
Abstract
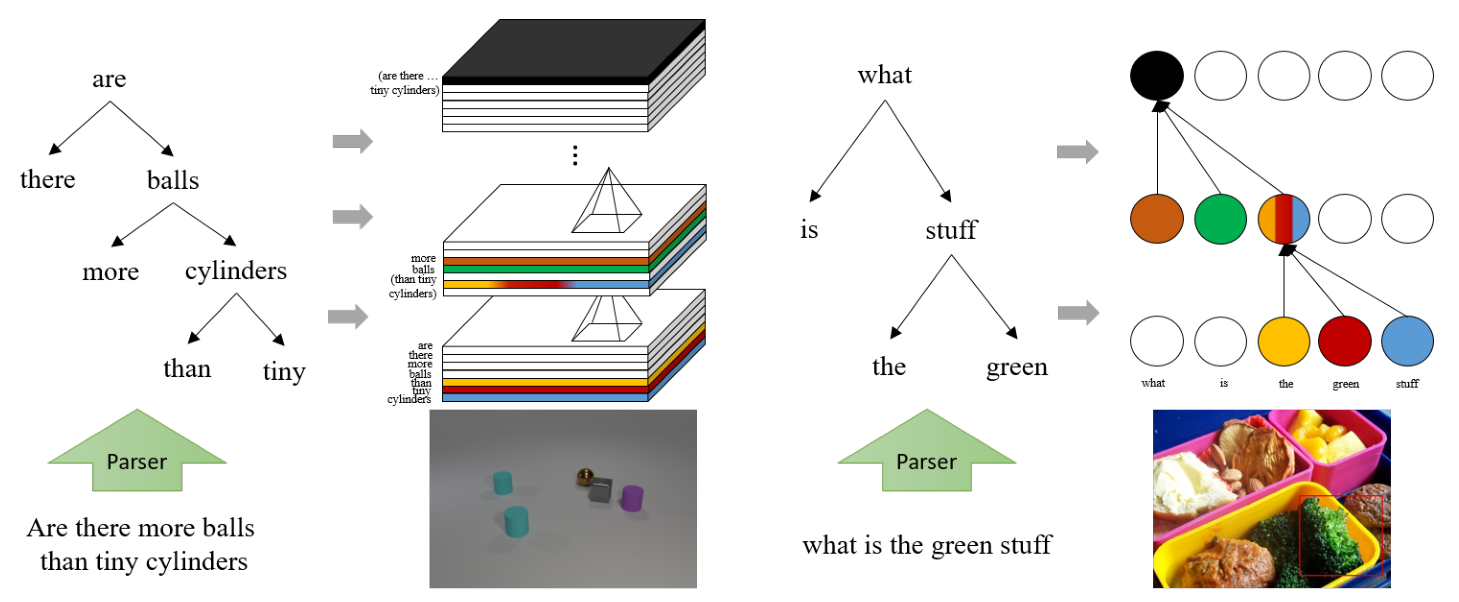
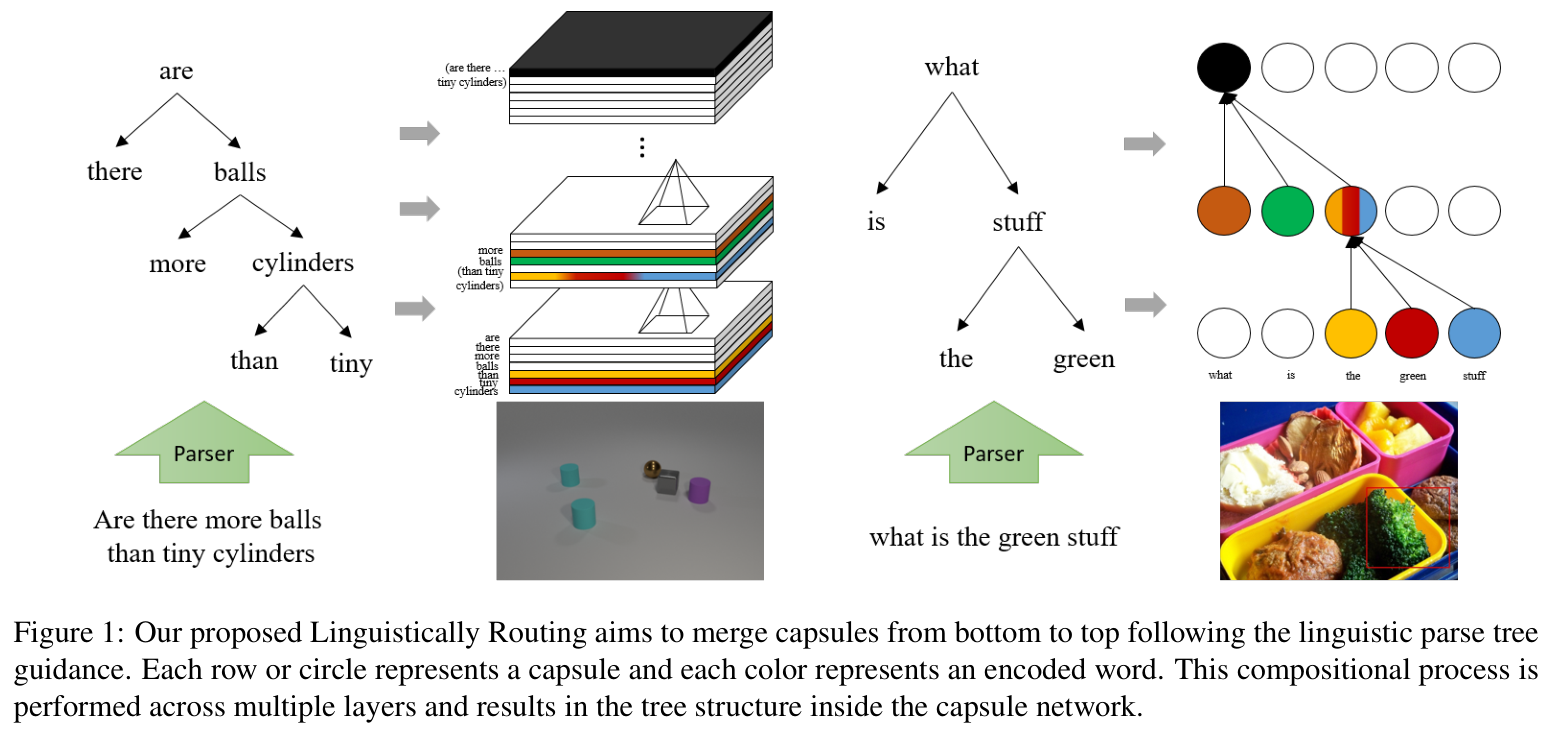
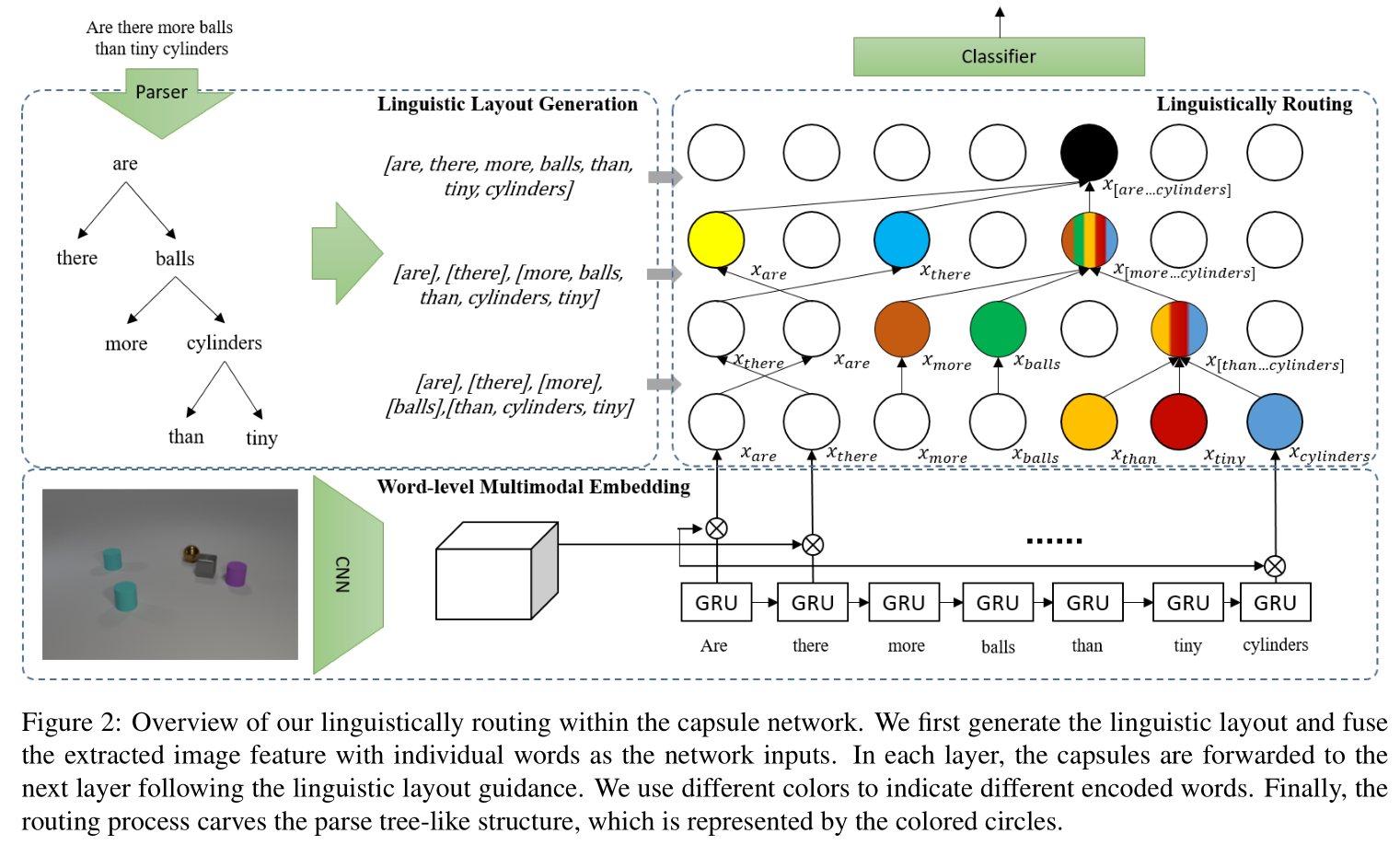
Generalization on out-of-distribution (OOD) test data is an essential but underexplored topic in visual question an-swering. Current state-of-the-art VQA models often exploit the biased correlation between data and labels, which re-sults in a large performance drop when the test and train-ing data have different distributions. Inspired by the fact that humans can recognize novel concepts by composing ex-isted concepts and capsule network’s ability of representing part-whole hierarchies, we propose to use capsules to repre-sent parts and introduce “Linguistically Routing” to merge parts with human-prior hierarchies. Specifically, we first fuse visual features with a single question word as atomic parts. Then we introduce the “Linguistically Routing” to reweight the capsule connections between two layers such that: 1) the lower layer capsules can transfer their out-puts to the most compatible higher capsules, and 2) two capsules can be merged if their corresponding words are merged in the question parse tree. The routing process max-imizes the above unary and binary potentials across multi-ple layers and finally carves a tree structure inside the cap-sule network. We evaluate our proposed routing method on the CLEVR compositional generation test, the VQA-CP2 dataset and the VQAv2 dataset. The experimental results show that our proposed method can improve current VQA models on OOD split without losing performance on the in-domain test data.
Framework
Experiment
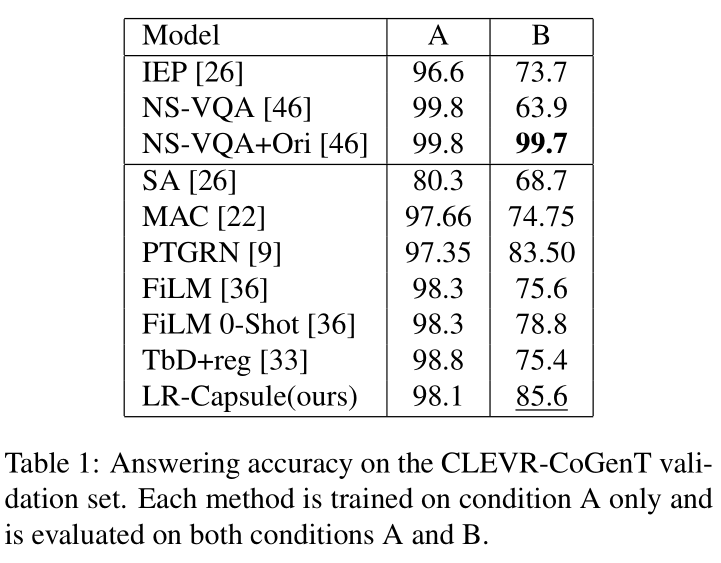
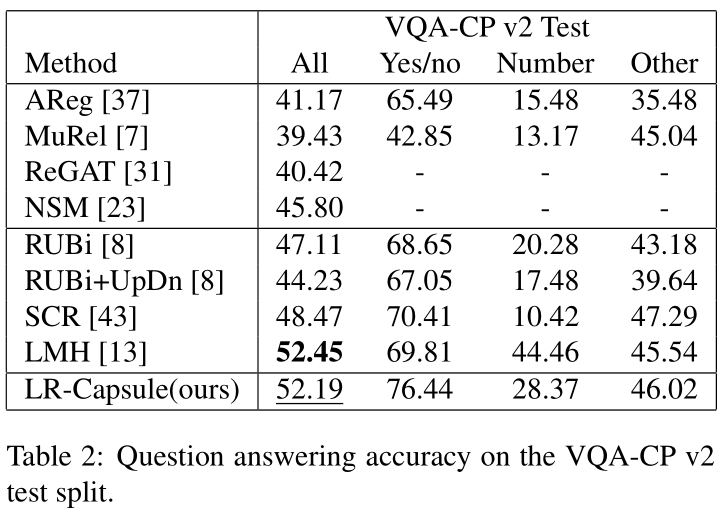
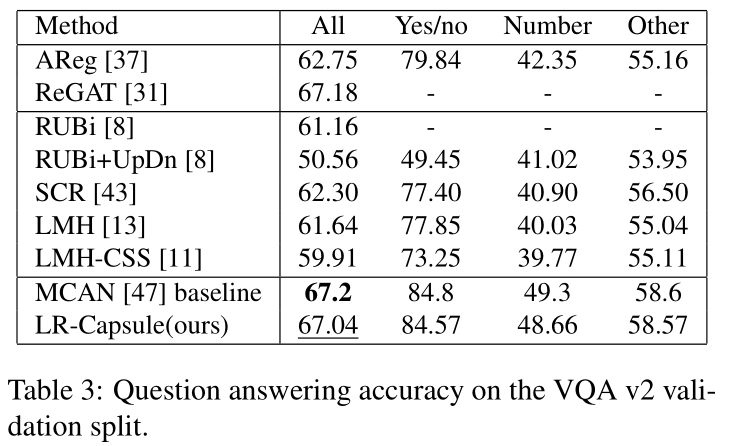
Conclusion
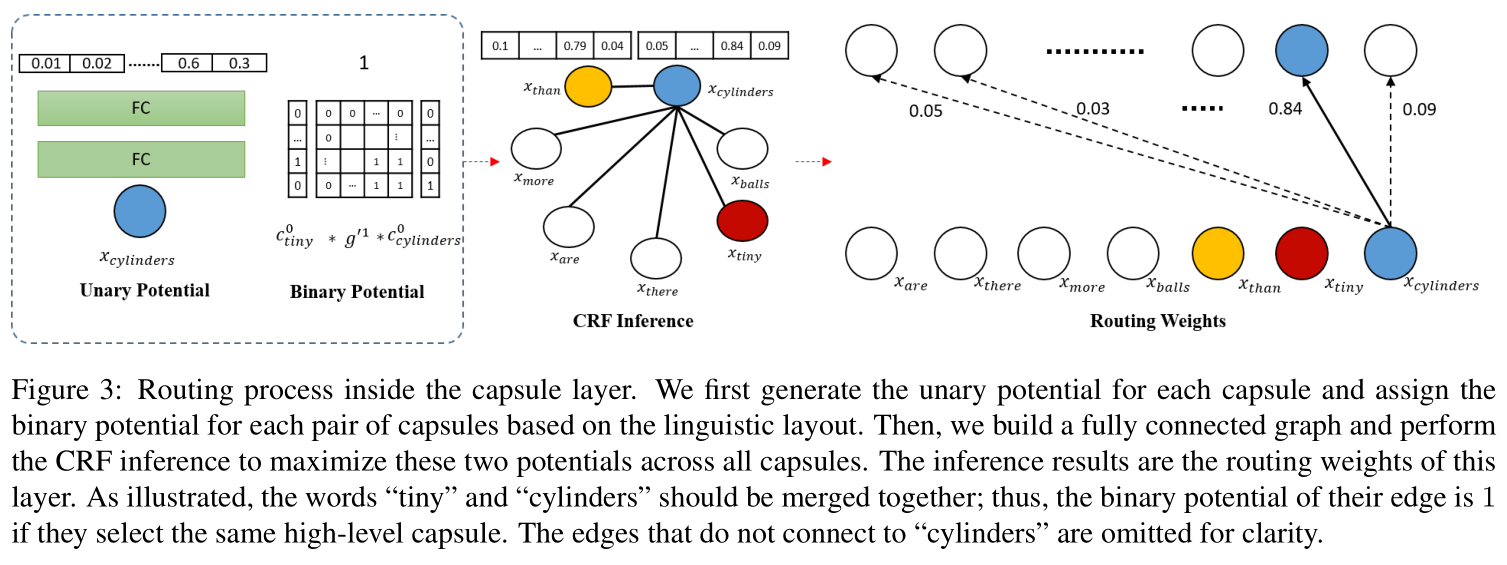
We propose the Linguistically Routing that can incorpo-rate the linguistic information in an end-to-end manner to improve the capsule network’s generalization capability on OOD data. We use the unary potential for each capsule to activate a proper high-level capsule, and use the binary po-tential for capsule pairs to incorporate the linguistic struc-tures. A CRF is applied to maximize two types of potential. As we bind the lowest visual feature with a single word, the bottom-up linguistic-guided merging process can combine the words into phrases, clauses, and finally a sentence. After forwarding all layers, the parse tree is carved inside the net-work and entangled with visual patterns. In the future, we will progressively refine our model to further improve its generalization ability and broaden its application domain
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab