
Abstract
Diffusion models for garment-centric human generation from text or image prompts have garnered emerging attention for their great application potential. However, existing methods often face a dilemma: lightweight approaches, such as adapters, are prone to generate inconsistent textures; while finetune-based methods involve high training costs and struggle to maintain the generalization capabilities of pretrained diffusion models, limiting their performance across diverse scenarios. To address these challenges, we propose DreamFit, which incorporates a lightweight Anything-Dressing Encoder specifically tailored for the garment-centric human generation. DreamFit has three key advantages: (1) Lightweight training: with the proposed adaptive attention and LoRA modules, DreamFit significantly minimizes the model complexity to 83.4M trainable parameters. (2) Anything-Dressing: Our model generalizes surprisingly well to a wide range of (non-)garments, creative styles, and prompt instructions, consistently delivering high-quality results across diverse scenarios. (3) Plug-and-play: DreamFit is engineered for smooth integration with any community control plugins for diffusion models, ensuring easy compatibility and minimizing adoption barriers. To further enhance generation quality, DreamFit leverages pretrained large multi-modal models (LMMs) to enrich the prompt with fine-grained garment descriptions, thereby reducing the prompt gap between training and inference. We conduct comprehensive experiments on both 768 x 512 high-resolution benchmarks and in-the-wild images. DreamFit surpasses all existing methods, highlighting its state-of-the-art capabilities of garment-centric human generation.
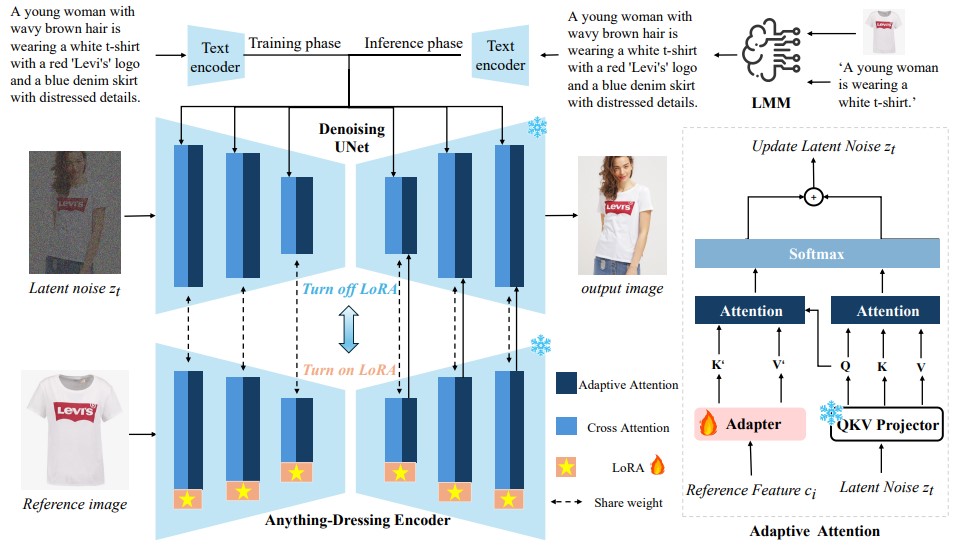
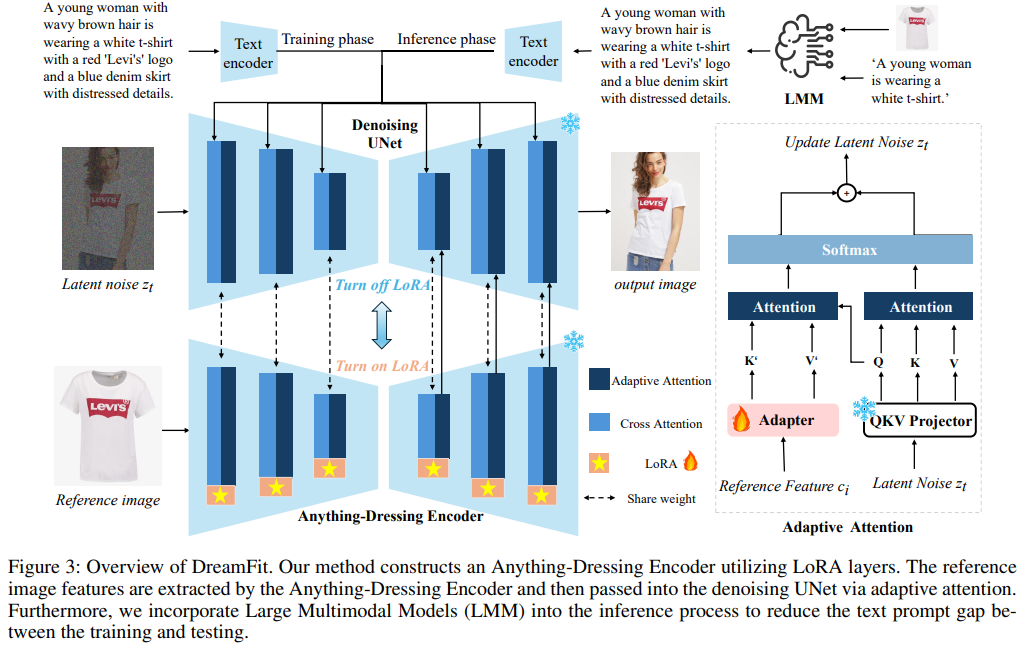
Framework
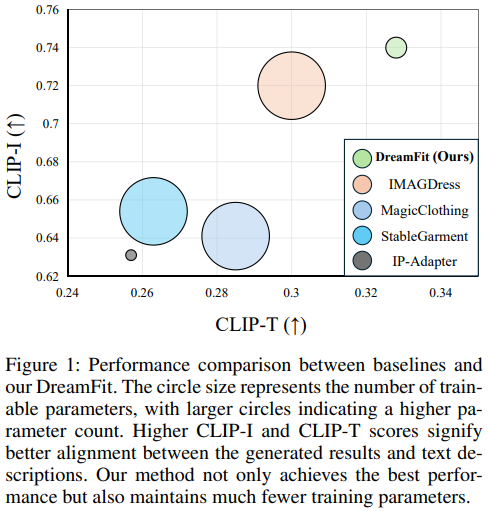

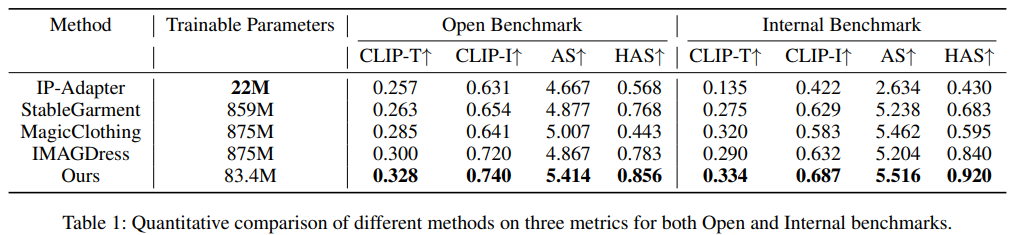
Experiment




Conclusion
In this paper, we introduced DreamFit, a novel garmentcentric human image generation framework designed to address the ineffciencies and limitations of existing methods. By leveraging a lightweight, plug-and-play AnythingDressing Encoder based on LoRA layers, DreamFit significantly streamlines model complexity and memory usage, facilitating more effcient and scalable training procedures. Our approach integrates large multi-modal models into the inference process, effectively reducing the domain gap between training and inference text prompts and enhancing the overall quality and consistency of the generated images. Extensive experiments conducted on open and internal benchmarks demonstrate that DreamFit not only achieves state-ofthe-art performance but also exhibits superior generalization capabilities across diverse scenarios.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab