
Abstract
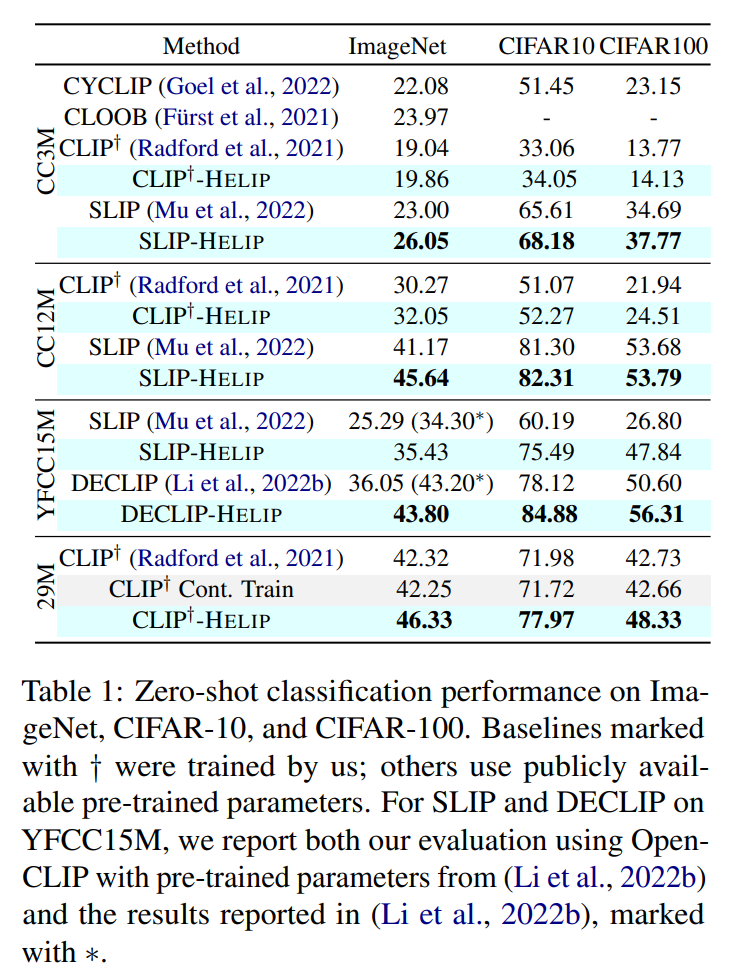
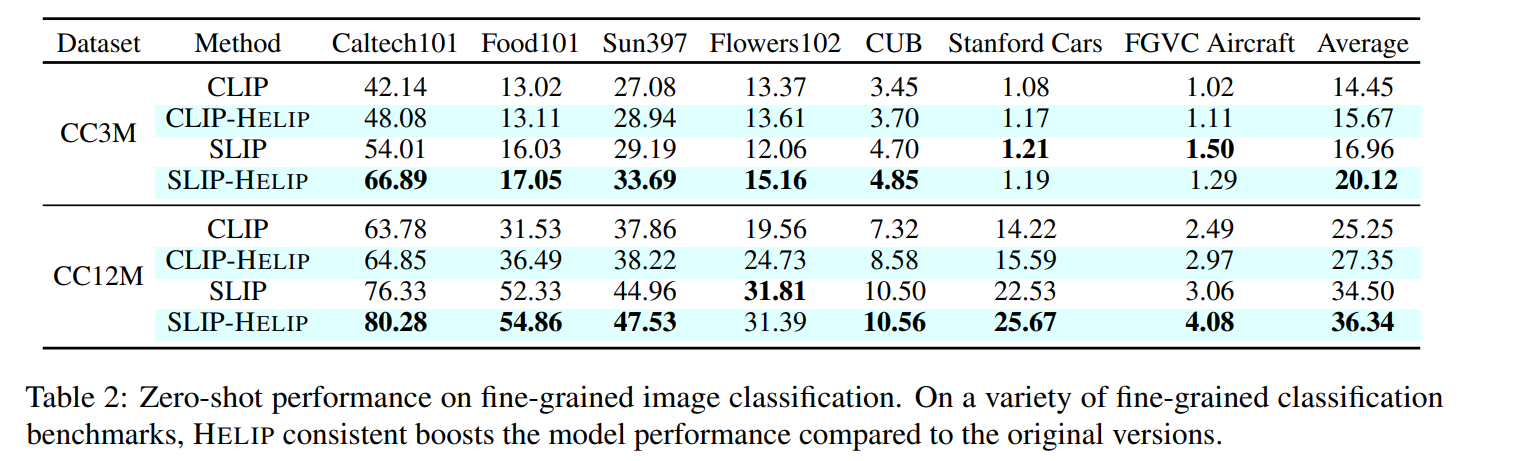
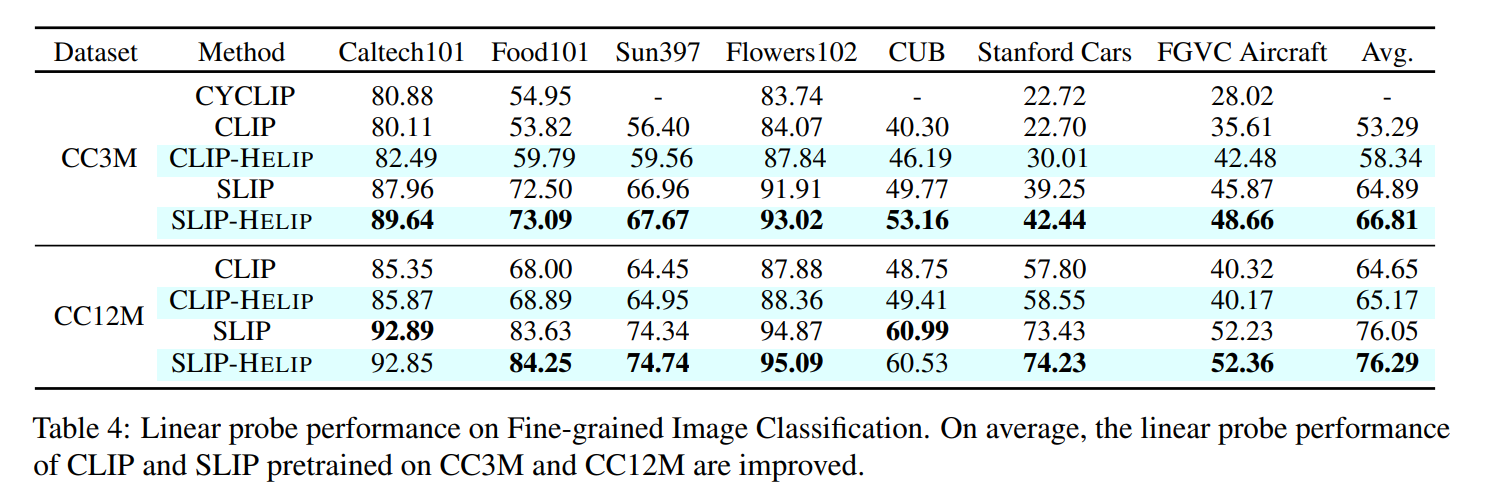
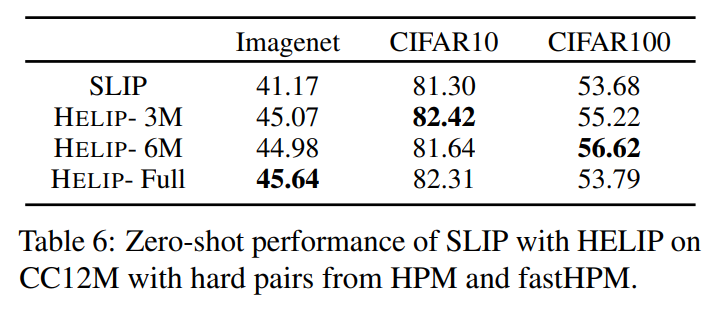
Contrastive Language-Image Pre-training (CLIP) has become the standard for cross- modal image-text representation learning. Improving CLIP typically requires additional data and retraining with new loss functions, but these demands raise resource and time costs, limiting practical use. In this work, we introduce HELIP, a cost-effective strategy that improves CLIP models by exploiting challenging text-image pairs within existing datasets in continuous training. This eliminates the need for additional data or extensive retraining. Moreover, HELIP integrates effortlessly into current training pipelines with minimal code modifications, allowing for quick and seamless implementation. On comprehensive benchmarks, HELIP consistently boosts existing models. In particular, within just two epochs of training, it improves zero-shot classification accuracy on ImageNet for SLIP models pre-trained on CC3M, CC12M, and YFCC15M datasets by 3.05%, 4.47%, and 10.1% , respectively. In addition, on fine-grained classification datasets, HELIP improves the zero-shot performance of CLIP and SLIP by an average of 8.4% and 18.6%, and their linear probe performance by an average of 9.5% and 3.0%.
Framework
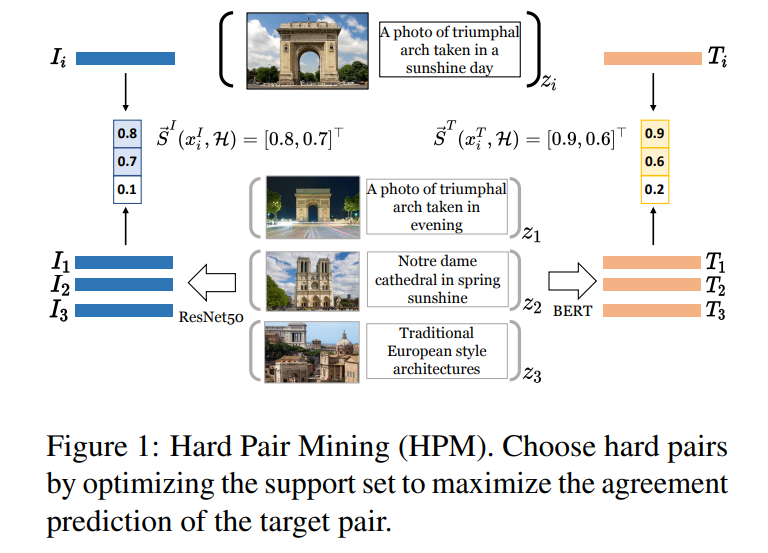
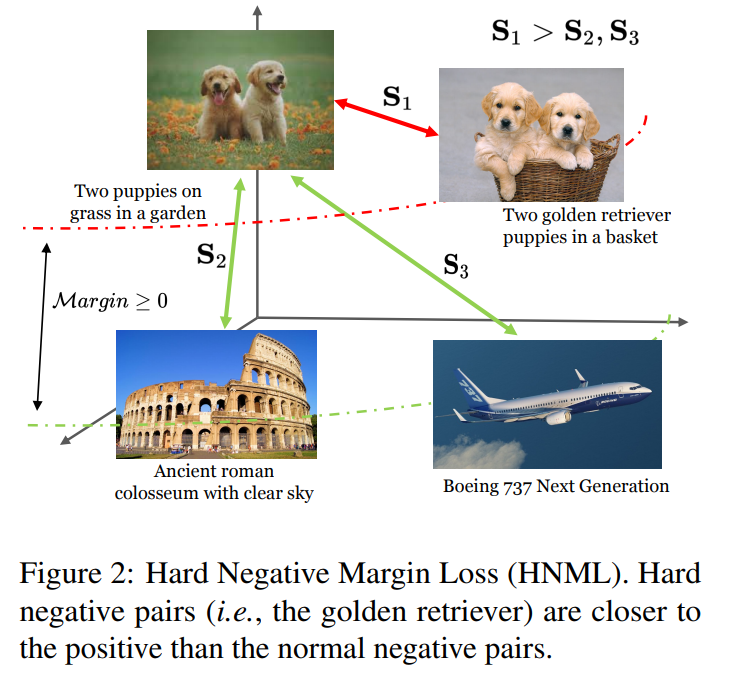
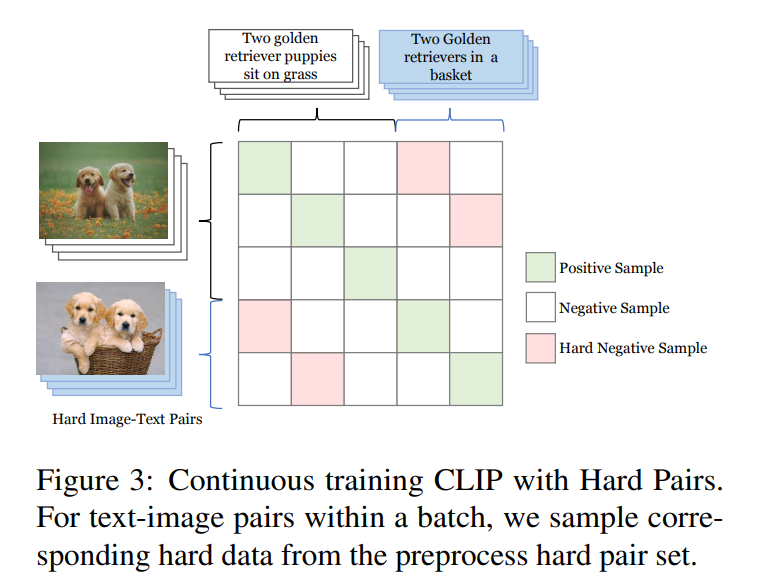
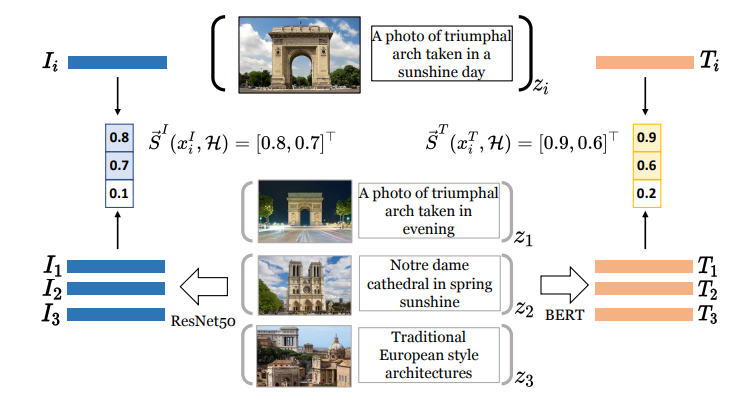
Experiment

Conclusion
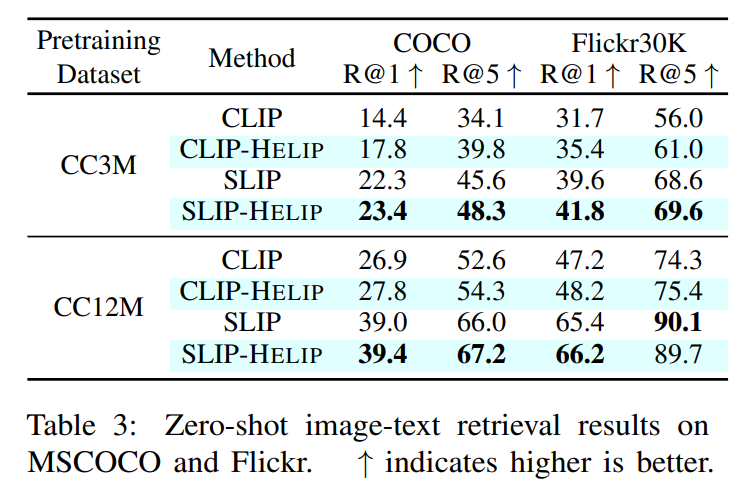
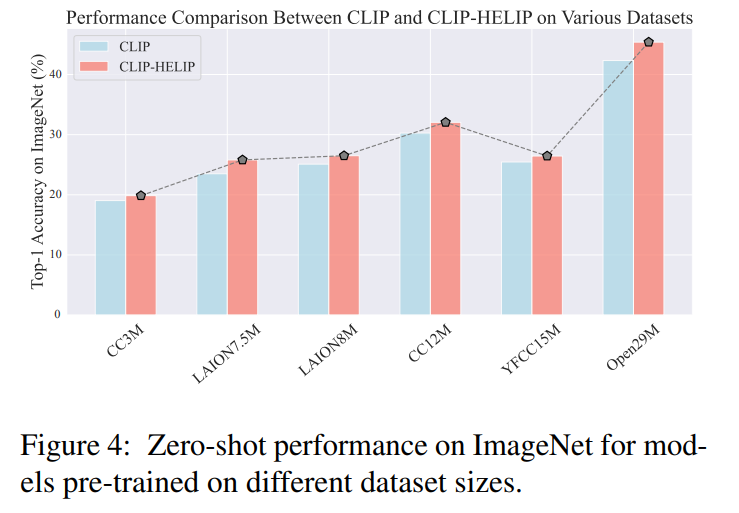
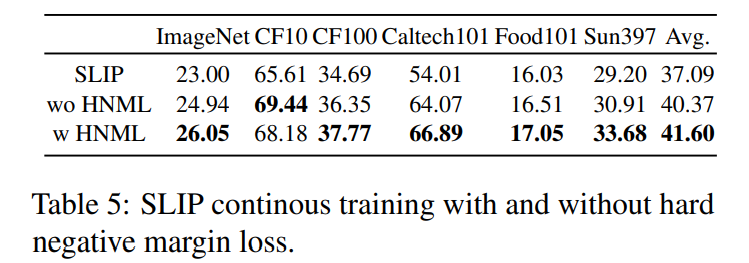
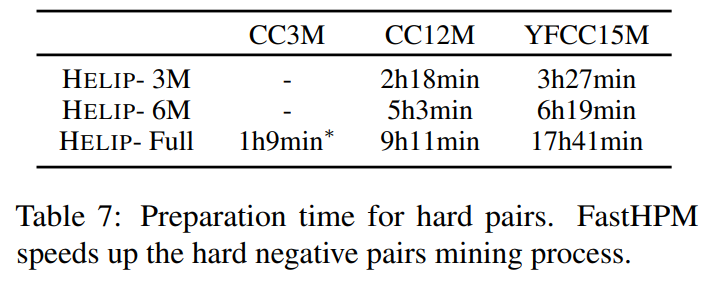
In this work, we present HELIP, a framework that enhances pre-trained CLIP models by more effectively utilizing their original training datasets. HELIPoffers a cost-effective and easily integrable solution for improving existing models without extensive retraining or additional data. Specifically, it treats each text-image pair as a point in the joint vision-language space and identifies hard pairs, those that are close together, using the Hard Pair Mining (HPM) strategy. Furthermore, to efficiently leverage these hard pairs, we introduce the Hard Negative Margin Loss (HNML). Empirically, we found that HELIPboosts the performance of existing checkpoints within a few epochs of continuous training. Evaluations across various benchmarks, including zero-shot classification, imagetext retrieval, and linear probing, demonstrate the effectiveness and efficiency of our method. These findings highlight that in the era of large-scale models and datasets, performance improvement can be achieved not only by collecting more data or scaling up models, but also by intelligently maximizing the utility of the data we already have.
Acknowledgement
References
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab