
Abstract
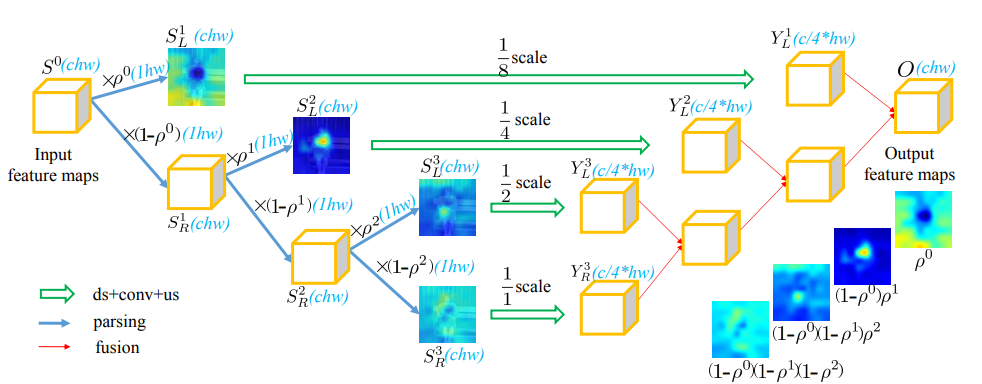
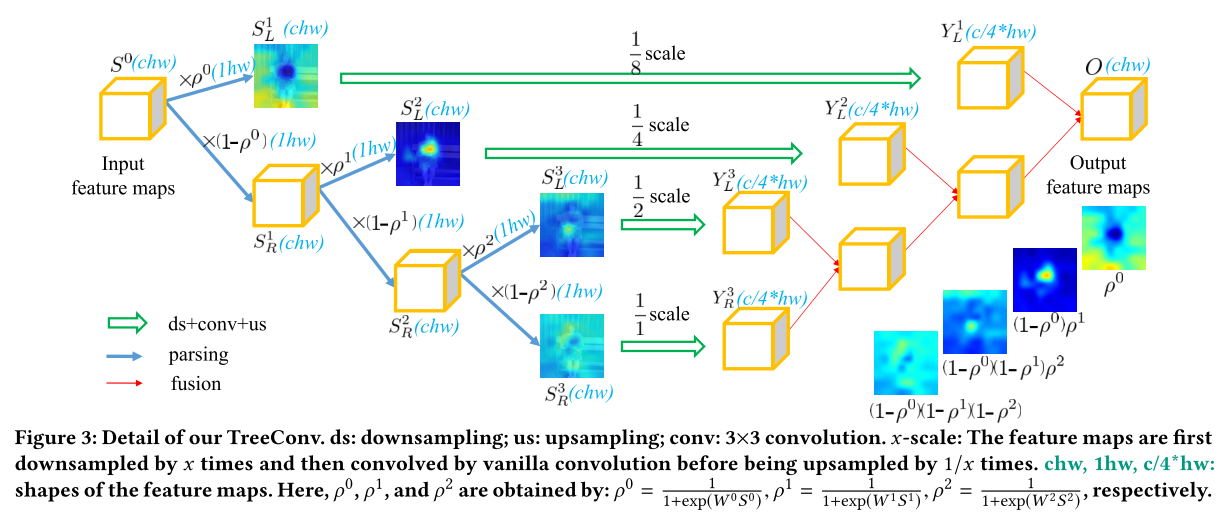
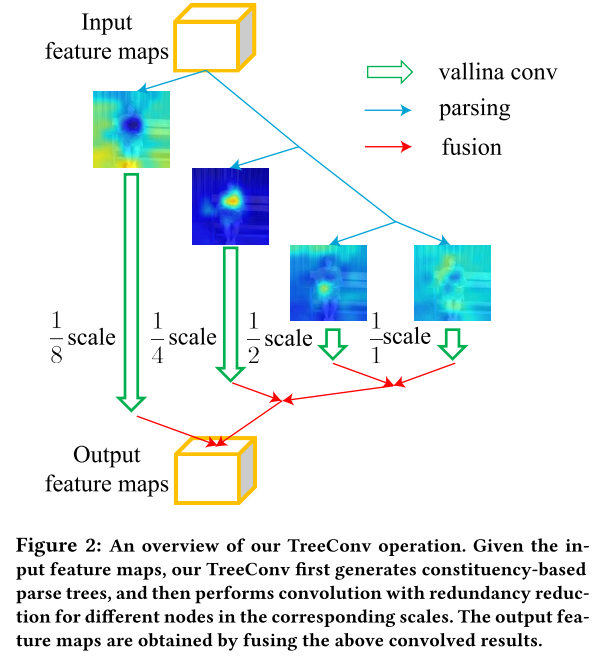
Similar to language, understanding an image can be considered as a hierarchical decomposition process from scenes to objects, parts, pixels, and the corresponding spatial/contextual relations. However, the existing convolutional networks concentrate on stacking redundant convolutional layers with a large number of kernels in a hierarchical organization to implicitly approximate this decomposition. This may limit the network to learn the semantic information conveyed in the internal feature maps that may reveal minor yet crucial differences for visual understanding. Attempting to tackle this problem, this paper proposes a simple yet effective tree convolution (TreeConv) operation for deep neural networks. Specifically, inspired by the image grammar techniques [1] that serve as a unified framework of object representation, learning, and recognition, our TreeConv designs a generative image grammar, i.e., tree generation rule, to parse the hierarchy of internal feature maps by generating tree structures and implicitly learning the specific visual grammars for each object category. Extensive experiments on a variety of benchmarks, i.e., classification (ImageNet / CIFAR), detection & segmentation (COCO 2017), and person re-identification (CUHK03), demonstrate the superiority of our TreeConv in both boosting the accuracy and reducing the computational cost. The source code will be available at https://github.com/wanggrun/TreeConv.
Framework
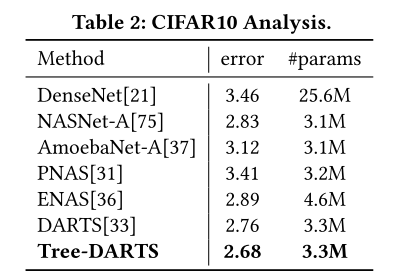
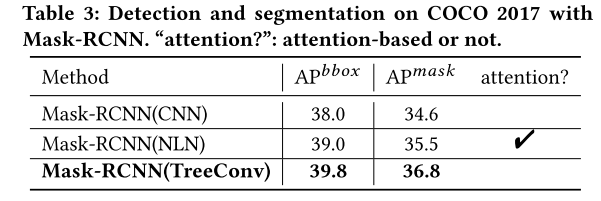
Experiment
Conclusion
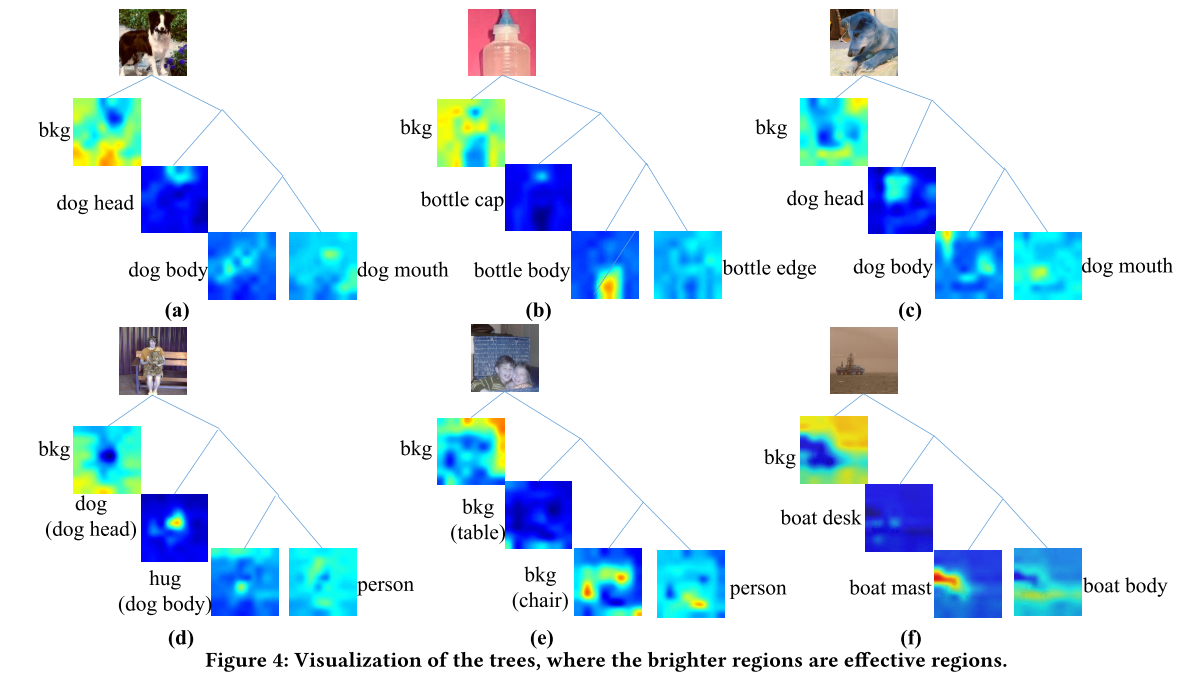
This work presented a novel tree convolution (TreeConv) operation to improve deep neural networks. Through explicitly modeling the hierarchy of internal feature maps and implicitly learning the visual grammars among them, our TreeConv not only improves the network capability and reduces the network redundancy naturally, but also provides explainable visualization results on ImageNet. However, this work only focuses on implicit visual grammar learning. Can we learn the explicit visual grammar? What is the explicit visual grammar? These questions are so difficult to answer to date. Future works will focus on these directions.
Acknowledgement
This work was supported in part by the State Key Development Program under Grant 2018YFC0830103, in part by DARPA XAI N66001-17-2-4029, in part by the National Natural Science Foundation of China under Grant U1811463, 61622214, and 61836012, and in part by Natural Science Foundation of Guangdong Province of No. 2019A1515010939 and 2017A030312006.
References
[1] Song-Chun Zhu and David Mumford. 2007. A Stochastic Grammar ofImages. Now Publishers Inc., Hanover, MA, USA.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab