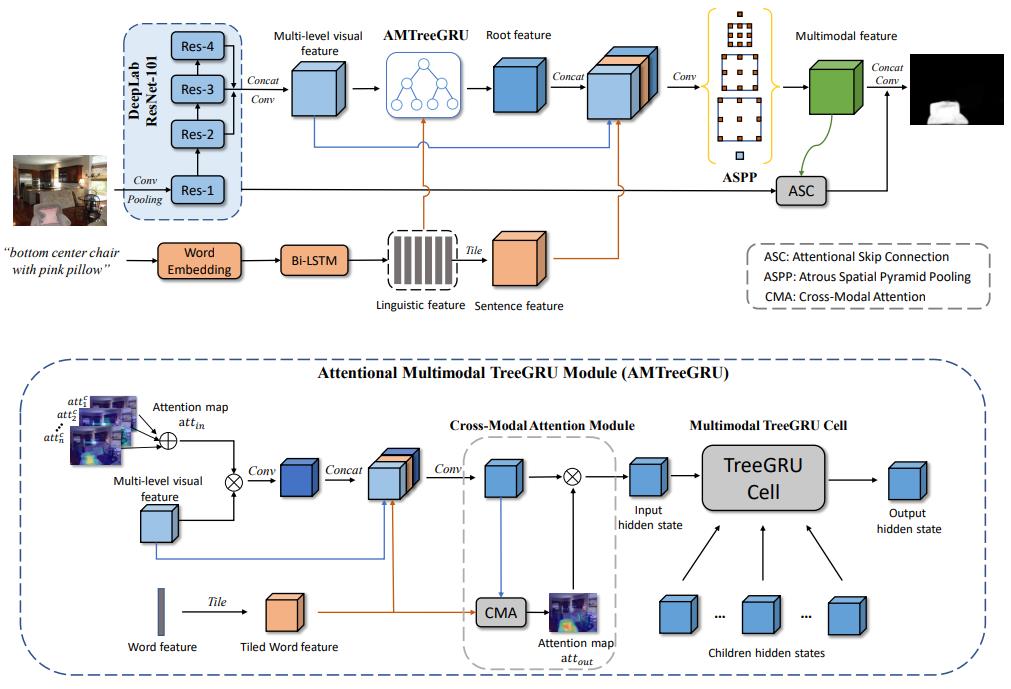
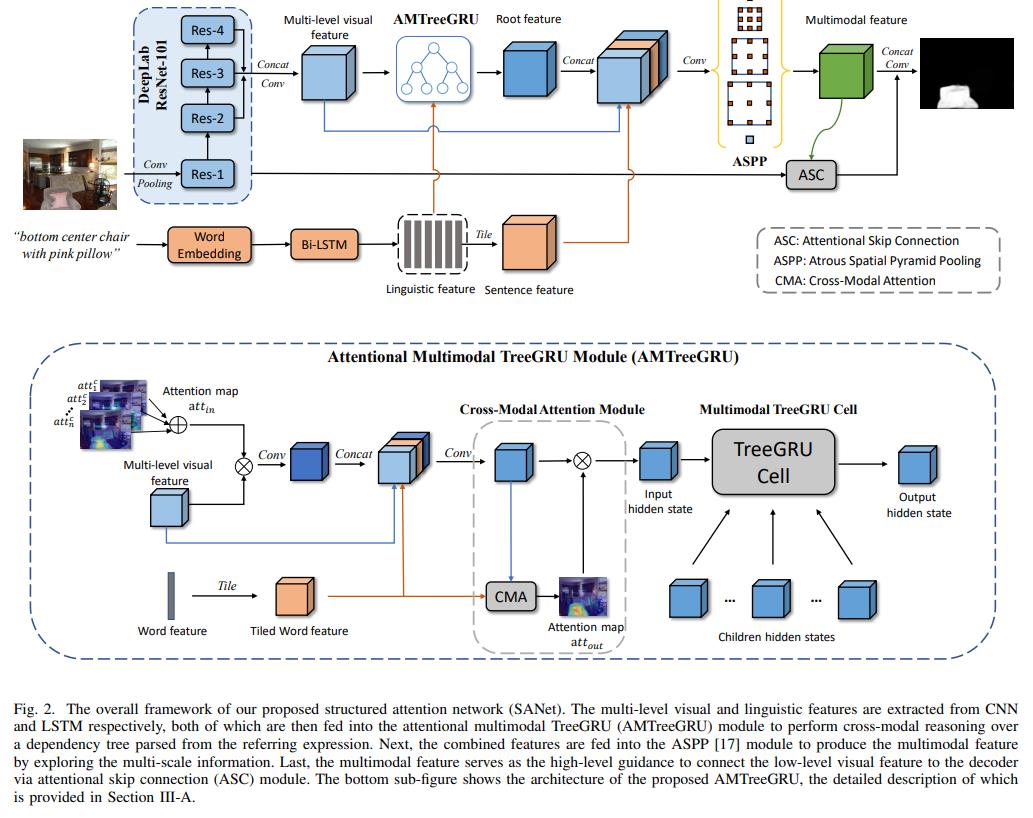
Framework
The overall framework of the proposed structured attention network (SANet) is shown in Figure 2. The visual and linguistic features are extracted from the visual backbone and language model, respectively. To better align the visual and linguistic domains, the attentional multimodal TreeGRU (AMTreeGRU) is proposed to perform bottomup co-reasoning between visual and linguistic features. In addition, the attentional skip connection (ASC) module is proposed to improve the spatial details of the referred regions. The attention mechanisms mentioned in AMTreeGRU and ASC are both achieved by a crossmodal attention (CMA) module. Specifically, the CMA module weights the input feature map F under the guidance of a feature map G of different modals and outputs a guided attention map attout and a softly weighted output feature map Fˆ, which is formulate as attout, Fˆ = CMA(F, G). Finally, we introduce the rest modules in Section III-D to provide a complete description of the proposed SANet.
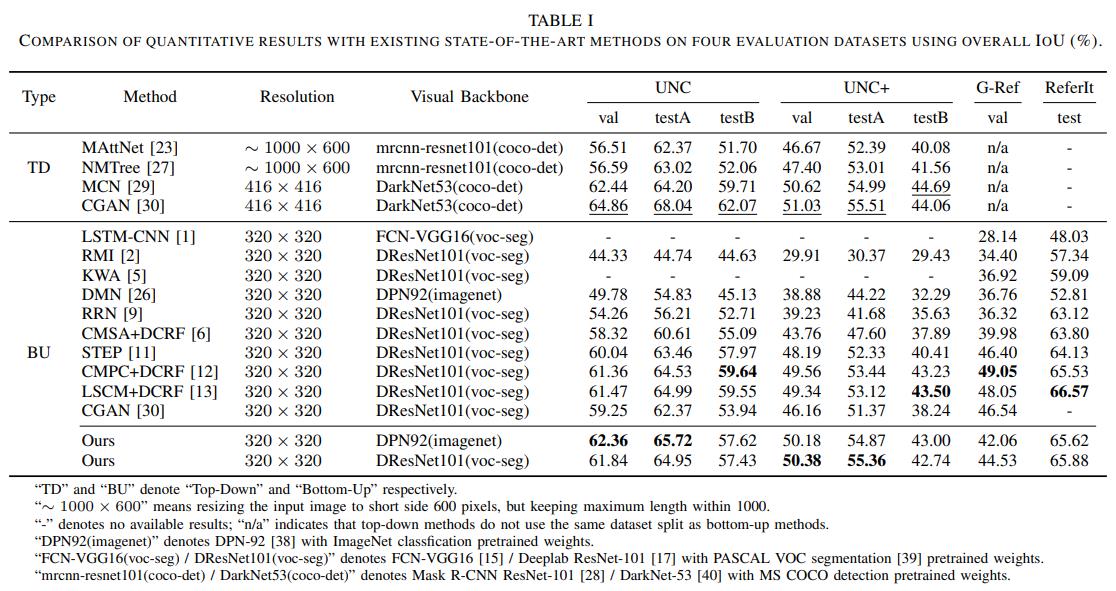
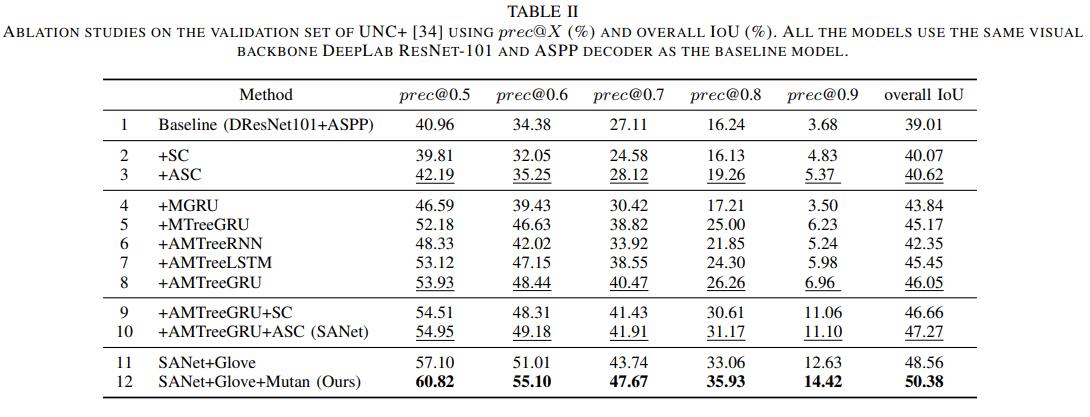
Experiment

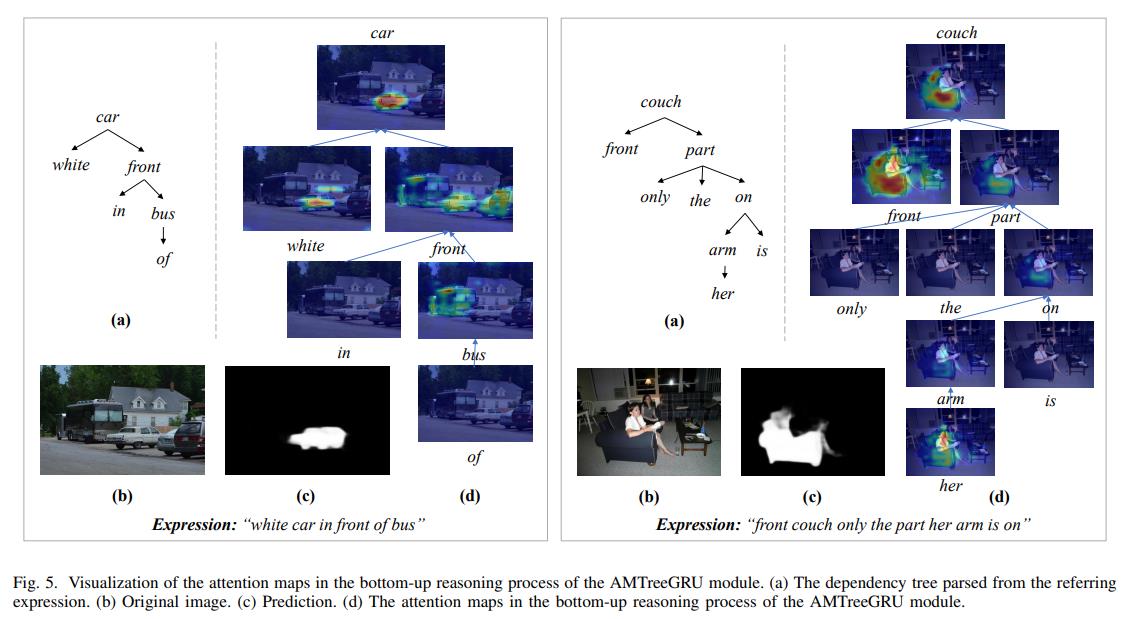
Conclusion
In this paper, we address the task of referring image segmentation by leveraging the structural information implied by natural language expressions using the proposed SANet, which consists of two major components, i.e., AMTreeGRU and ASC modules. AMTreeGRU performs interpretable crossmodal reasoning over a dependency tree parsed from the referring expression. ASC improves the spatial details of the referred region by introducing low-level features under the guidance of high-level semantics. Benefiting from these two modules, our proposed SANet is comparable to the existing state-the-art methods on four benchmark datasets. Extensive ablation experiments have also demonstrated the effectiveness of our proposed model.
Acknowledgement
This work was supported in part by the National Key Research and Development Program of China under Grant No.2018YFC0830103, in part by the National Natural Science Foundation of China under Grant No.61976250 and No.U1811463, in part by the Guangdong Basic and Applied Basic Research Foundation under Grant No.2020B1515020048, in part by the Natural Science Foundations of Guangdong under Grant No. 2017A03031335, in part by National High Level Talents Special Support Plan (Ten Thousand Talents Program). This work was also sponsored by CCF-Tencent Open Research Fund.
References
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” arXiv preprint arXiv:1706.05587, 2017.
L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoderdecoder with atrous separable convolution for semantic image segmentation,” in Proceedings of the European Conference on Computer vision, 2018, pp. 801–818.
S. Yang, G. Li, and Y. Yu, “Relationship-embedded representation learning for grounding referring expressions,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab