
Abstract
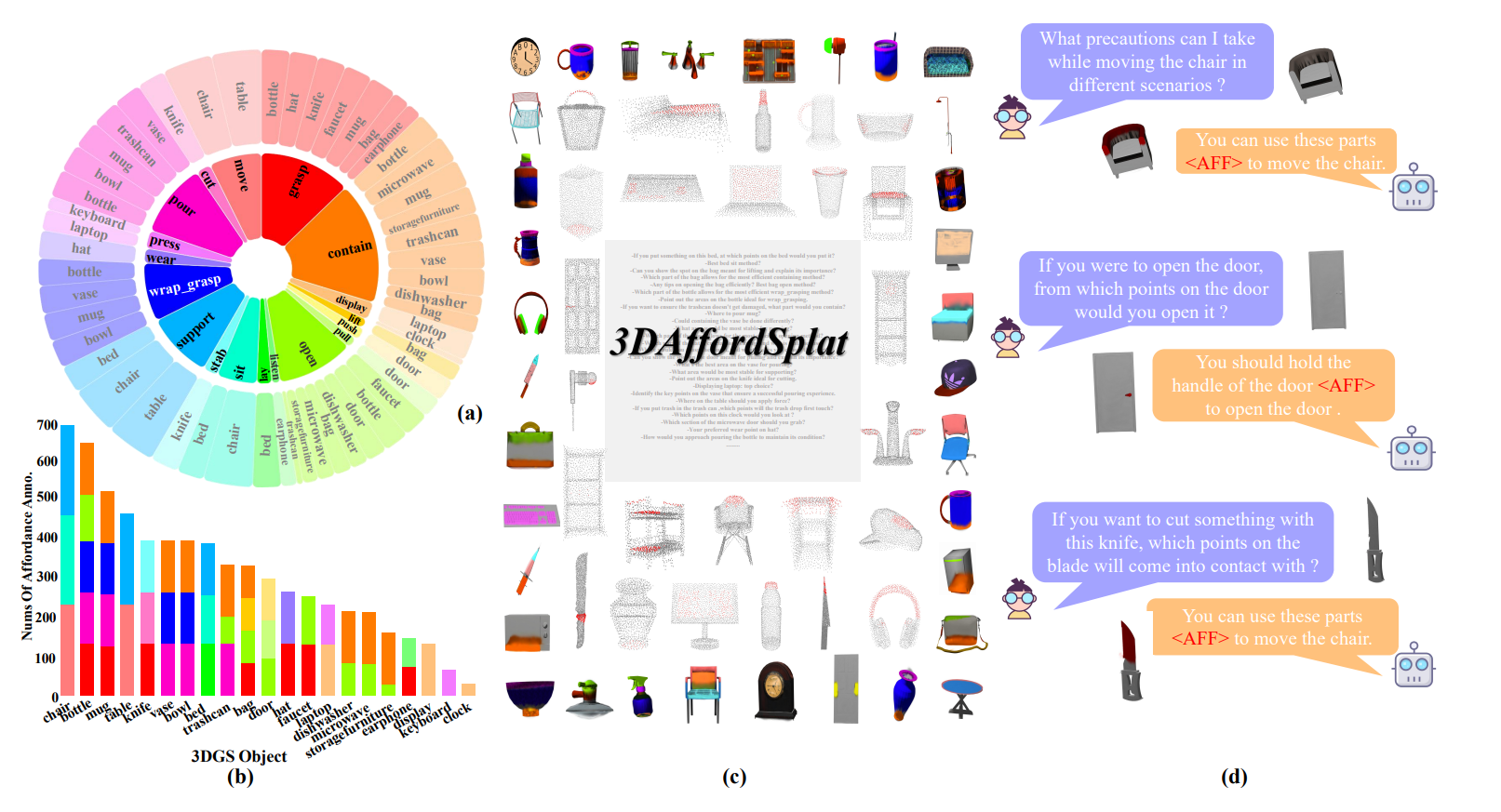
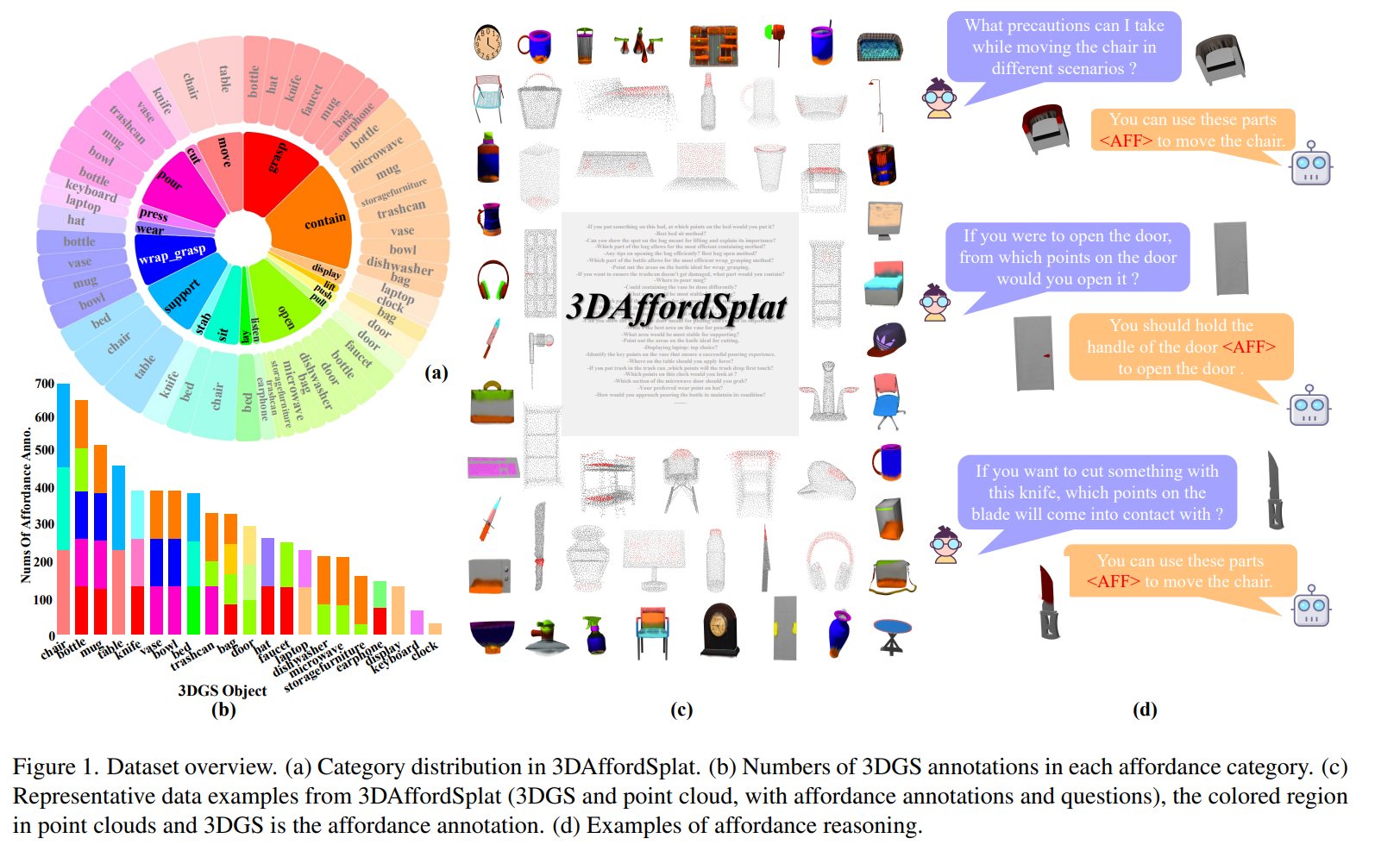
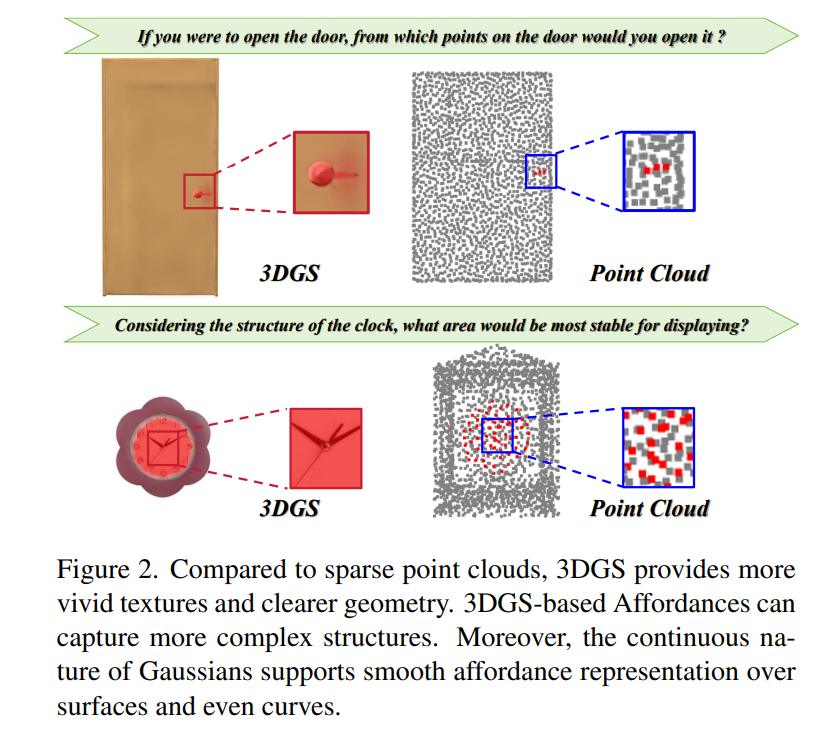
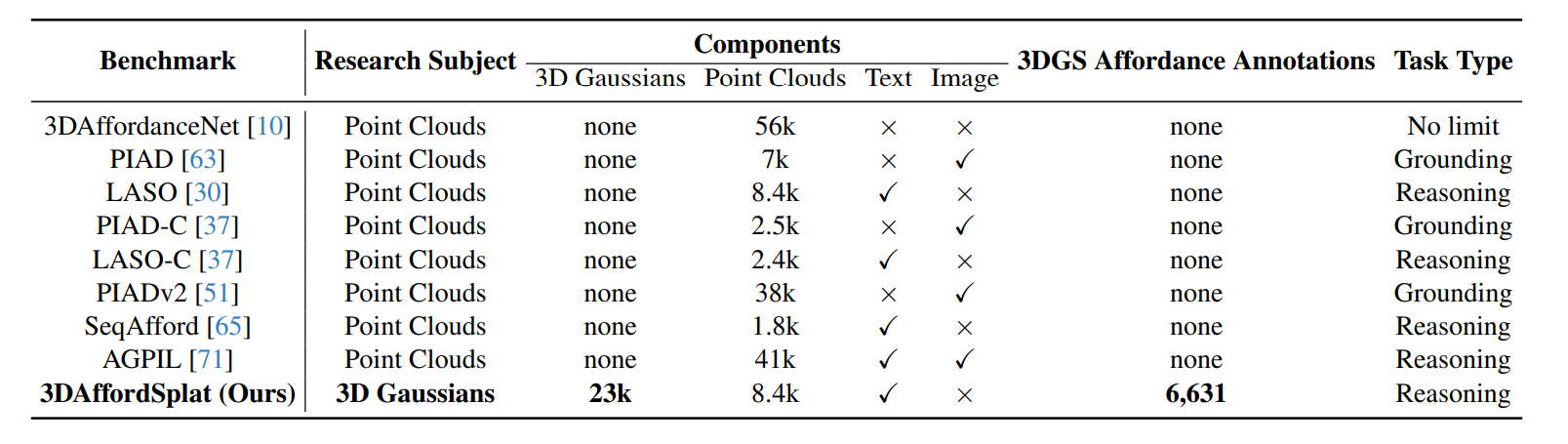
3D affordance reasoning is essential in associating human instructions with the functional regions of 3D objects, facilitating precise, task-oriented manipulations in embodied AI. However, current methods, which predominantly depend on sparse 3D point clouds, exhibit limited generalizability and robustness due to their sensitivity to coordinate variations and the inherent sparsity of the data. By contrast, 3D Gaussian Splatting (3DGS) delivers high-fidelity, real-time rendering with minimal computational overhead by representing scenes as dense, continuous distributions. This positions 3DGS as a highly effective approach for capturing fine-grained affordance details and improving recognition accuracy. Nevertheless, its full potential remains largely untapped due to the absence of large-scale, 3DGS-specific affordance datasets. To overcome these limitations, we present 3DAffordSplat, the first large-scale, multi-modal dataset tailored for 3DGS-based affordance reasoning. This dataset includes 23,677 Gaussian instances, 8,354 point cloud instances, and 6,631 manually annotated affordance labels, encompassing 21 object categories and 18 affordance types. Building upon this dataset, we introduce AffordSplatNet, a novel model specifically designed for affordance reasoning using 3DGS representations. AffordSplatNet features an innovative cross-modal structure alignment module that exploits structural consistency priors to align 3D point cloud and 3DGS representations, resulting in enhanced affordance recognition accuracy. Extensive experiments demonstrate that the 3DAffordSplat dataset significantly advances affordance learning within the 3DGS domain, while AffordSplatNet consistently outperforms existing methods across both seen and unseen settings, highlighting its robust generalization capabilities.
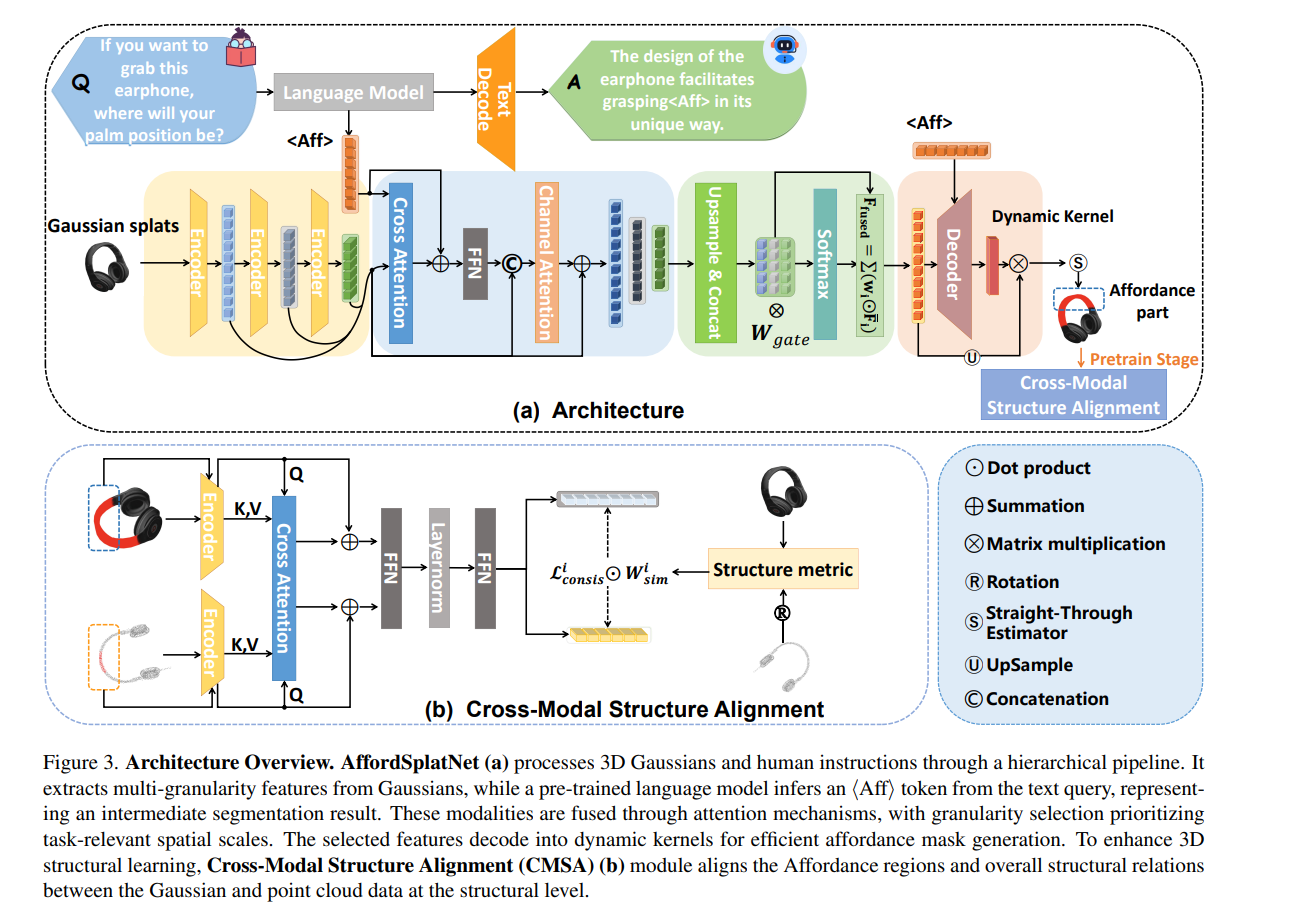
Framework
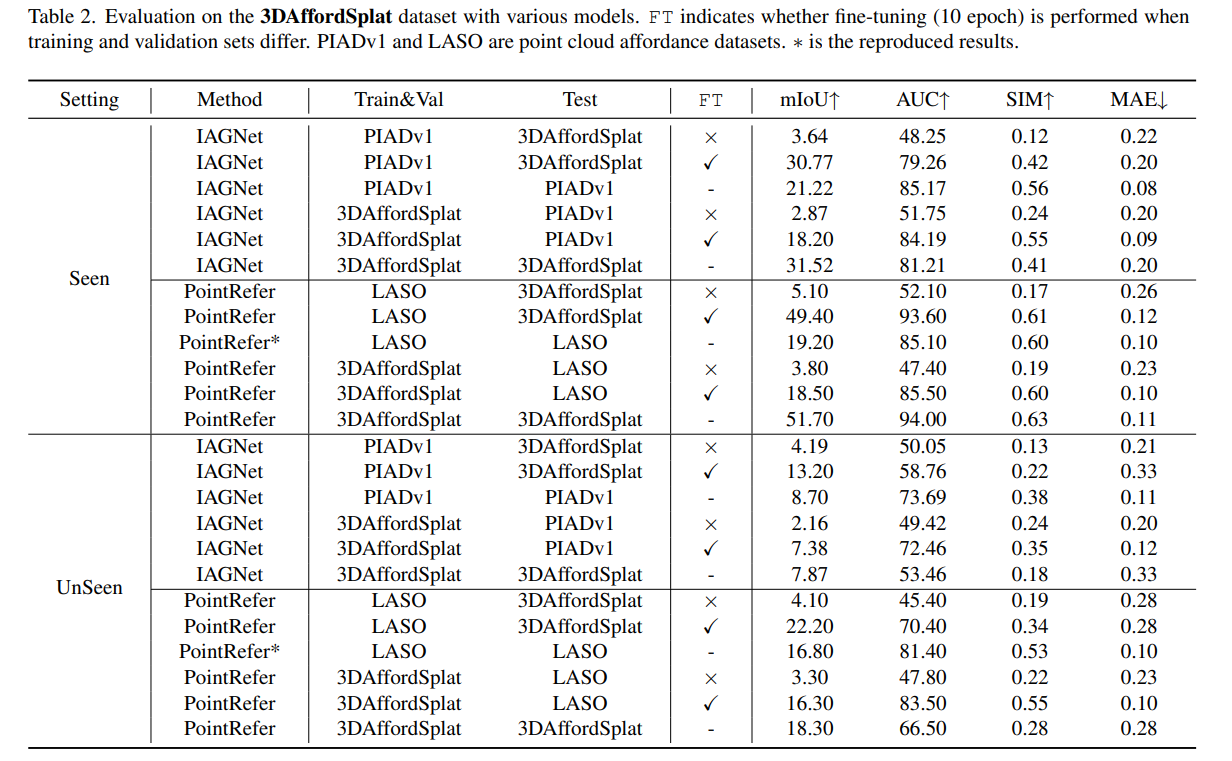
Experiment
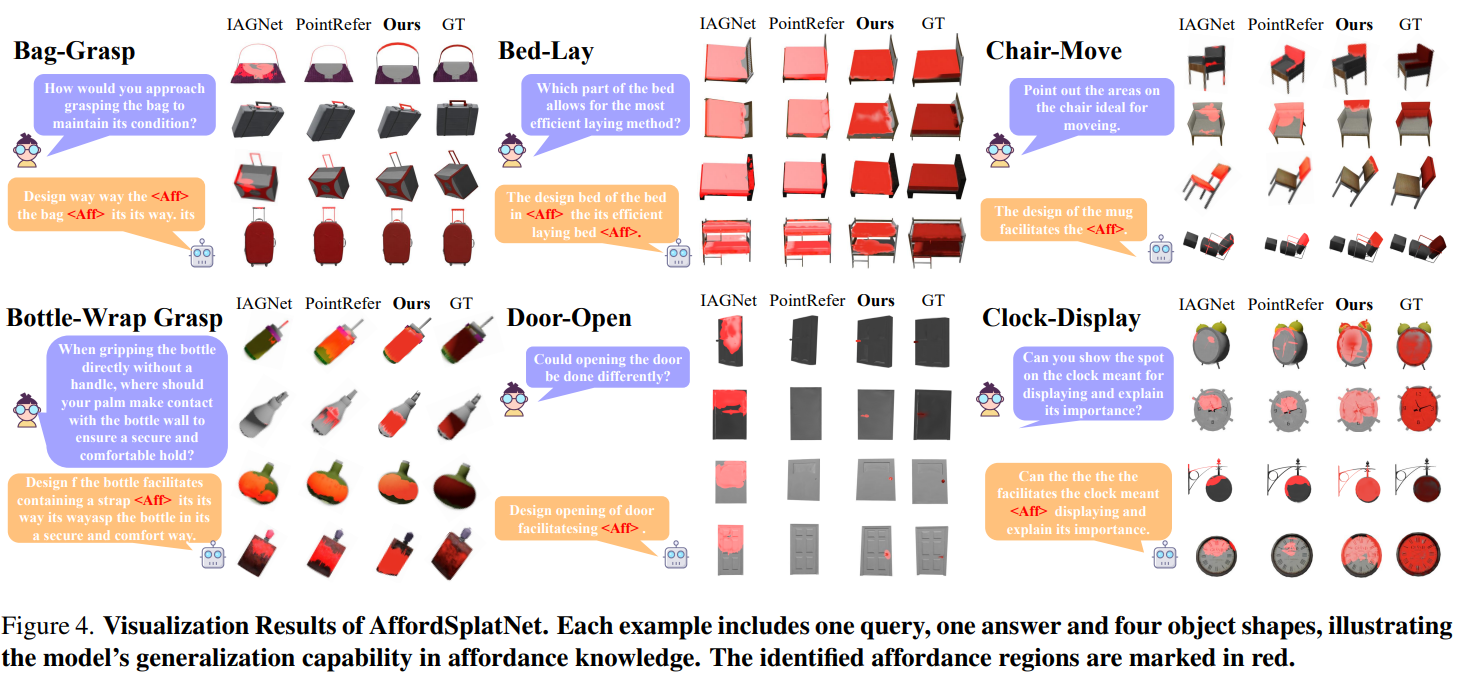

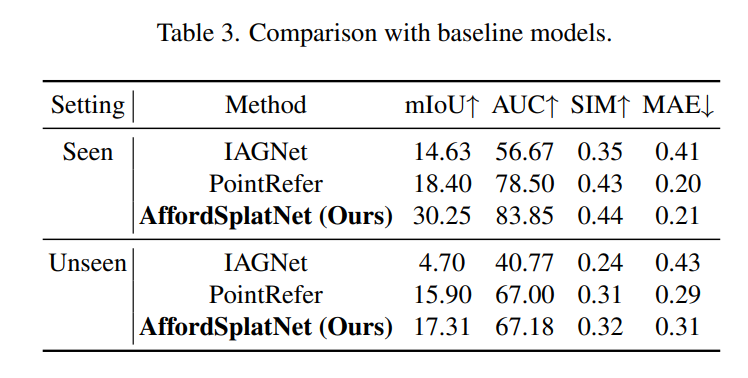
Conclusion
In this work, we introduce 3DAffordSplat, the first large-scale, multi-modal affordance dataset specifically designed for 3DGS, which provides rich annotations across diverse object categories and affordance types. Based on this dataset, we propose AffordSplatNet, a novel 3DGS affordance reasoning model. By incorporating a cross-modal structure alignment module, our model effectively bridges the gap between point-cloud and 3DGS, yielding more accurate and robust affordance recognition. Extensive experiments demonstrate the superiority of our dataset and model, with significant improvements over existing baselines and strong generalization to unseen scenarios. In future work, we will explore integrating our affordance reasoning framework into embodied robots to physically interact with objects in dynamic environments.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab