
Abstract
Image saliency detection has recently witnessed significant progress due to deep convolutional neural networks.However, extending state-of-the-art saliency detectors from image to video is challenging. The performance of salient object detection suffers from object or camera motion and the dramatic change of the appearance contrast in videos. In this paper, we present flow guided recurrent neural encoder (FGRNE), an accurate and end-to-end learning framework for video salient object detection. It works by enhancing the temporal coherence of the per-frame feature by exploiting both motion information in terms of optical flow and sequential feature evolution encoding in terms of LSTM networks. It can be considered as a universal framework to extend any FCN based static saliency detector to video salient object detection. Intensive experimental results verify the effectiveness of each part of FGRNE and confirm that our proposed method significantly outperforms state-of-the-art methods on the public benchmarks of DAVIS[12] and FBMS[10,11].
Framework
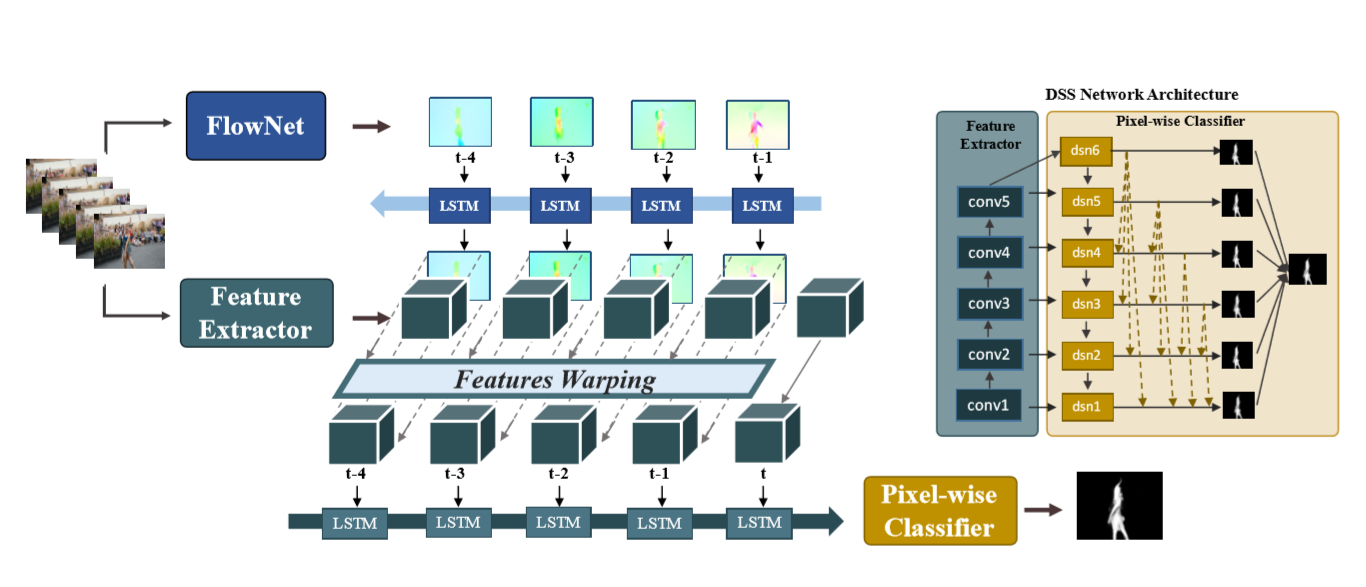
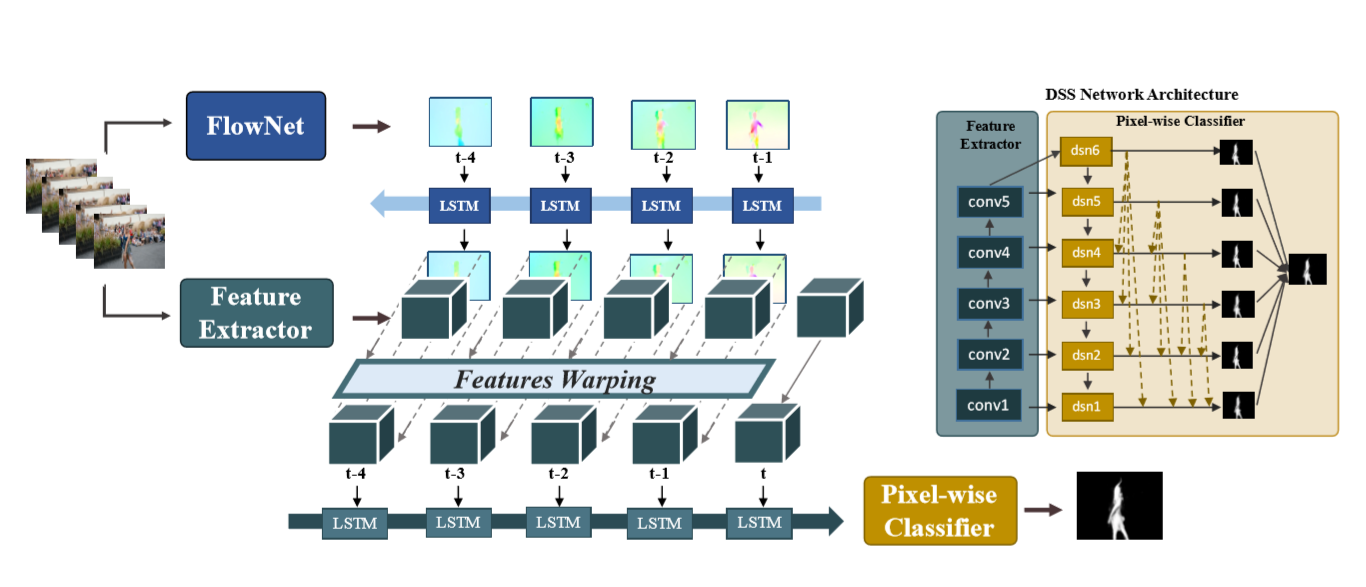
As shown above, the architecture of our FGRNE consists of three modules, including motion computing and updating, motion guided feature warping, and temporal coherence feature encoding. Specifically, we first compute an optical flow map for each of the k former frames relative to the reference frame. Each of the flow map is further fed to a LSTM in reverse order for motion refinement. Secondly, the updated flow map at each time step is applied to warp the feature map accordingly. And finally, each warped feature is consecutively fed to another LSTM for temporal coherence feature encoding, which produces the resulted feature Fi. The output saliency map is thus computed as Si = Nreg (Fi ).
Experiment
We compare our method (FGRNE) against 9 recent state-of-the-art methods, including MST [1], MB+ [2], RFCN [3], DHSNet [4], DCL [5], DSS [6], SAG [7], GF [8] and DLVSD [9].
Quantitative Comparisons

Visual Comparisons

Conclusion
In this paper, we have presented an accurate and end-to-end framework for video salient object detection. Our proposed flow guided recurrent encoder aims at improving the temporal coherence of the deep feature representation. It can be considered as a universal framework to extend any FCN based static saliency detector to video salient object detection, and can easily benefit from the future improvement of image based salient object detection methods. Moreover, as we focus on the learning an enhanced feature encoding, it can be easily extended to other applications of video analysis and it is worth exploring in the future.
References
[1] W.-C.Tu,S.He,Q.Yang,andS.-Y.Chien. Real-timesalient object detection with a minimum spanning tree. In CVPR, pages 2334–2342, 2016.
[2] J.Zhang,S.Sclaroff,Z.Lin,X.Shen,B.Price,andR.Mech. Minimumbarriersalientobjectdetectionat80fps. InICCV, pages 1404–1412, 2015.
[3] L. Wang, L. Wang, H. Lu, P. Zhang, and X. Ruan. Saliency detection with recurrent fully convolutional networks. In ECCV, pages 825–841. Springer, 2016.
[4] N. Liu and J. Han. Dhsnet: Deep hierarchical saliency network for salient object detection. In CVPR, pages 678–686, 2016
[5] G. Li and Y. Yu. Deep contrast learning for salient object detection. In CVPR, pages 478–487, 2016.
[6] Q.Hou,M.-M.Cheng,X.-W.Hu,A.Borji,Z.Tu,andP.Torr. Deeply supervised salient object detection with short connections. arXiv preprint arXiv:1611.04849, 2016.
[7] W. Wang, J. Shen, and F. Porikli. Saliency-aware geodesic video object segmentation. In CVPR, pages 3395–3402, 2015.
[8] W. Wang, J. Shen, and L. Shao. Consistent video saliency usinglocalgradientflowoptimizationandglobalrefinement. TIP, 24(11):4185–4196, 2015.
[9] W. Wang, J. Shen, and L. Shao. Video salient object detection via fully convolutional networks. TIP, 27(1):38–49, 2018.
[10]T. Brox and J. Malik. Object segmentation by long term analysis of point trajectories. ECCV, pages 282–295, 2010
[11]P. Ochs, J. Malik, and T. Brox. Segmentation of moving objects by long term video analysis. TPAMI, 36(6):1187–1200, 2014
[12] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation.In CVPR, pages 724–732, 2016
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab