
Abstract
Image-to-video generation, which aims to generate a video starting from a given reference image, has drawn great attention. Existing methods frequently integrate semantic information from images or simply concatenate images, which often leads to low fidelity and flickering in the generated videos. To tackle these problems, we propose a high-fidelity image-to-video generation method by devising a frame retention branch based on a pre-trained video diffusion model, named DreamVideo. Our DreamVideo perceives the reference image via convolution layers and concatenates the features with the noisy latents as model input. By this means, the details of the reference image can be preserved to the greatest extent. In addition, by incorporating the designed double-condition classifier-free guidance, DreamVideo can generate high-quality videos of different actions by providing varying prompt texts. We conduct comprehensive experiments on the public datasets, and both quantitative and qualitative results indicate that our method outperforms the state-of-the-art method.
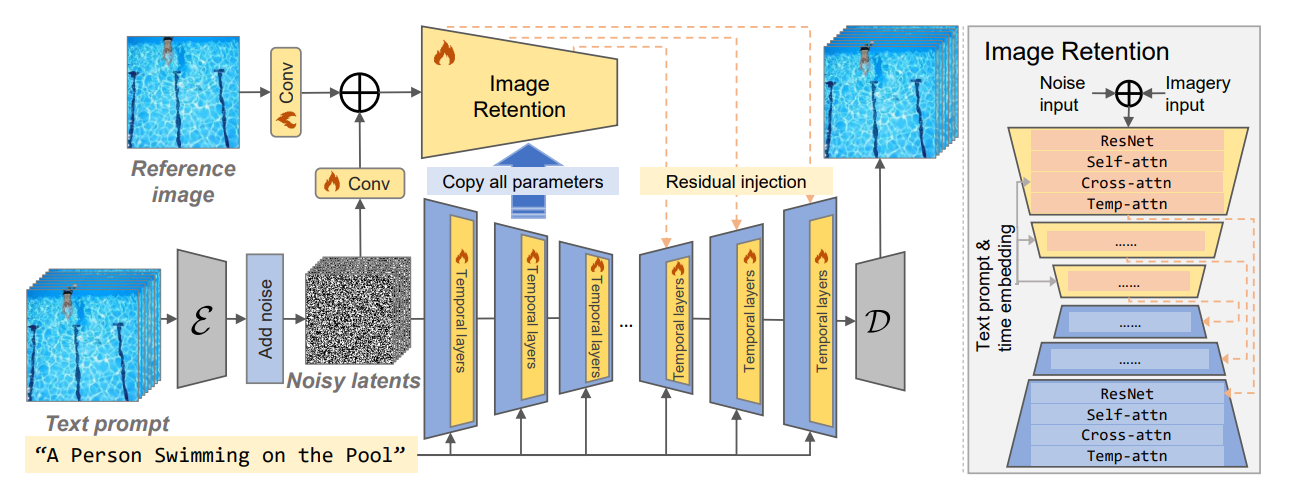
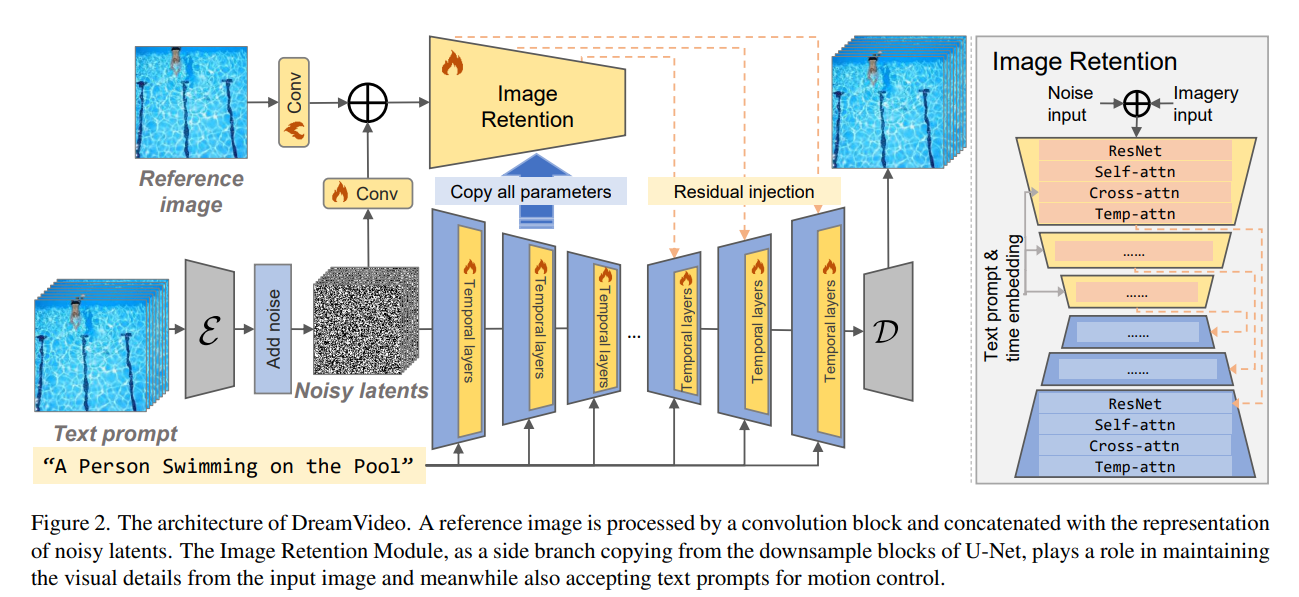
Framework


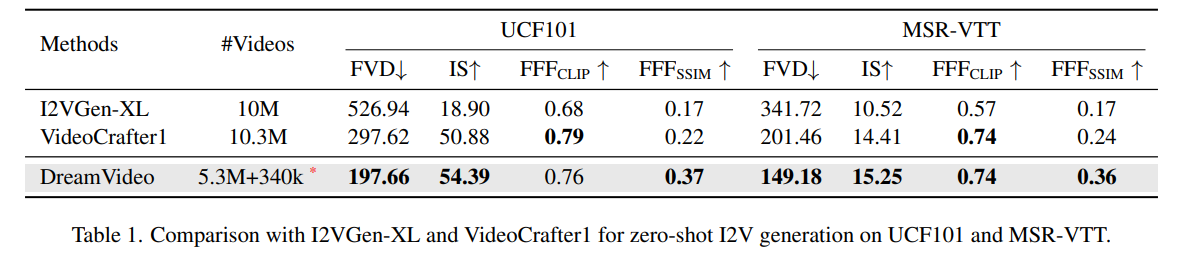
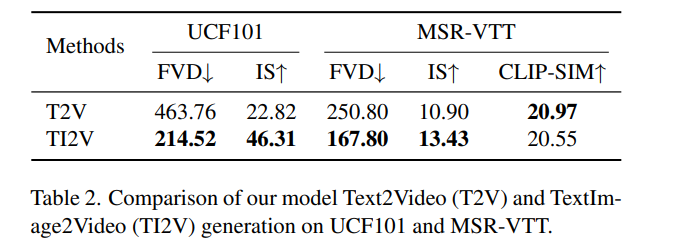
Experiment



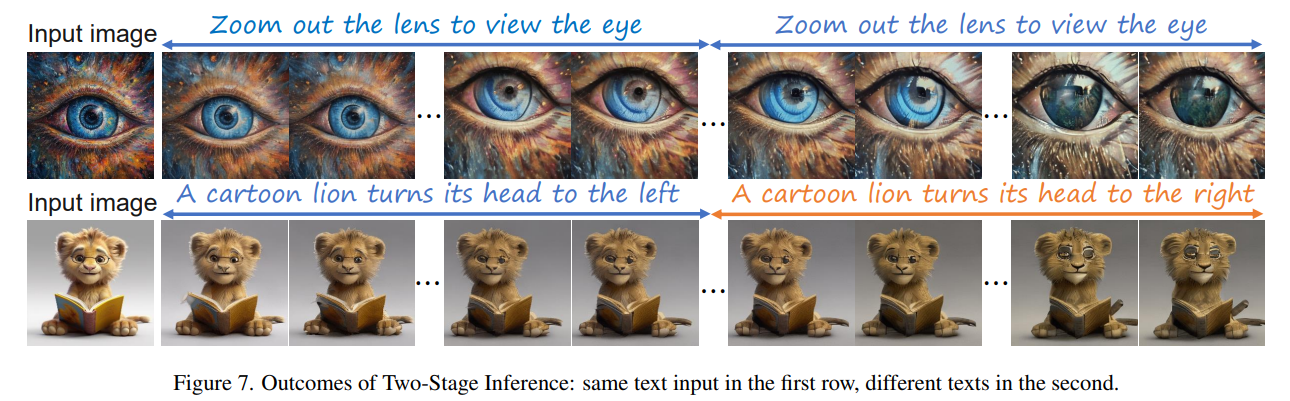
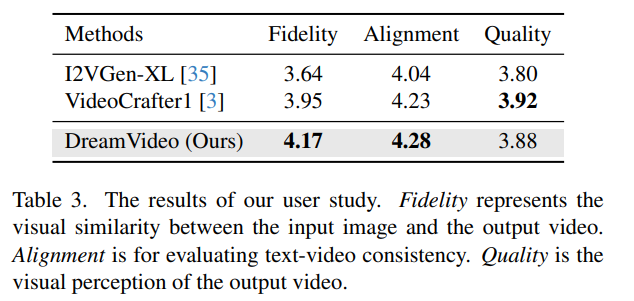
Conclusion
In this work, we present DreamVideo, a model for synthesizing high-quality videos from images. Our DreamVideo has a great image retention capability and supports a combination of image and text inputs as controlling parameters. We propose an Image Retention block that combines control information and gradually integrates it into the primary U-Net. We Explore double-condition classfree guidance for different degrees of image retention. It’s noteworthy that one limitation of our model is that the image retention ability of our DreamVideo relies on high-quality training data. Our DreamVideo is enabled to generate video that maintains superior image retention quality through training with high quality datasets. Finally, we demonstrate DreamVideo’s superiority over the open-source image-video model qualitatively and quantitatively.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab