
Abstract
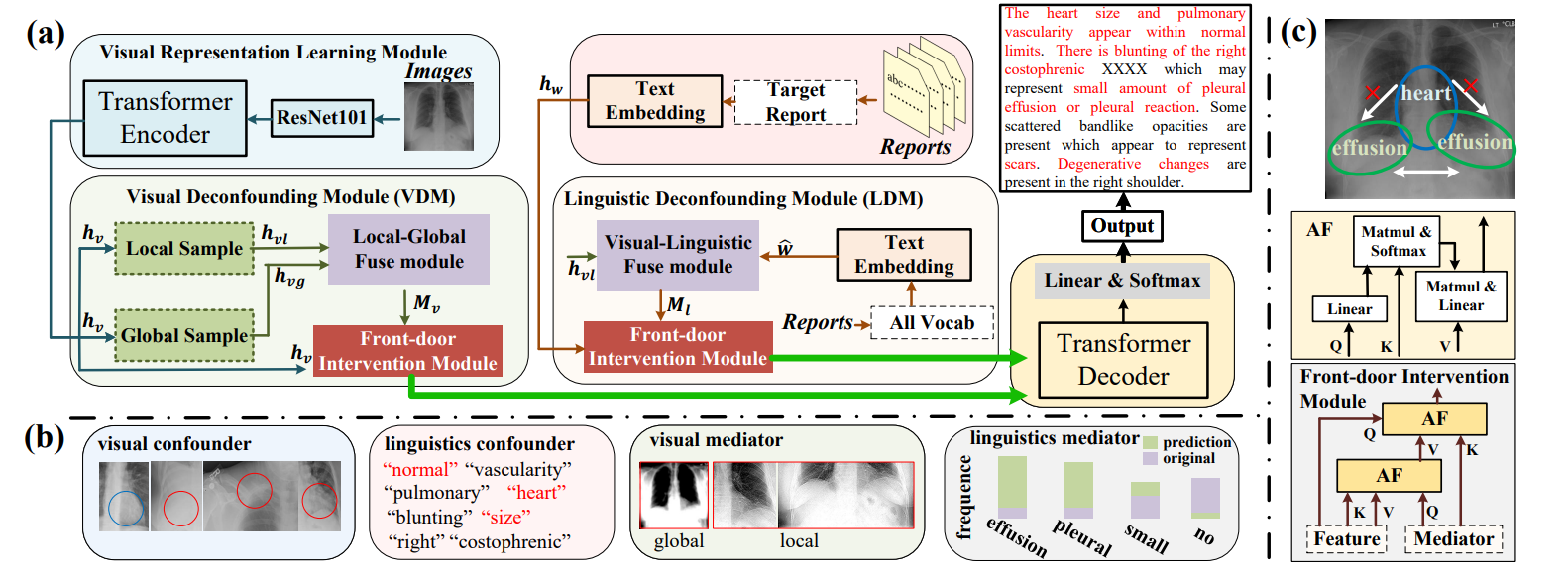
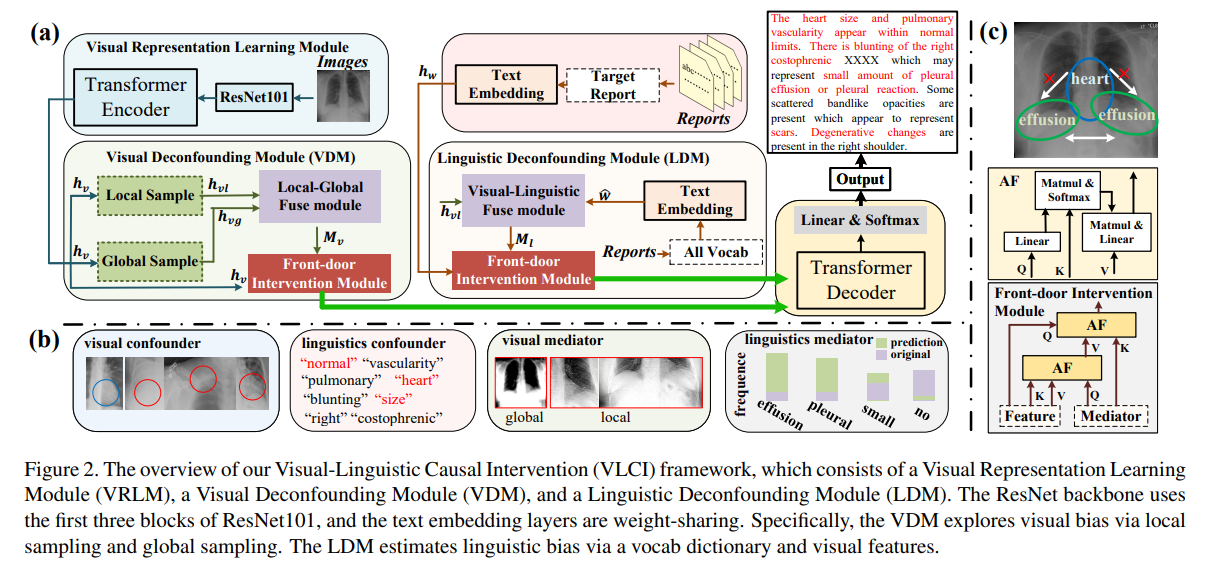
Radiology Report Generation (RRG) is essential for computer-aided diagnosis and medication guidance, which can relieve the heavy burden of radiologists by automatically generating the corresponding radiology reports according to the given radiology image. However, generating accurate lesion descriptions remains challenging due to spurious correlations from visual-linguistic biases and inherent limitations of radiological imaging, such as low resolution and noise interference. To address these issues, we propose a two-stage framework named Cross-Modal Causal Representation Learning (CMCRL), consisting of the Radiological Cross-modal Alignment and Reconstruction Enhanced (RadCARE) pre-training and the Visual-Linguistic Causal Intervention (VLCI) fine-tuning. In the pre-training stage, RadCARE introduces a degradation-aware masked image restoration strategy tailored for radiological images, which reconstructs high-resolution patches from low-resolution inputs to mitigate noise and detail loss. Combined with a multiway architecture and four adaptive training strategies (e.g., text postfix generation with degraded images and text prefixes), RadCARE establishes robust cross-modal correlations even with incomplete data. In the VLCI phase, we deploy causal front-door intervention through two modules: the Visual Deconfounding Module (VDM) disentangles local-global features without fine-grained annotations, while the Linguistic Deconfounding Module (LDM) eliminates context bias without external terminology databases. Experiments on IU-Xray and MIMIC-CXR show that our CMCRL pipeline significantly outperforms state-of-the-art methods, with ablation studies confirming the necessity of both stages. Code and models are available at https://github.com/WissingChen/CMCRL.
Framework
Experiment

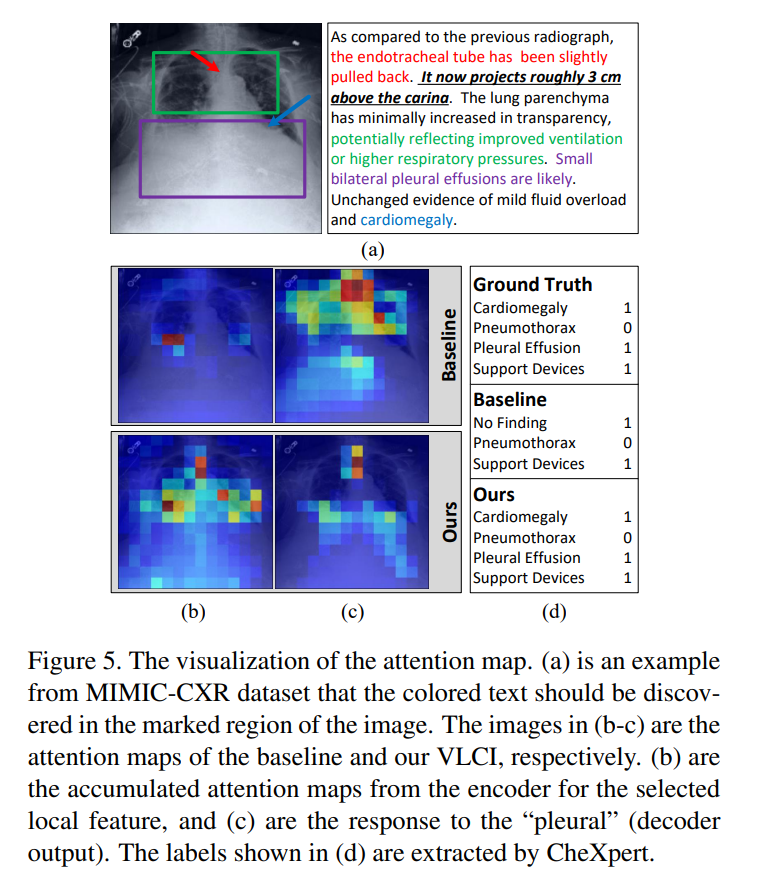
Conclusion
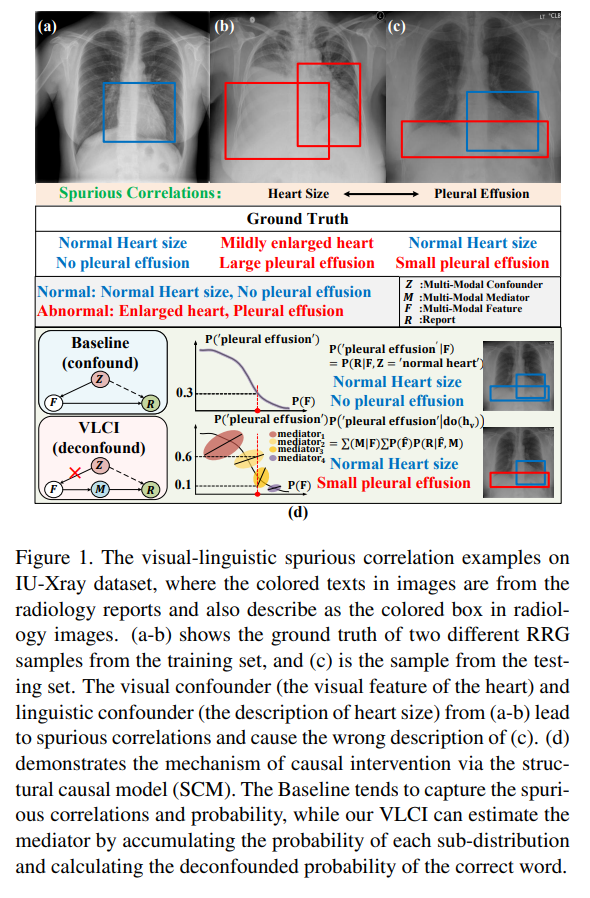
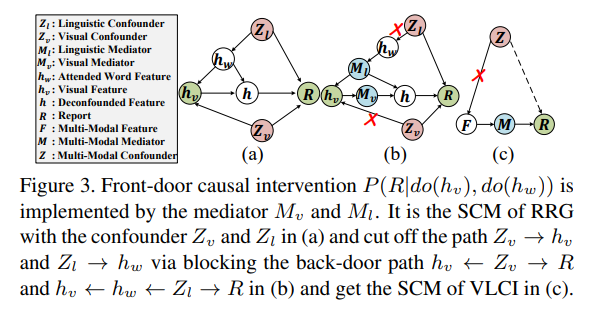
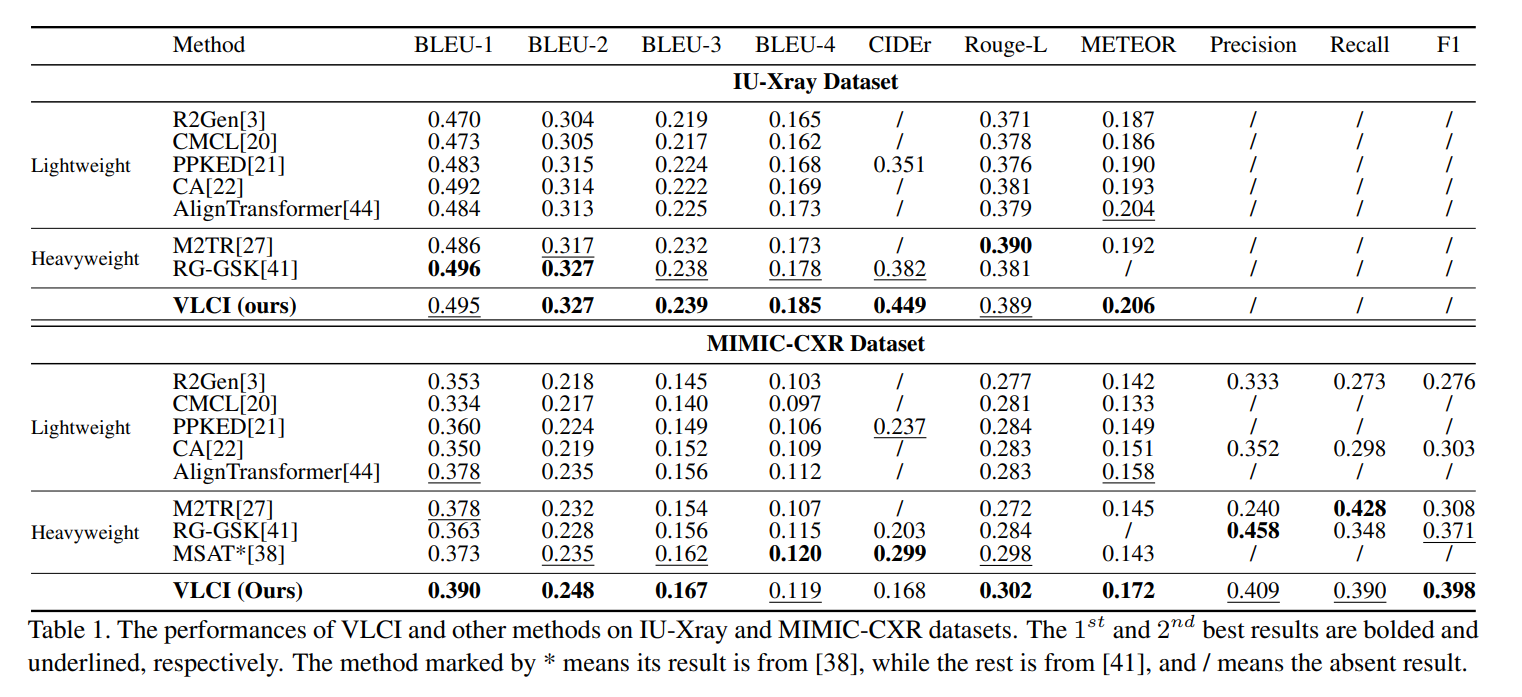
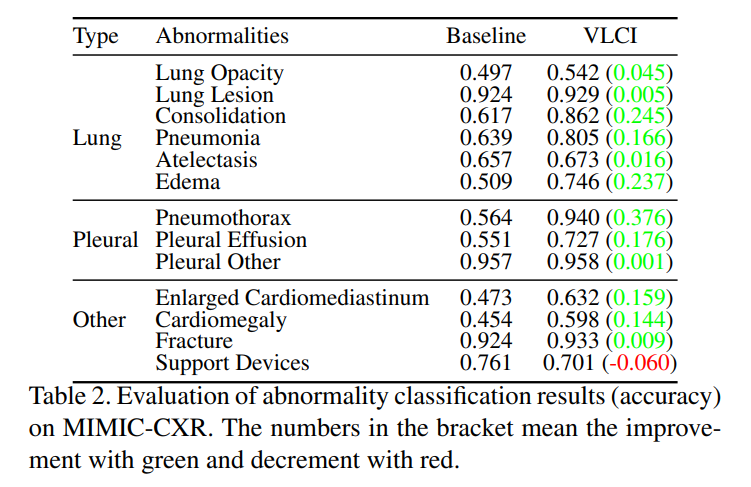
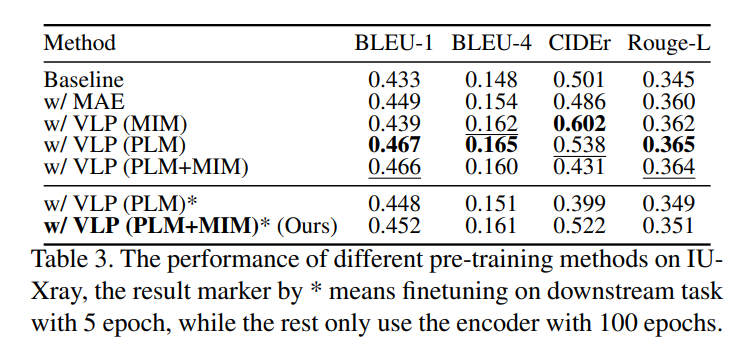
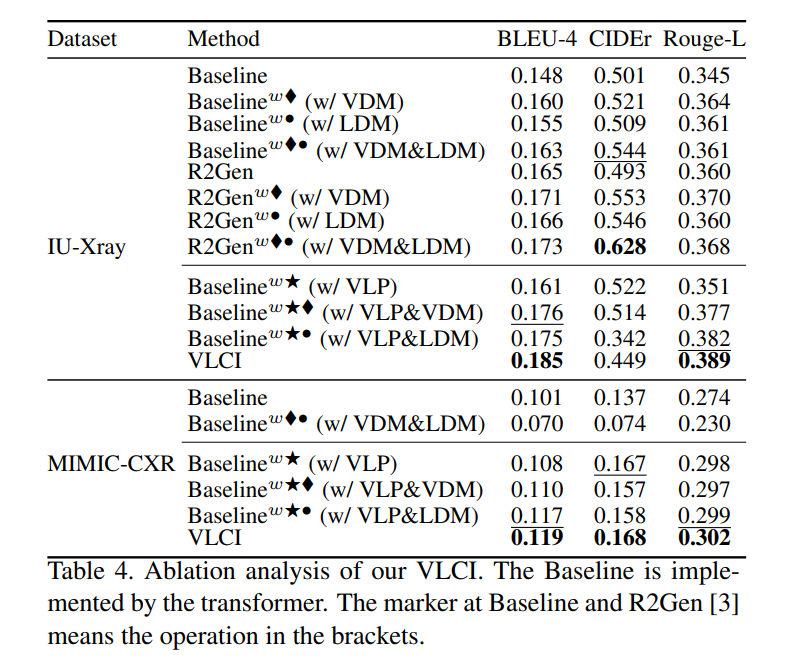
In this paper, we propose Visual-Linguistic Causal Intervention (VLCI) framework for RRG, to implicitly deconfound the visual-linguistic confounder by causal front-door intervention. To alleviate the problem of unpaired visuallinguistic data when pre-training, we combine the PLM and MIM for cross-modal pre-training. To implicitly mitigate cross-modal confounders and discover the true cross-modal causality, we propose visual-linguistic causal front-door intervention modules VDM and LDM. Experiments on IUXray and MIMIC-CXR datasets show that our VLCI can effectively mitigate visual-linguistic bias and outperforms the state-of-the-art methods. The lower computational cost and faster inference speed of VLCI promote its clinical application. We believe our work could inspire more causal reasoning methods in medical report generation.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab