
Abstract
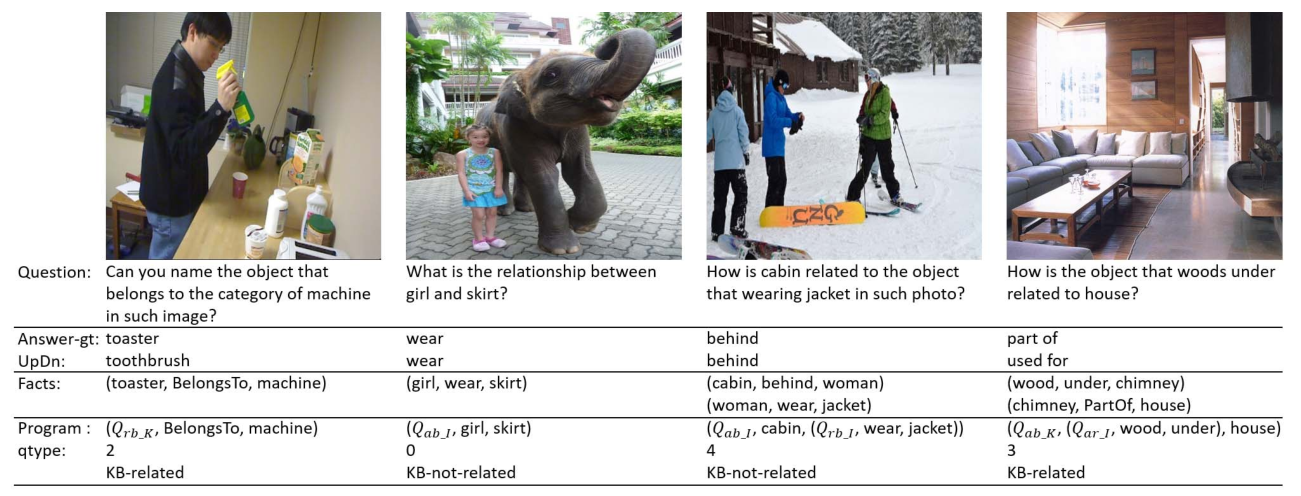
Though beneficial for encouraging the visual ques-tion answering (VQA) models to discover the underlying knowl-edge by exploiting the input–output correlation beyond image and text contexts, the existing knowledge VQA data sets are mostly annotated in a crowdsource way, e.g., collecting questions and external reasons from different users via the Internet. In addition to the challenge of knowledge reasoning, how to deal with the annotator bias also remains unsolved, which often leads to superficial overfitted correlations between questions and answers. To address this issue, we propose a novel data set named knowledge-routed visual question reasoning for VQA model evaluation. Considering that a desirable VQA model should correctly perceive the image context, understand the question, and incorporate its learned knowledge, our proposed data set aims to cut off the shortcut learning exploited by the current deep embedding models and push the research boundary of the knowledge-based visual question reasoning. Specifically, we gen-erate the question–answer pair based on both the visual genome scene graph and an external knowledge base with controlled programs to disentangle the knowledge from other biases. The programs can select one or two triplets from the scene graph or knowledge base to push multistep reasoning, avoid answer ambiguity, and balance the answer distribution. In contrast to the existing VQA data sets, we further imply the following two major constraints on the programs to incorporate knowledge reasoning. First, multiple knowledge triplets can be related to the question, but only one knowledge relates to the image object. This can enforce the VQA model to correctly perceive the image instead of guessing the knowledge based on the given question solely. Second, all questions are based on different knowledge, but the candidate answers are the same for both the training and test sets. We make the testing knowledge unused during training to evaluate whether a model can understand question words and handle unseen combinations. Extensive experiments with various baselines and state-of-the-art VQA models are conducted to demonstrate that there still exists a big gap between the model with and without groundtruth supporting triplets when given the embedded knowledge base. This reveals the weakness of the current deep embedding models on the knowledge reasoning problem.
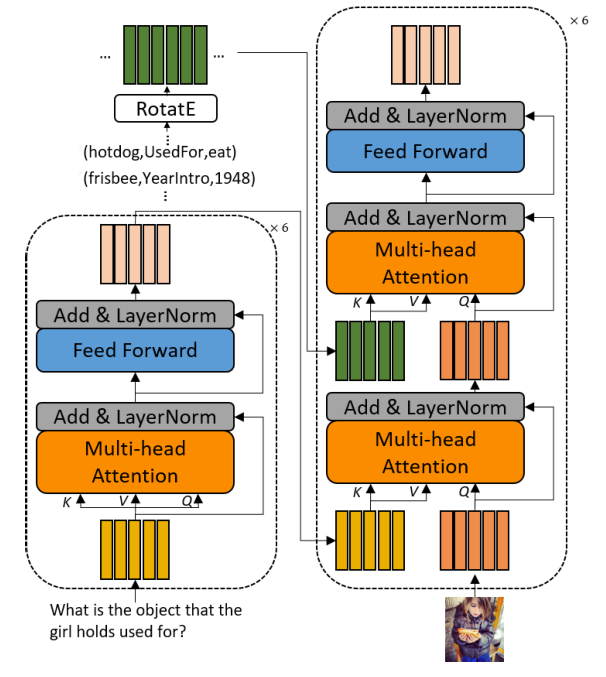
Framework

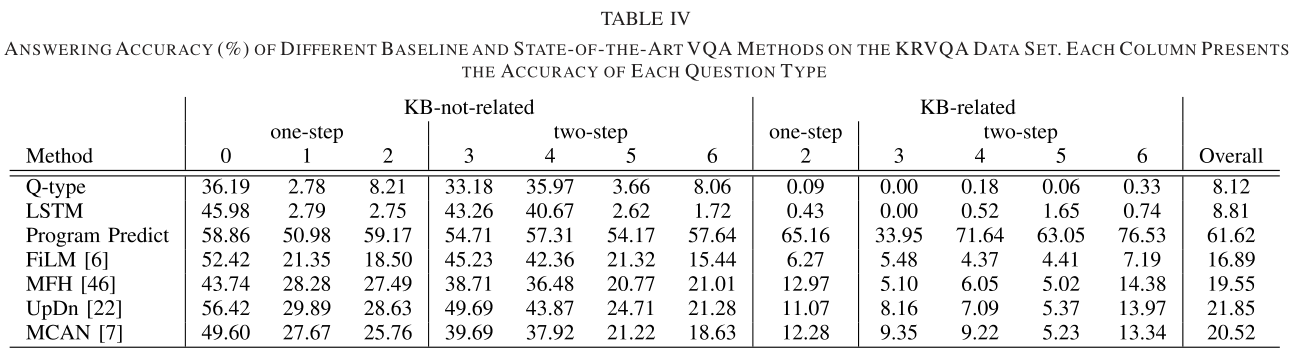
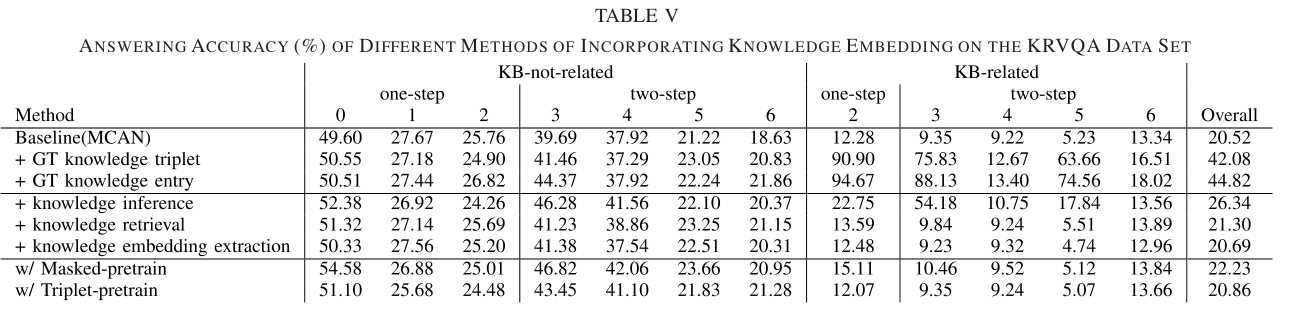
Experiment
Conclusion
In this article, we presented our KRVQA data set to eval-uate a VQA method’s ability on knowledge visual question reasoning and reveal the drawback of current deep embedding models. Specifically, we leverage the scene graph and knowl-edge base to retrieve the supporting facts and use the tightly controlled programs to generate the questions that require multistep reasoning on external knowledge. The extensive and comprehensive experiments have justified that the current VQA models cannot achieve high performances by exploiting shortcuts, due to their difficulties in handling large scale of knowledge base and retrieving the supporting one for answer prediction. In future work, we will attempt to develop novel yet powerful VQA models and evaluate their performance on this proposed data set.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab