
Abstract
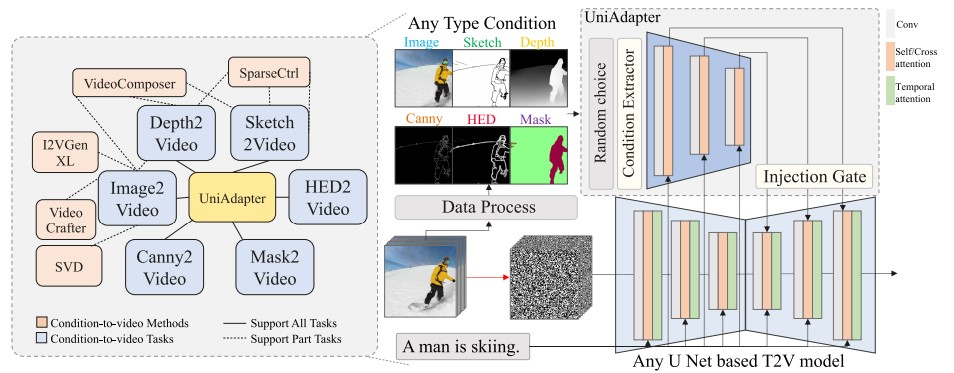
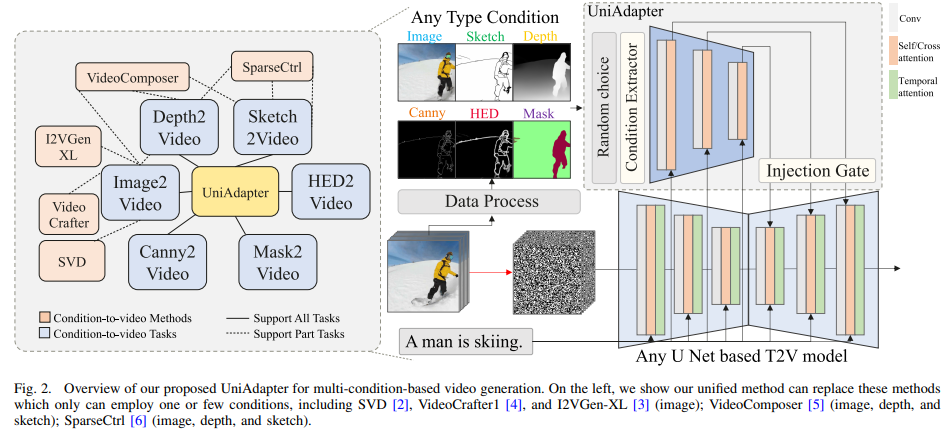
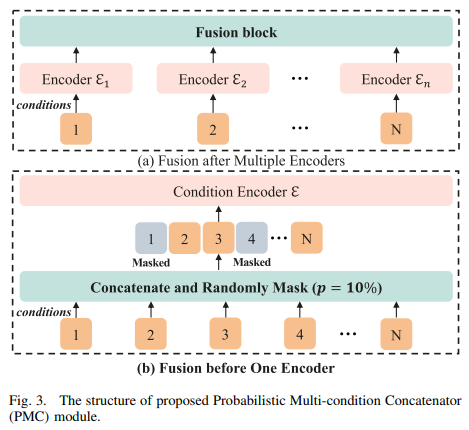
Condition-based video generation aims to create video content based on given information that describes specific subjects. However, most existing works can only utilize a single condition to guide the denoising process, thereby limiting their applicability to specific scenarios. Although some works attempt to accommodate multiple conditions within one framework, they often require multiple encoders, leading to inefficiencies in integrating multi-condition features. In this work, we present a framework that, with the support of the proposed Unified Adapter (UniAdapter), enables simultaneous multi-condition control of video generation within a single model. To effectively merge these conditions, we propose a novel Probabilistic Multi-condition Concatenator (PMC) module, which employs a unified encoder to accommodate multiple conditions and concatenate condition features at the pixel level to achieve fine-grained control. Following the PMC module, we employ 2D down-sampling blocks to refine features for injection into the Video Diffusion Model (VDM). Moreover, our UniAdapter is designed to be model-agnostic and compatible with any U-Net-based VDM, offering a versatile solution for improving video generation quality. Experimental results on public benchmarks UCF-101 and MSR-VTT show that our method achieves superior results in both quantitative and qualitative evaluations.
Framework

Experiment


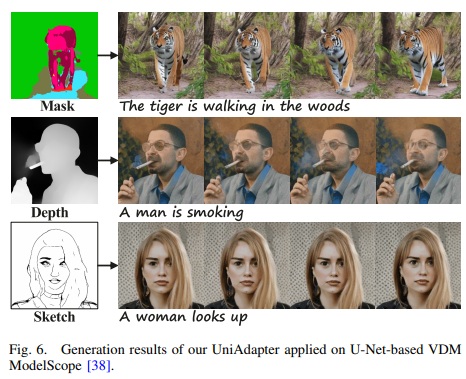





Conclusion
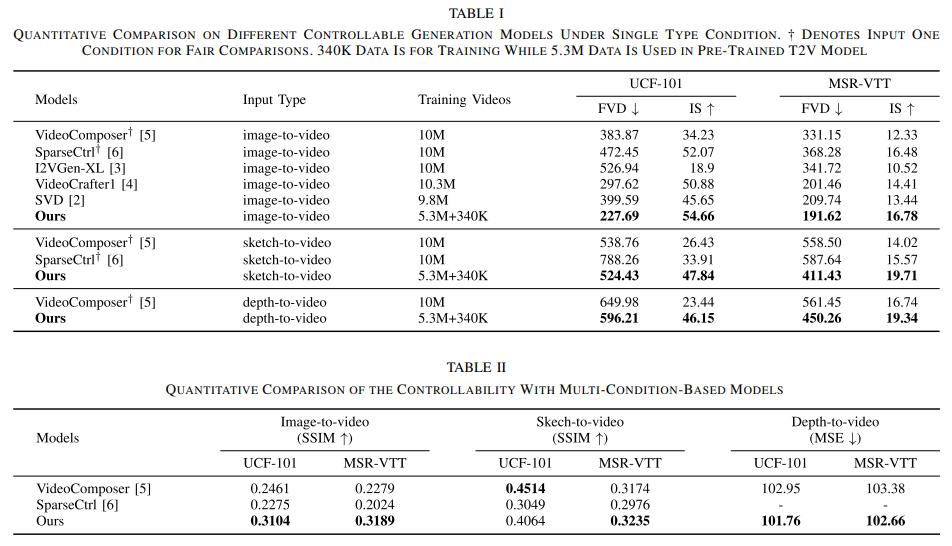
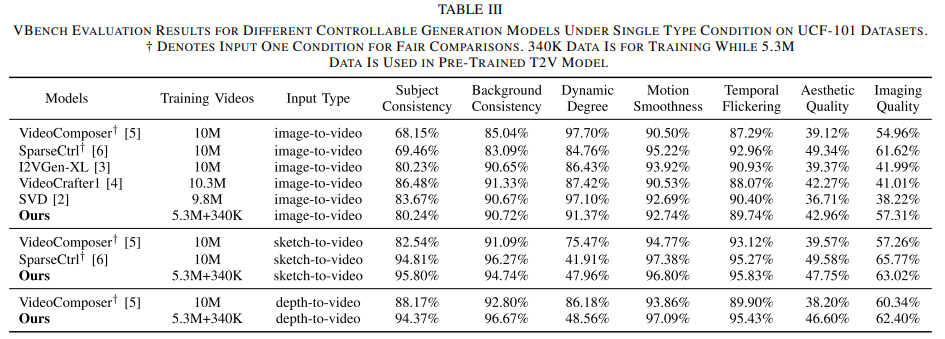
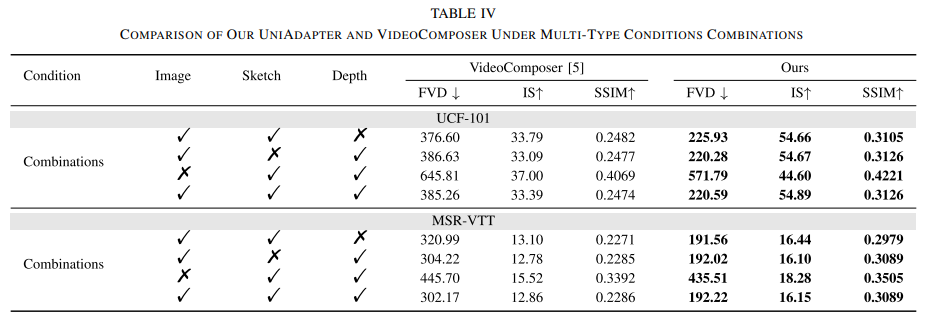
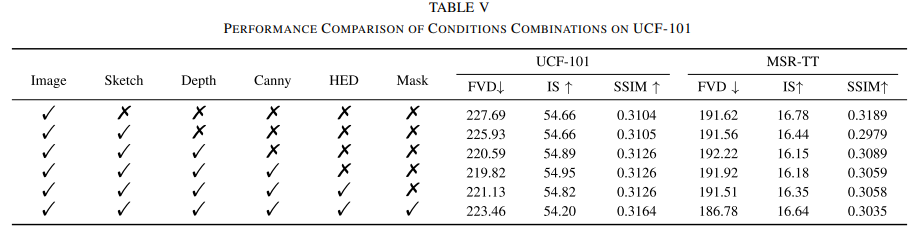
We propose a Unified Adapter (UniAdapter) to enhance high-quality video generation by controlling multiple conditions during the denoising process. UniAdapter integrates six general conditions—Image, Depth, Sketch, HED, Mask, and Canny. To effectively merge all conditions, we introduce a novel Probabilistic Multi-condition Concatenator (PMC) module. The fused condition features are then processed through a series of 2D down-sampling blocks to extract fine-grained details, which are subsequently injected into the Video Diffusion Model (VDM). Notably, UniAdapter is model-agnostic and can be seamlessly integrated with any U-Net-based VDM. We validate our method on UCF-101 and MSR-VTT benchmarks and the results exhibit superior performance in both quantitative and qualitative evaluations.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab