
Abstract
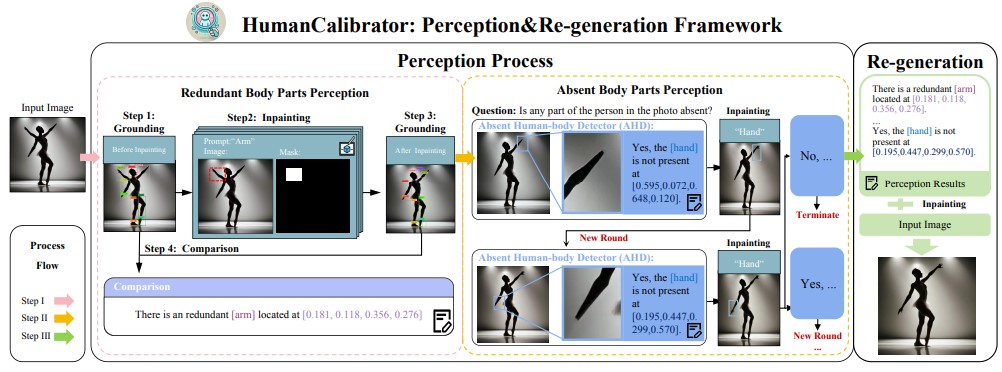
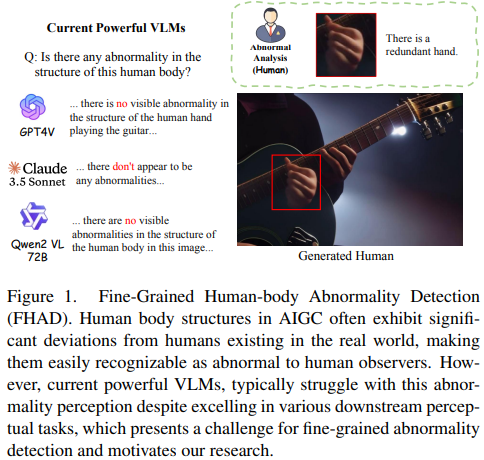
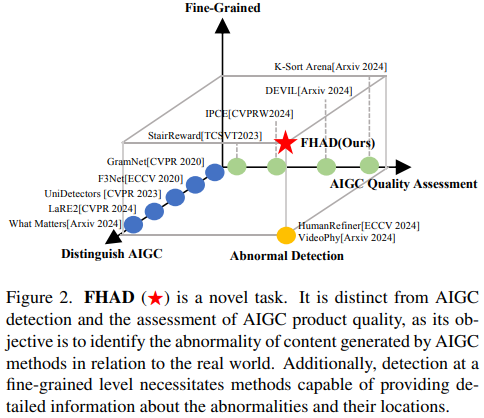
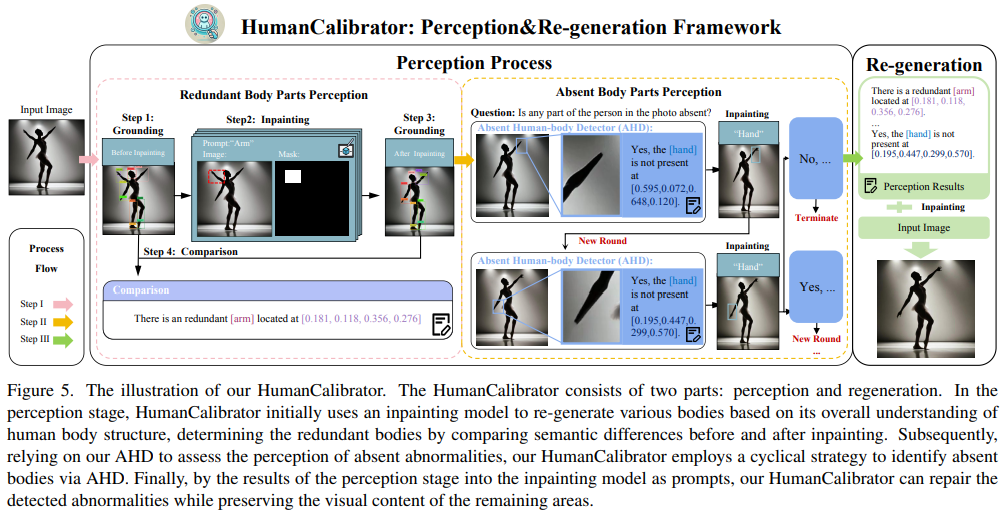
Recent improvements in visual synthesis have significantly enhanced the depiction of generated human photos, which are pivotal due to their wide applicability and demand. Nonetheless, the existing text-to-image or text-to-video models often generate low-quality human photos that might differ considerably from real-world body structures, referred to as" abnormal human bodies". Such abnormalities, typically deemed unacceptable, pose considerable challenges in the detection and repair of them within human photos. These challenges require precise abnormality recognition capabilities, which entail pinpointing both the location and the abnormality type. Intuitively, Visual Language Models (VLMs) that have obtained remarkable performance on various visual tasks are quite suitable for this task. However, their performance on abnormality detection in human photos is quite poor. Hence, it is quite important to highlight this task for the research community. In this paper, we first introduce a simple yet challenging task, ie, Fine-grained Human-body Abnormality Detection (FHAD), and construct two high-quality datasets for evaluation. Then, we propose a meticulous framework, named HumanCalibrator, which identifies and repairs abnormalities in human body structures while preserving the other content. Experiments indicate that our HumanCalibrator achieves high accuracy in abnormality detection and accomplishes an increase in visual comparisons while preserving the other visual content.
Framework


Experiment


Conclusion
In this paper, we propose HumanCalibrator, a fine-grained abnormal detection and repair framework in AIGC visual content with two datasets across different domains. It can detect abnormal body parts, and repair the abnormality while maintaining the other visual content. However, there are still limitations to our proposed framework, e.g. the predefined abnormal human body class limits the generalizability, the complex and circular framework limits its stability. In the future, we plan to extend our method to support more visual categories and types of abnormalities.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab