
Abstract
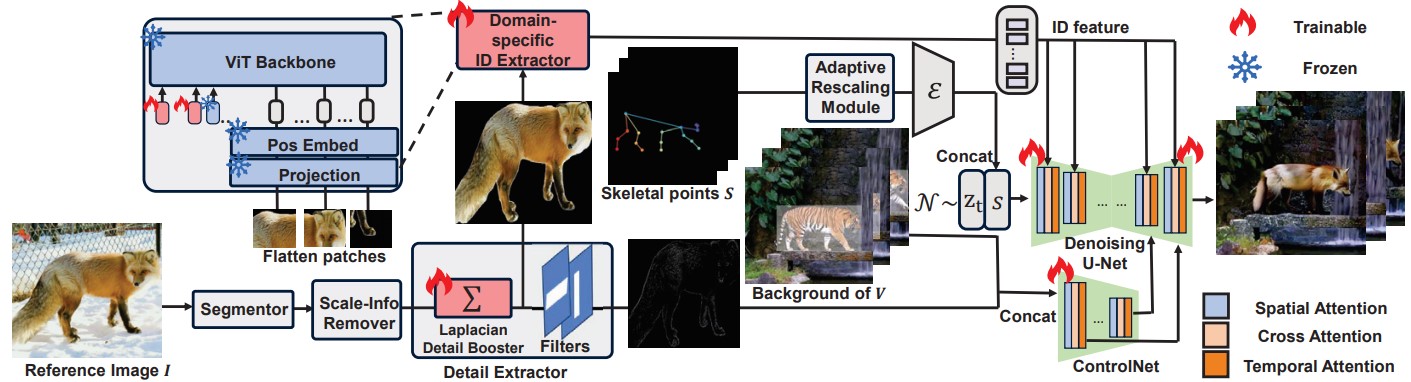
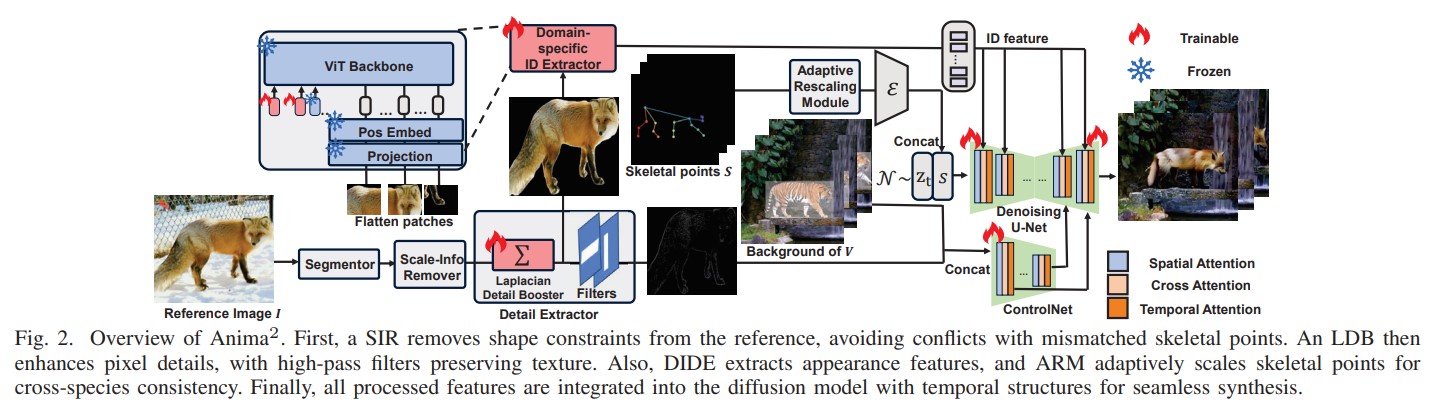
Recent video editing advancements rely on accurate pose sequences to animate human actors. However, these efforts are not suitable for cross-species animation due to pose misalignment between species (for example, the poses of a cat differ greatly from that of a pig due to their distinct body structures). In this paper, we present Anima2, a zero-shot diffusion-based video generator to address this issue, aiming to accurately ANIMAte ANIMAls while preserving the background. The key technique involves two-fold subject alignment. First, we improve appearance feature extraction by integrating a Laplacian detail booster and a prompt-tuning identity extractor. They capture essential appearance information, including identity and fine details. Second, we align shape features and address conflicts from differing animals by introducing a scale-information remover and an adaptive rescaling module. They both enhance subject alignment for accurate cross-species animation. Additionally, we introduce two high-quality animal video datasets with diverse species to benchmark cross-species animation. Trained on these extensive datasets, our model directly generates videos with accurate movements, consistent appearances, and high-fidelity frames, eliminating the need for test-time training. Extensive experiments demonstrate our method’s superiority in cross-species animation, showcasing robust adaptability and generality.
Framework




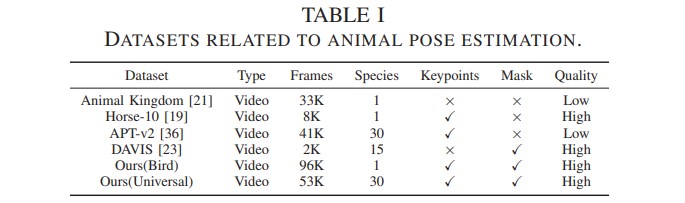
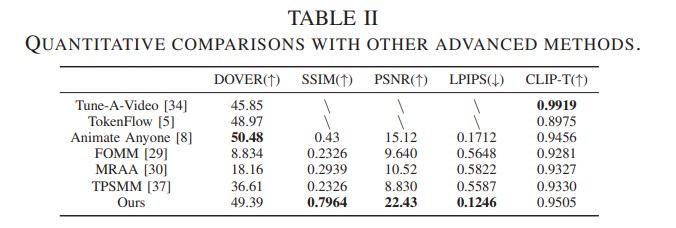
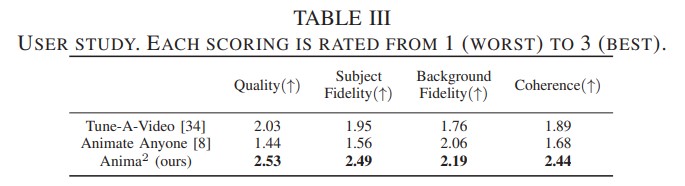
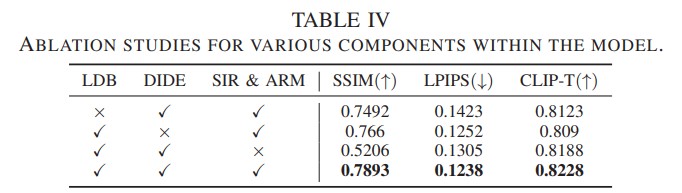
Experiment


Conclusion
In this study, we introduce Anima2, a cross-species animation framework. Our approach features subject alignment with four key components: LDB and DIDE for appearance extraction, and SIR and ARM to prevent shape information leakage, ensuring consistent training and precise action control. It also showcases robust adaptability and generality.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab