
Abstract
Driven by recent computer vision and robotic applications, recovering 3D human poses has become increasingly important and attracted growing interests. In fact, completing this task is quite challenging due to the diverse appearances, viewpoints, occlusions and inherently geometric ambiguities inside monocular images. Most of the existing methods focus on designing some elaborate priors /constraints to directly regress 3D human poses based on the corresponding 2D human pose-aware features or 2D pose predictions. However, due to the insufficient 3D pose data for training and the domain gap between 2D space and 3D space, these methods have limited scalabilities for all practical scenarios (e.g., outdoor scene). Attempt to address this issue, this paper proposes a simple yet effective self-supervised correction mechanism to learn all intrinsic structures of human poses from abundant images. Specifically, the proposed mechanism involves two dual learning tasks, i.e., the 2D-to-3D pose transformation and 3D-to-2D pose projection, to serve as a bridge between 3D and 2D human poses in a type of “free” self-supervision for accurate 3D human pose estimation. The 2D-to-3D pose implies to sequentially regress intermediate 3D poses by transforming the pose representation from the 2D domain to the 3D domain under the sequence-dependent temporal context, while the 3D-to-2D pose projection contributes to refining the intermediate 3D poses by maintaining geometric consistency between the 2D projections of 3D poses and the estimated 2D poses. Therefore, these two dual learning tasks enable our model to adaptively learn from 3D human pose data and external large-scale 2D human pose data. We further apply our self-supervised correction mechanism to develop a 3D human pose machine, which jointly integrates the 2D spatial relationship, temporal smoothness of predictions and 3D geometric knowledge. Extensive evaluations on the Human3.6M and HumanEva-I benchmarks demonstrate the superior performance and efficiency of our framework over all the compared competing methods.
Motivation
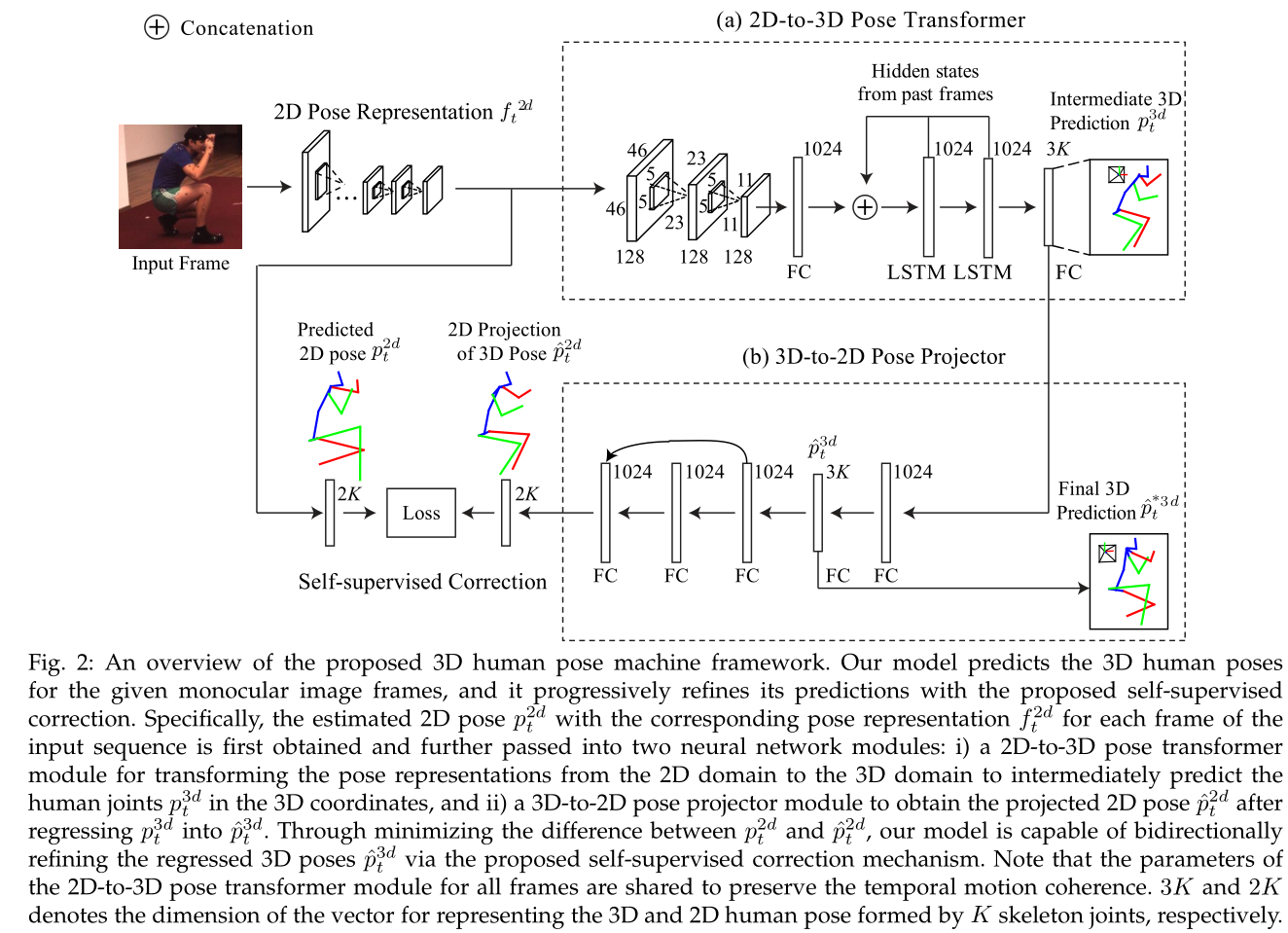
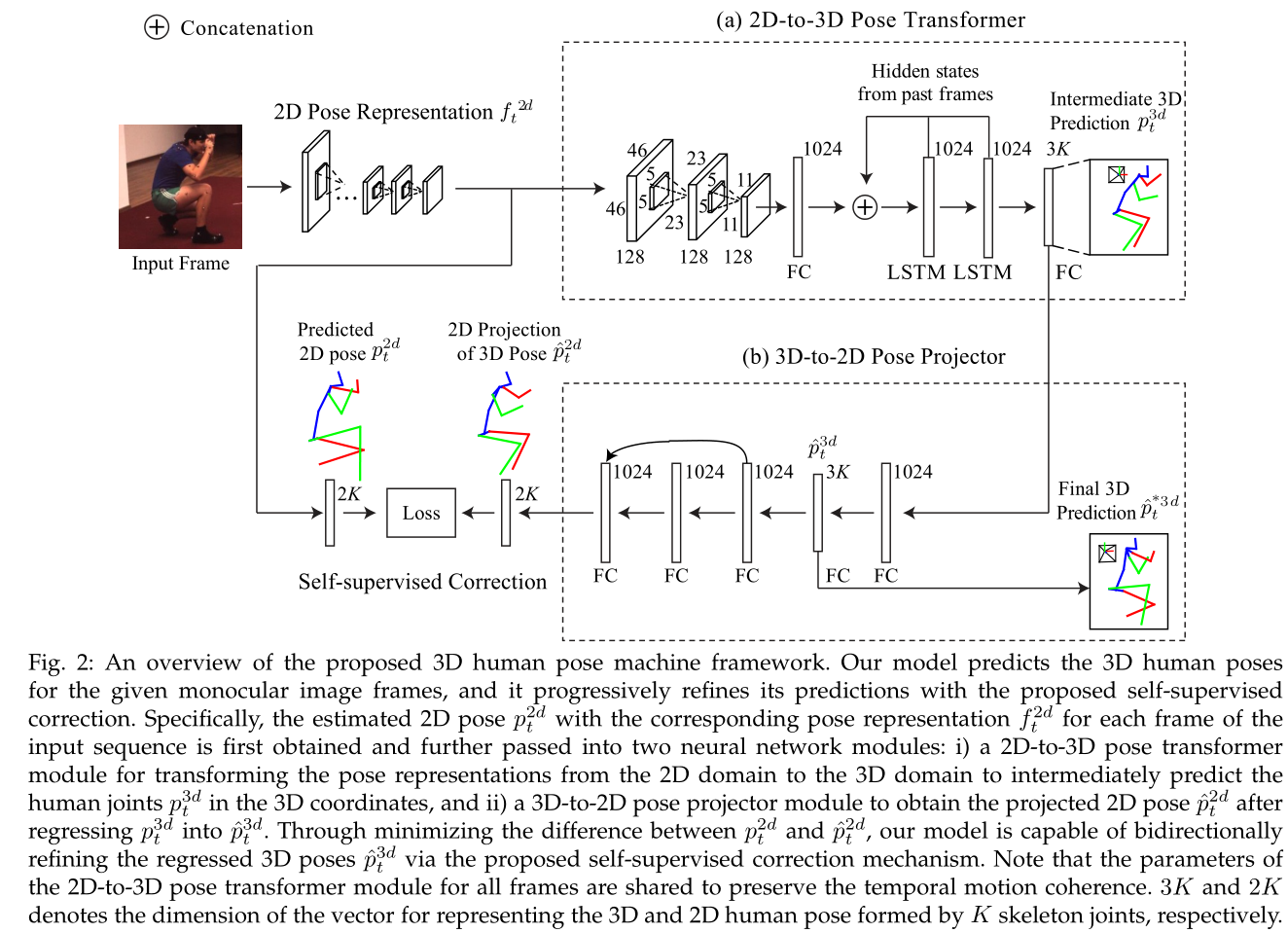
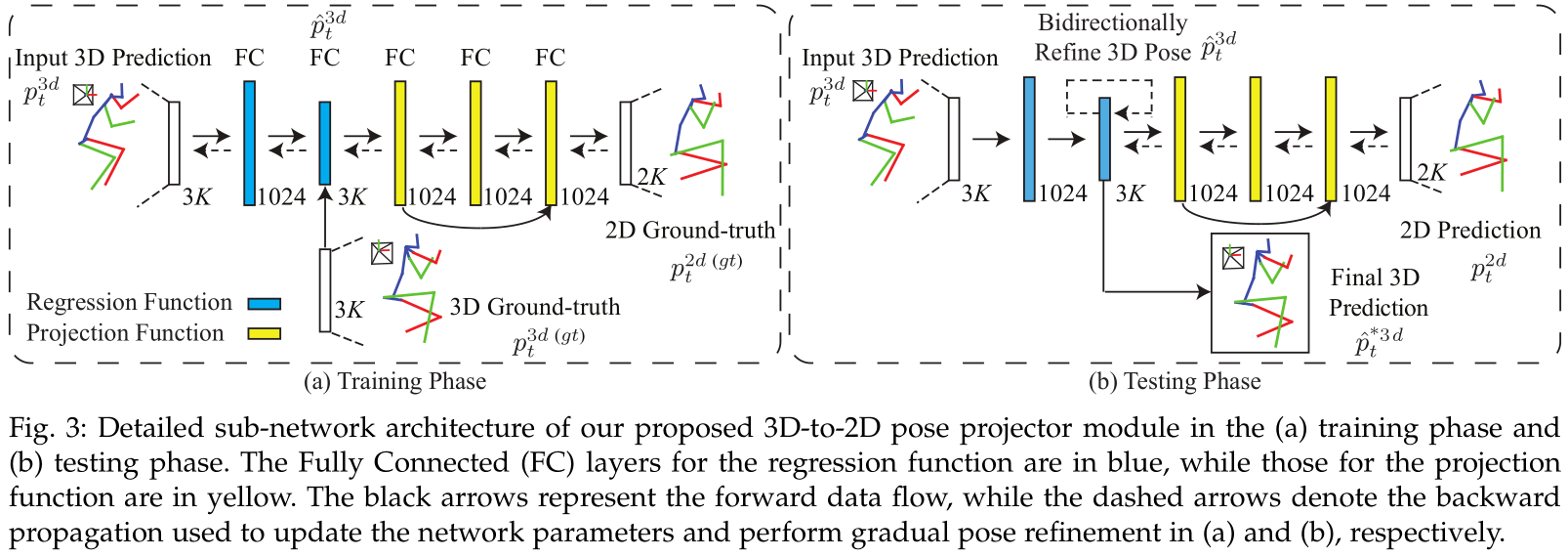
To address the remaining issues of 3D human pose estimation and utilize the sufficient 2D pose data for training, we propose an effective yet efficient 3D human pose estimation framework, which implicitly learns to integrate the 2D spatial relationship, temporal coherency and 3D geometry knowledge by utilizing the advantages afforded by Convolutional Neural Networks (CNNs) (i.e., the ability to learn feature representations for both image and spatial context directly from data), recurrent neural networks (RNNs) (i.e., the ability to model the temporal dependency and prediction smoothness) and the self-supervised correction (i.e., the ability to implicitly retain 3D geometric consistency between the 2D projections of 3D poses and the predicted 2D poses). Concretely, our model employs a sequential training to capture long-range temporal coherency among multiple human body parts, and it is further enhanced via a novel self-supervised correction mechanism, which involves two dual learning tasks, i.e., 2D-to-3D pose transformation and 3D-to-2D pose projection, to generate geometrically consistent 3D pose predictions under a self-supervised correction mechanism, i.e., forcing the 2D projections of the generated 3D poses to be identical to the estimated 2D poses.
Methodology
We propose a 3D human pose machine to resolve 3D pose sequence generation for monocular frames, and we introduce a concise self-supervised correction mechanism to enhance our model by retaining the 3D geometric consistency. After extracting the 2D pose representation and estimating the 2D poses for each frame via a common 2D pose sub-network, our model employs two consecutive modules. The first module is the 2D-to-3D pose transformer module for transforming the 2D pose-aware features from the 2D domain to the 3D domain. This module is designed to estimate intermediate 3D poses for each frame by incorporating temporal dependency in the image sequence. The second module is the 3D-to-2D pose projector module for bidirectionally refining the intermediate 3D pose prediction via our introduced self-supervised correction mechanism. These two modules are combined in a unified framework to be optimized in a fully end-to-end manner.
Comparison Results
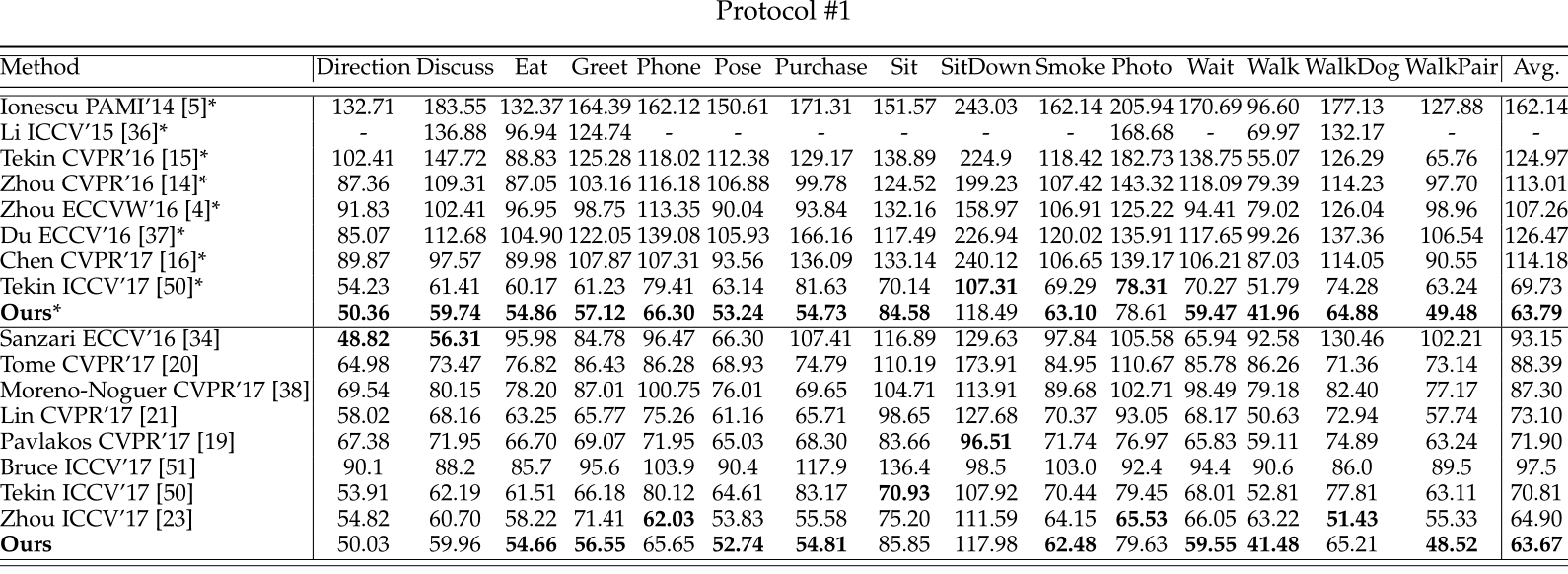
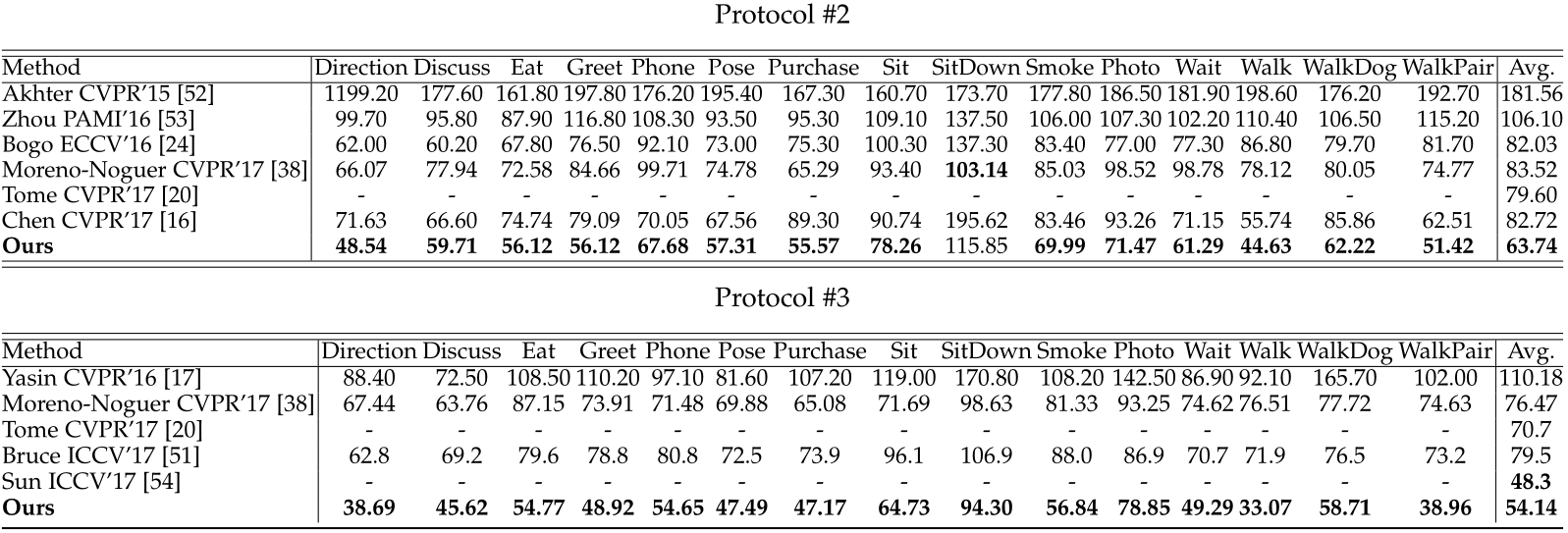
Quantitative and qualitative comparisons on the Human3.6M dataset using 3D pose errors (in millimeters). The entries with the smallest 3D pose errors for each category are bold-faced. A method with “*” denotes that it is individually trained on each action category. Our model achieves a significant improvement over all compared approaches.

Conclusion
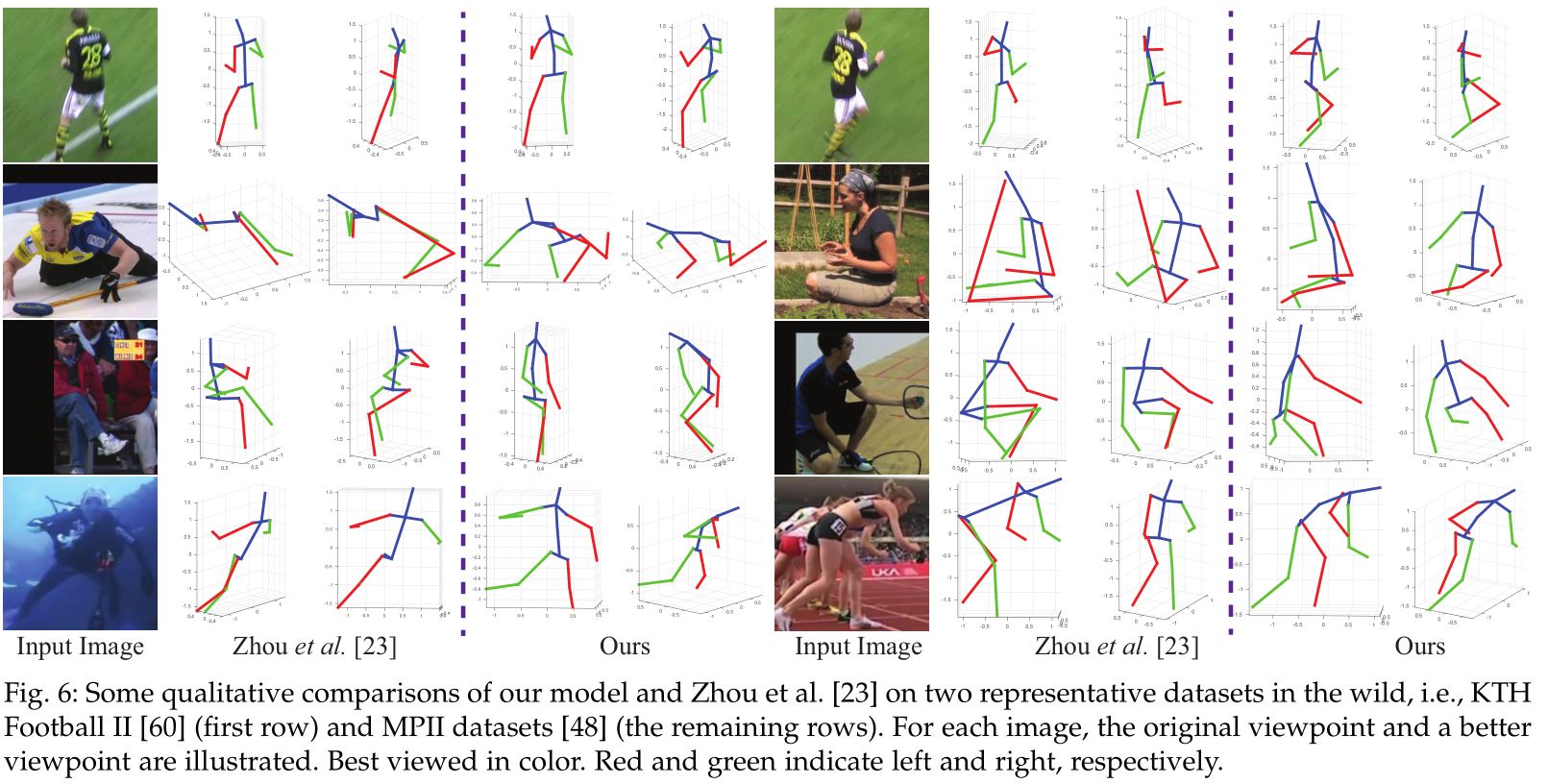
This paper presented a 3D human pose machine that can learn to integrate rich spatio-temporal long-range dependencies and 3D geometry knowledge in an implicit and comprehensive manner. We further enhanced our model by developing a novel self-supervised correction mechanism, which involves two dual learning tasks, i.e., 2D-to-3D pose transformation and 3D-to-2D pose projection, under a self-supervised correction mechanism. This mechanism retains the geometric consistency between the 2D projections of 3D poses and the estimated 2D poses, and it enables our model to utilize the estimated 2D human pose to bidirectionally refine the intermediate 3D pose estimation. Therefore, our proposed self-supervised correction mechanism can bridge the domain gap between 3D and 2D human poses to leverage the external 2D human pose data without requiring additional 3D annotations. Extensive evaluations on two public 3D human pose datasets validate the effectiveness and superiority of our proposed model. In future work, focusing on sequence-based human centric analyses (e.g., human action and activity recognition), we will extend our proposed self-supervised correction mechanism for temporal relationship modeling, and design new self-supervision objectives to incorporating abundant 3D geometric knowledge for training models in a cost-effective manner.
Acknowledgement
We would like to thank Mude Lin and Xiandan Liang for their preliminary contributions on this project.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab