
Abstract
Accelerating deep neural networks (DNNs) has been attracting increasing attention as it can benefit a wide range of applications, e.g., enabling mobile systems with limited computing resources to own powerful visual recognition ability. A practical strategy to this goal usually relies on a two stage process: operating on the trained DNNs (e.g., approximating the convolutional filters with tensor decomposition) and finetuning the amended network, leading to difficulty in balancing the trade-off between acceleration and maintaining recognition performance. In this work, aiming at a general and comprehensive way for neural network acceleration, we develop a Wavelet-like Auto-Encoder (WAE) that decomposes the original input image into two low-resolution channels (sub-images) and incorporate the WAE into the classification neural networks for joint training. The two decomposed channels, in particular, are encoded to carry the low-frequency information (e.g., image profiles) and high-frequency (e.g., image details or noises), respectively, and enable reconstructing the original input image through the decoding process. Then, we feed the low-frequency channel into a standard classification network such as VGG or ResNet and employ a very lightweight network to fuse with the high-frequency channel to obtain the classification result. Compared to existing DNN acceleration solutions, our framework has the following advantages: i) it is tolerant to any existing convolutional neural networks for classification without amending their structures; ii) the WAE provides an interpretable way to preserve the main components of the input image for classification.
Framework
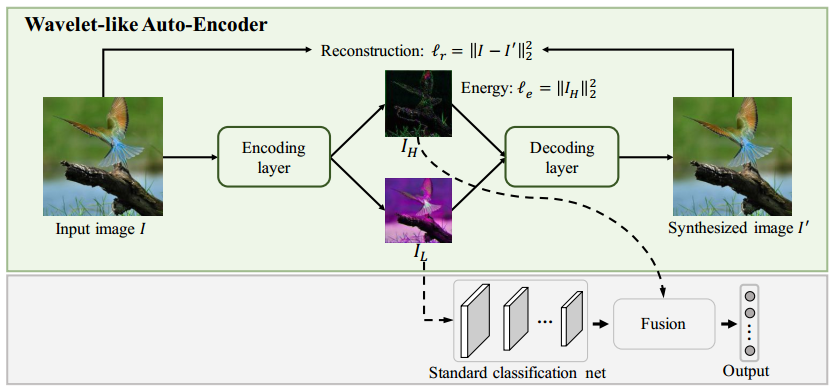
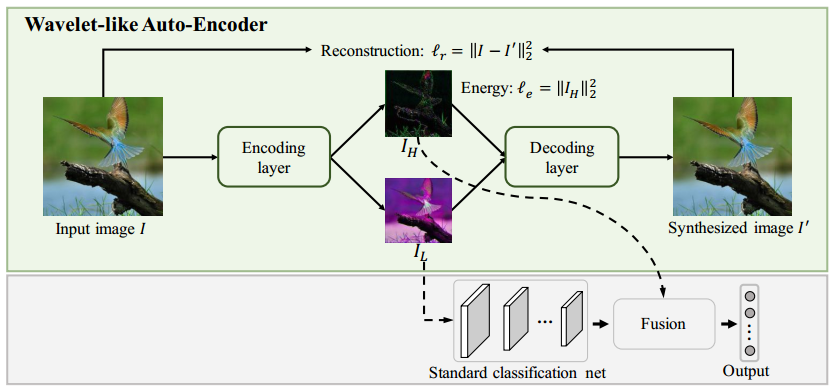
Figure: The overall framework of our proposed method. The key component of the framework is the WAE that decomposes an input image into two low-resolution channels, i.e., IL and IH. These two channels encode the high- and low-frequency information respectively and are enabled to construct the original image via a decoding process. The low-frequency channel is then fed into the a standard network (e.g., VGG16-Net or ResNet) to extract its features. Then a lightweight network fuses these features and the high-frequency channel to predict the label scores. Note that the input to the classification network is low-resolution; thus it enjoys higher efficiency.
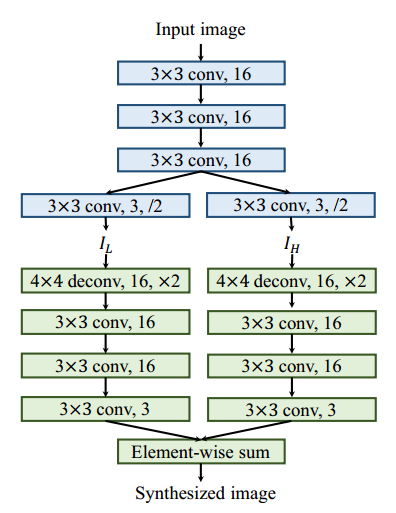
Figure: Detailed architecture of the wavelet-like autoencoder. It consists of an encoding (the blue part) and a decoding (the green part) layers. “/2” denotes a conv layer with a stride of 2 to downsample the feature maps, and conversely “×2” denotes a deconv layer with a stride of 2 to upsample the feature maps.
Experiment
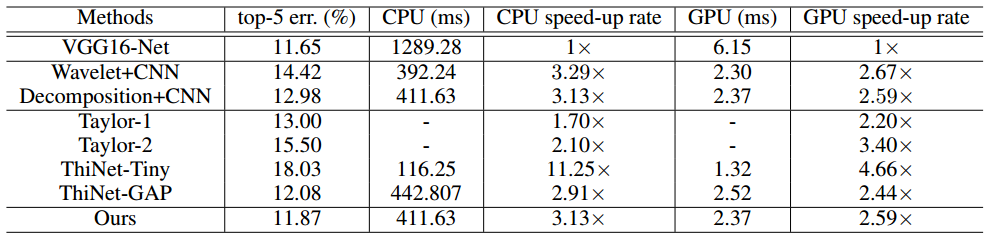
Table: Comparison of the top-5 error rate, execution time and speed-up rate on CPU and GPU of VGG16-Net, the two baseline methods and the previous state of the art methods on the ImageNet dataset. The error rate is measured on single-view without data augmentation.
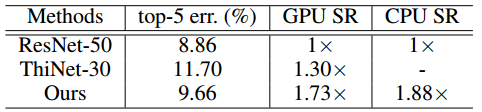
Table: Comparison of the top-5 error rate and speed-up rate (SR) of our model and ThiNet on ResNet-50 on the ImageNet dataset.
References
[1] Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition, ICLR 2015.
[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition, CVPR 2016.
[3] Jian-Hao Luo, Jianxin Wu, and Weiyao Lin. Thinet: A filter level pruning method for deep neural network compression, arXiv preprint arXiv:1707.06342.
[4] Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila, Jan Kautz, Pruning Convolutional Neural Networks for Resource Efficient Inference, arXiv preprint arXiv:1611.06440.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab