

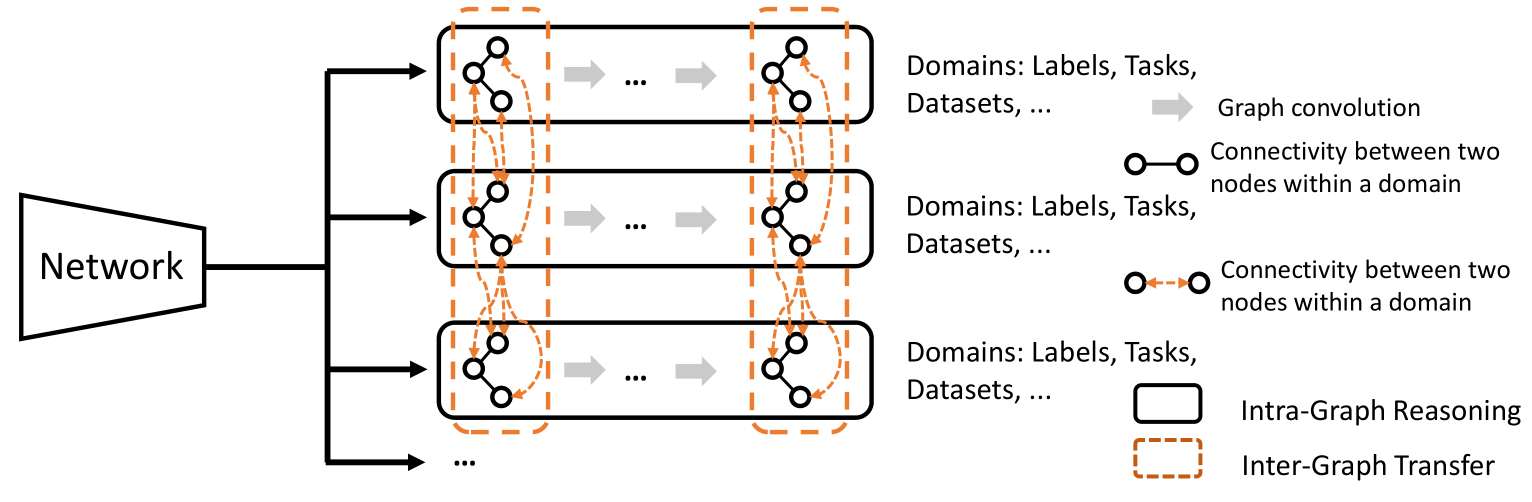
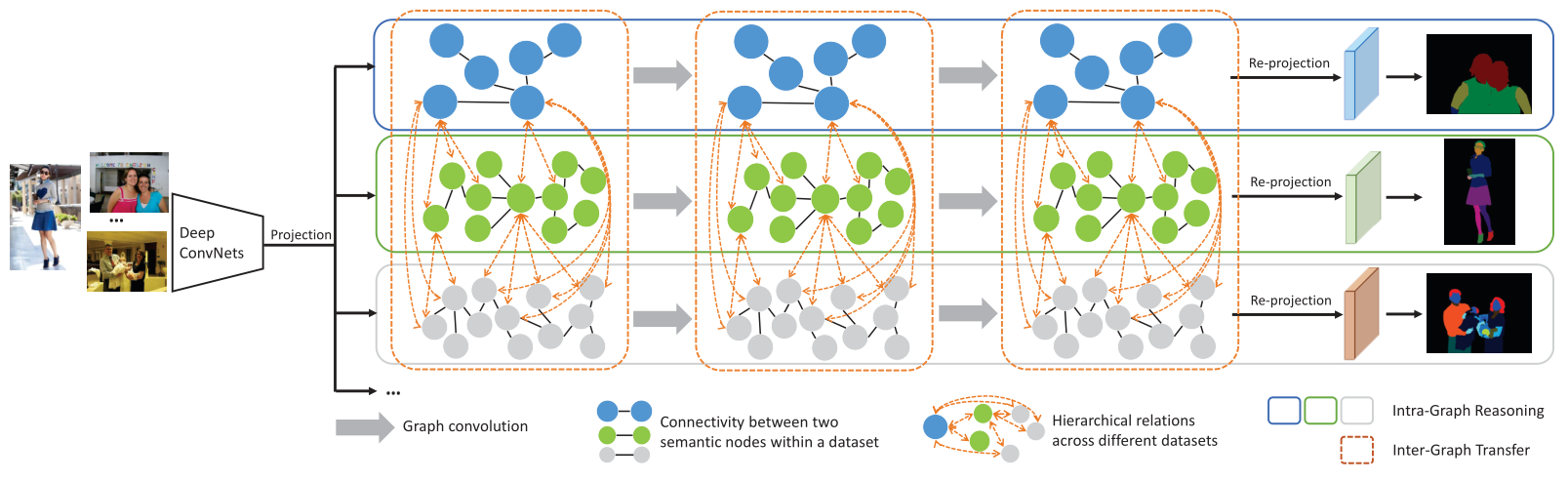
Abstract
Prior highly-tuned image parsing models are usually studied in a certain domain with a specific set of semantic labels and can hardly be adapted into other scenarios (e.g.sharing discrepant label granularity) without extensive re-training. Learning a single universal parsing model by unifying label annotations from different domains or at various levels of granularity is a crucial but rarely addressed topic. This poses many fundamental learning challenges, e.g.discovering underlying semantic structures among different label granularity or mining label correlation across relevant tasks. To address these challenges, we propose a graph reasoning and transfer learning framework, named “Graphonomy”, which incorporates human knowledge and label taxonomy into the intermediate graph representation learning beyond local convolutions. In particular, Graphonomy learns the global and structured semantic coherency in multiple domains via semantic-aware graph reasoning and transfer, enforcing the mutual benefits of the parsing across domains (e.g.different datasets or co-related tasks). The Graphonomy includes two iterated modules: Intra-Graph Reasoning and Inter-Graph Transfer modules. The former extracts the semantic graph in each domain to improve the feature representation learning by propagating information with the graph; the latter exploits the dependencies among the graphs from different domains for bidirectional knowledge transfer. We apply Graphonomy to two relevant but different image understanding research topics: human parsing and panoptic segmentation, and show Graphonomy can handle both of them well via a standard pipeline against current state-of-the-art approaches. Moreover, some extra benefit of our framework is demonstrated, e.g., generating the human parsing at various levels of granularity by unifying annotations across different datasets.
Framework
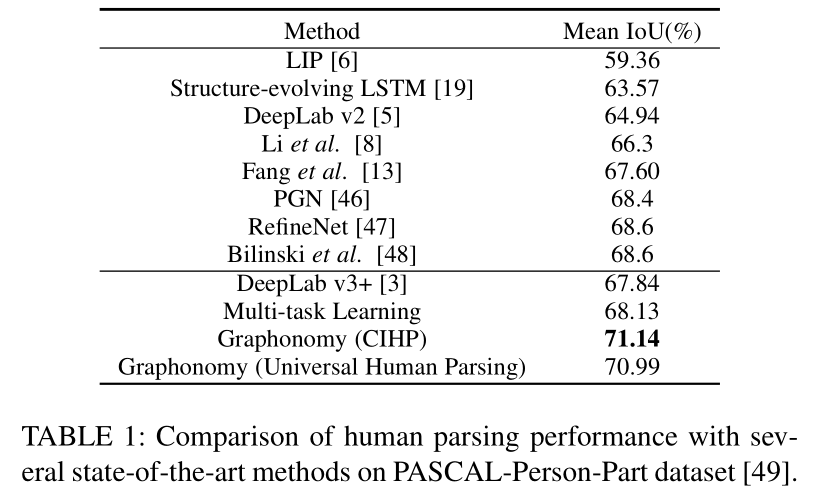
Experiment
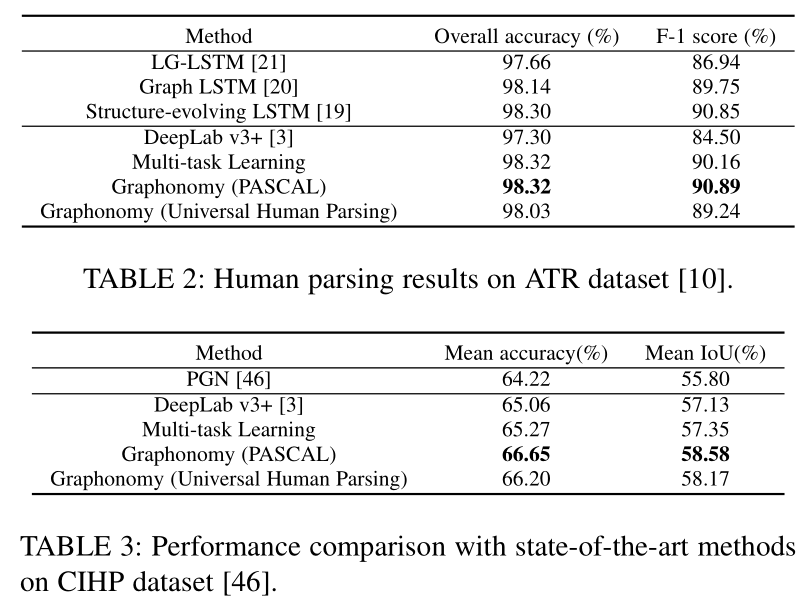


Conclusion
In this work, we have proposed a graph reasoning and transfer framework, namely Graphonomy, targeting on two crucial tasks in image semantic understanding, i.e., human parsing and panoptic scene segmentation. Our framework, in particularly, is capable of resolving all levels of human parsing tasks using a universal model to alleviate the label discrepancy and utilize the data annotations from different datasets. Graphonomy can also effectively solve panoptic scene segmentation with the same pipeline as human parsing by jointly optimizing two co-related tasks (i.e., instance-level segmentation and background stuff segmentation). The ad-vantage of the proposed framework is extensively demonstrated by the experimental analysis and achieving new state-of-the-arts against existing methods on a number of large-scale standard benchmarks (e.g., ATR, CIHP and MHP for human parsing, and MS-COCO and ADE20K for panoptic scene segmentation ). The flexibility of Graphonomy is also reflected on the diverse ways of implementation or embedding external prior knowledge for tackling other similar tasks without piling up the complexity.
There are several directions in which we can do to extend this work. The first is to explore more valid contextual relations (e.g., linguistics-aware correlations, high-order spatial relations, or object dependency in 3D coordinates) in the graph representation for further improving the performance. The second is to inves-tigate how to extend our framework to handle more challenging high-level applications beyond the pixelwise category or identity recognition. For example, understanding scene from the cognitive human-like perspective is a new trend in computer vision and general AI research, e.g., the object function understanding and human-object interaction with intention analysis. Exploring the causality-aware dependency, commonsense patterns and individ-ual value models could be very promising based on our Graphon-omy. The third is to develop more powerful reasoning and transfer learning algorithms within the model training process.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab