
Abstract
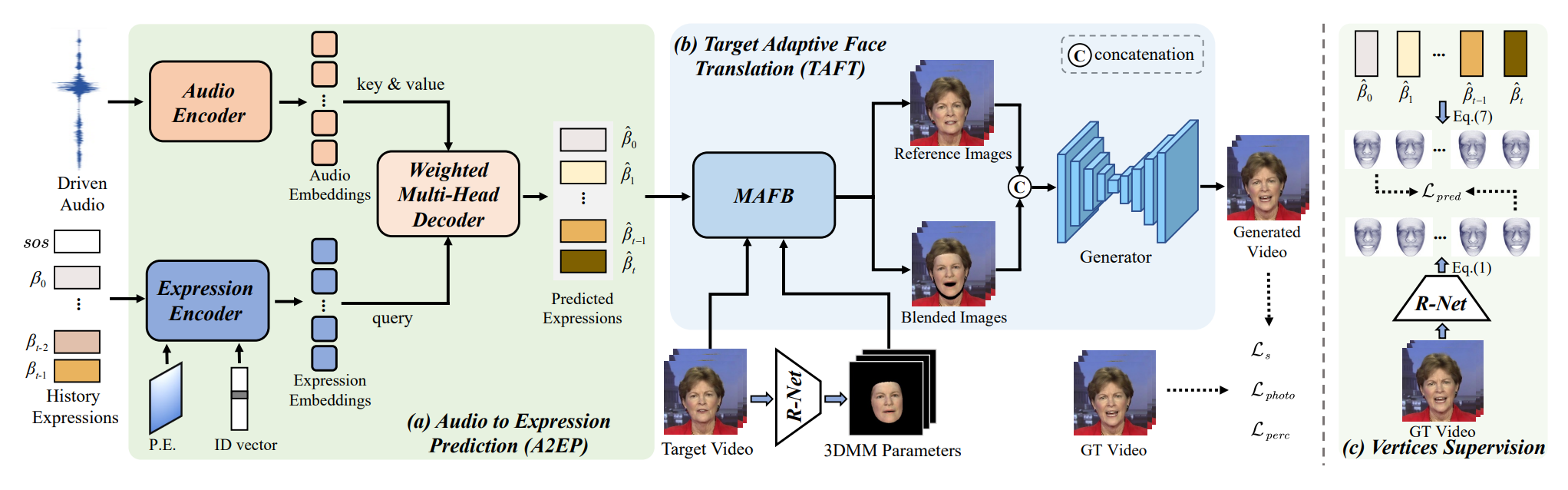
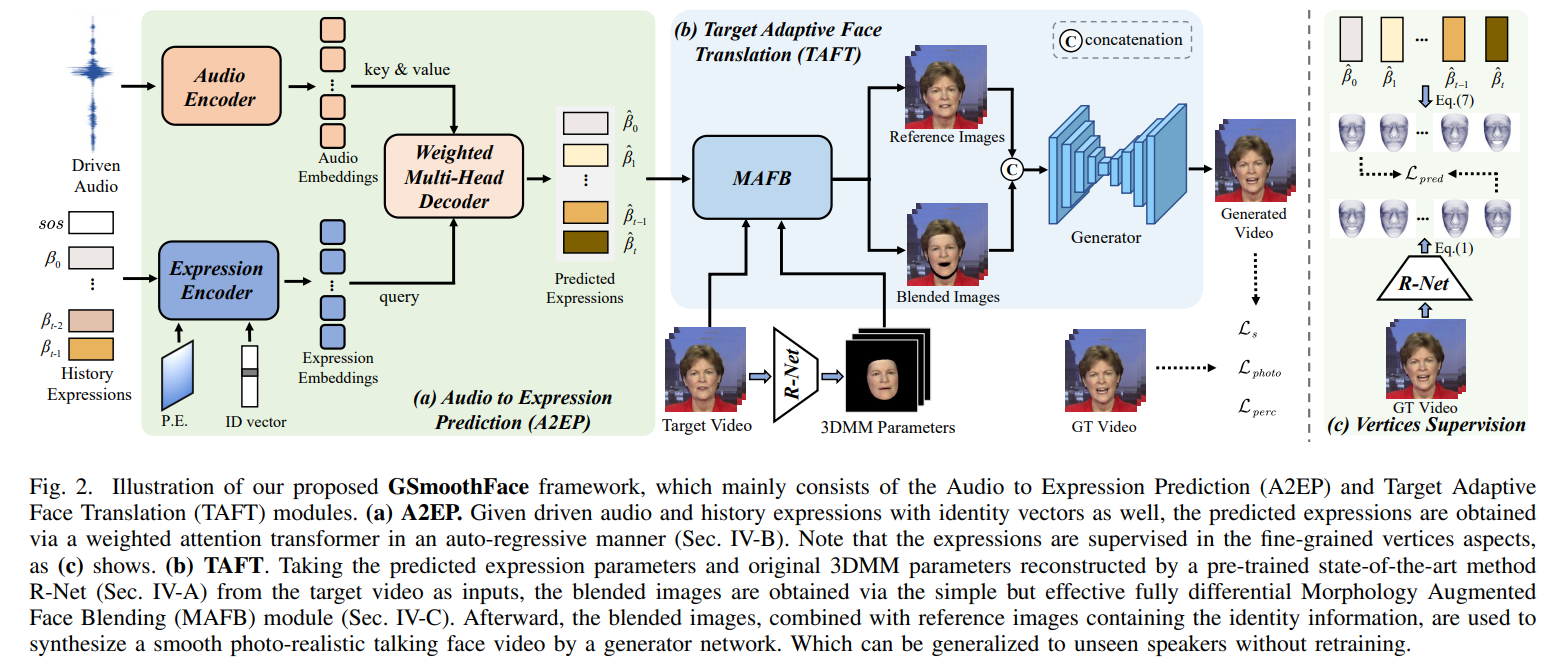
Although existing speech-driven talking face generation methods achieve significant progress, they are far from realworld application due to the avatar-specific training demand and unstable lip movements. To address the above issues, we propose the GSmoothFace, a novel two-stage generalized talking face generation model guided by a fine-grained 3d face model, which can synthesize smooth lip dynamics while preserving the speaker's identity. Our proposed GSmoothFace model mainly consists of the Audio to Expression Prediction (A2EP) module and the Target Adaptive Face Translation (TAFT) module. Specifically, we first develop the A2EP module to predict expression parameters synchronized with the driven speech. It uses a transformer to capture the long-term audio context and learns the parameters from the fine-grained 3D facial vertices, resulting in accurate and smooth lip-synchronization performance. Afterward, the well-designed TAFT module, empowered by Morphology Augmented Face Blending (MAFB), takes the predicted expression parameters and target video as inputs to modify the facial region of the target video without distorting the background content. The TAFT effectively exploits the identity appearance and background context in the target video, which makes it possible to generalize to different speakers without retraining. Both quantitative and qualitative experiments confirm the superiority of our method in terms of realism, lip-synchronization, and visual quality. See the project page for code, data, and request pre-trained models: https://zhanghm1995.github.io/GSmoothFace.
Framework

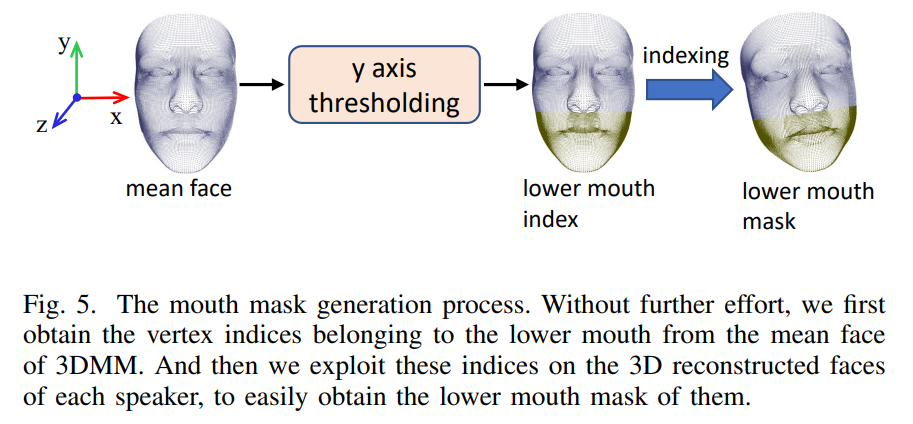
Experiment
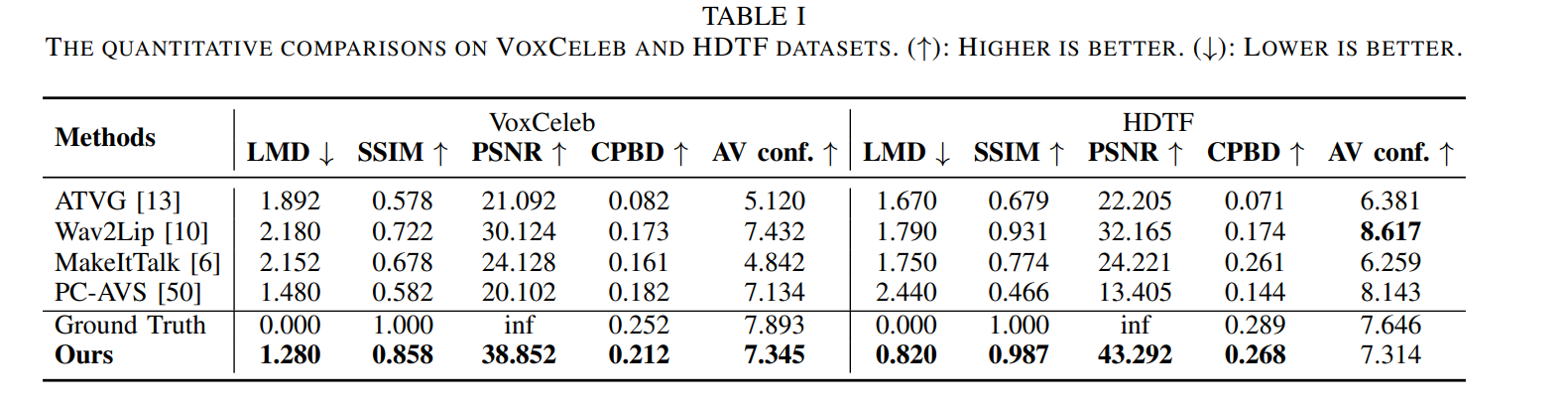
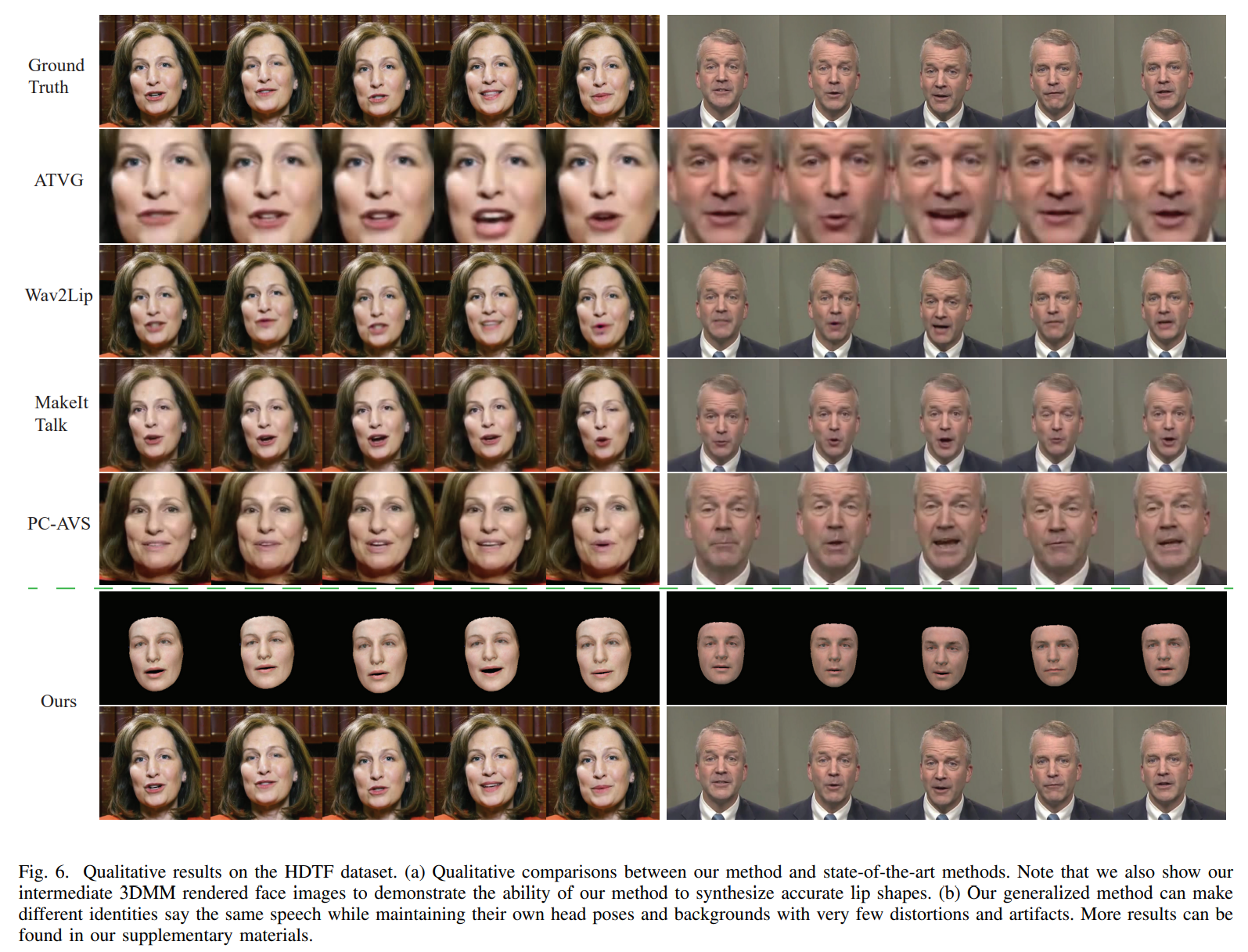
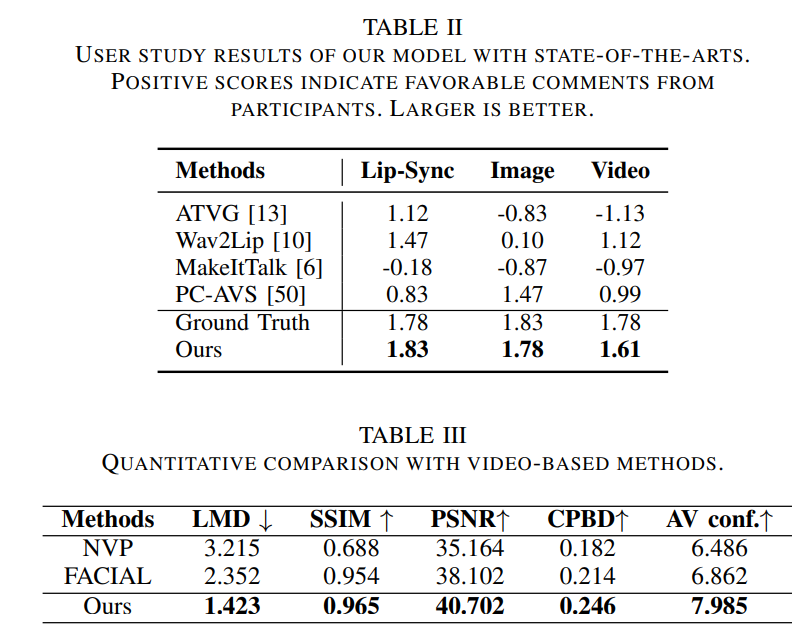
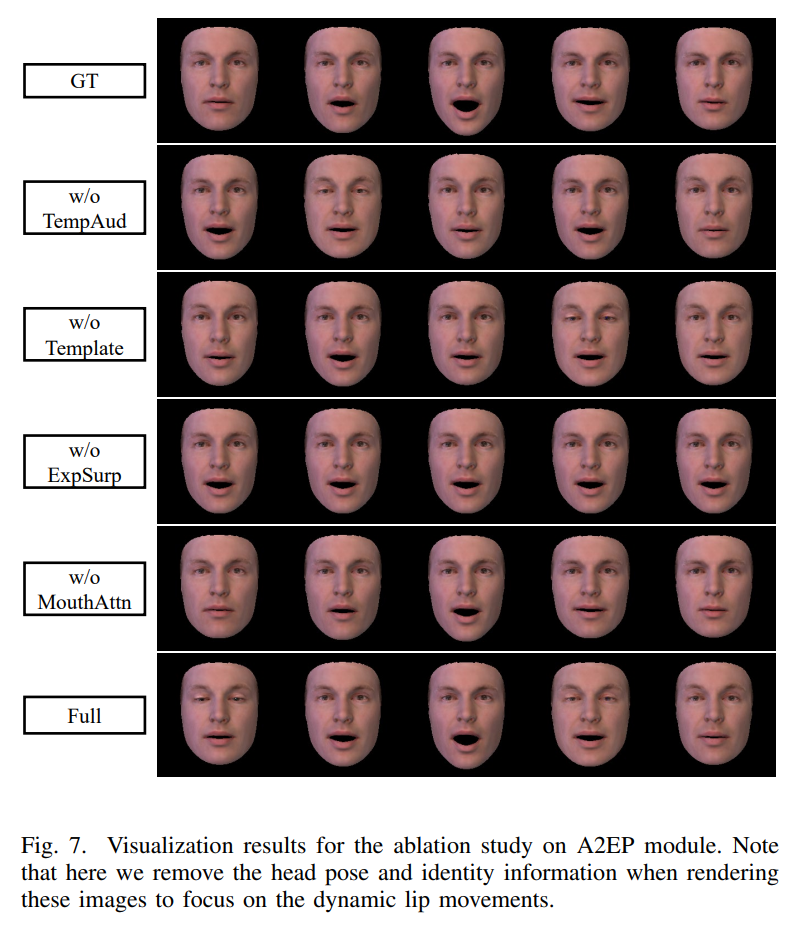
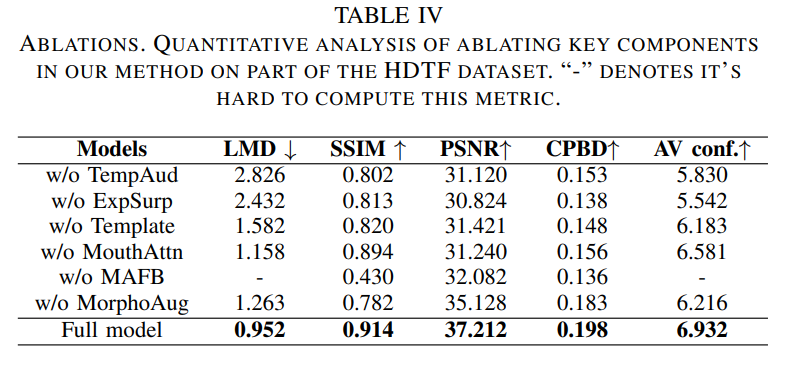
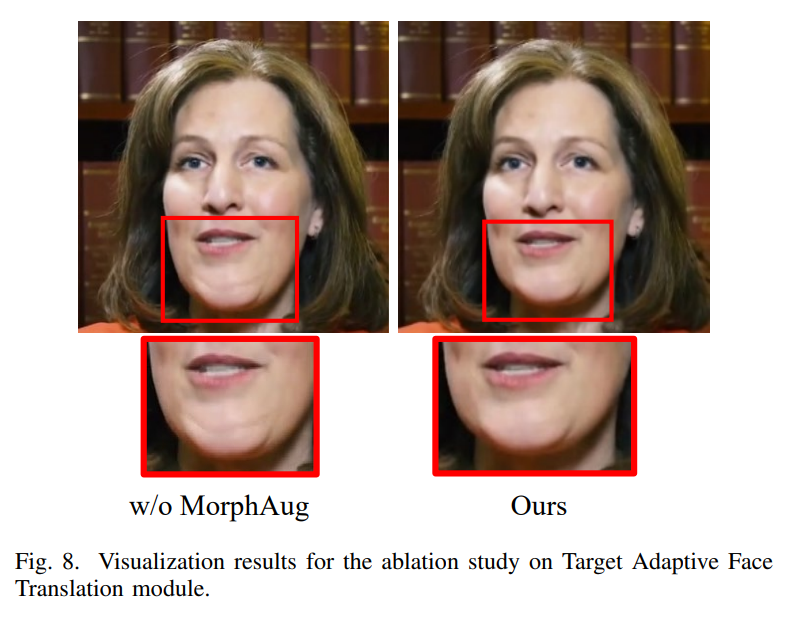
Conclusion
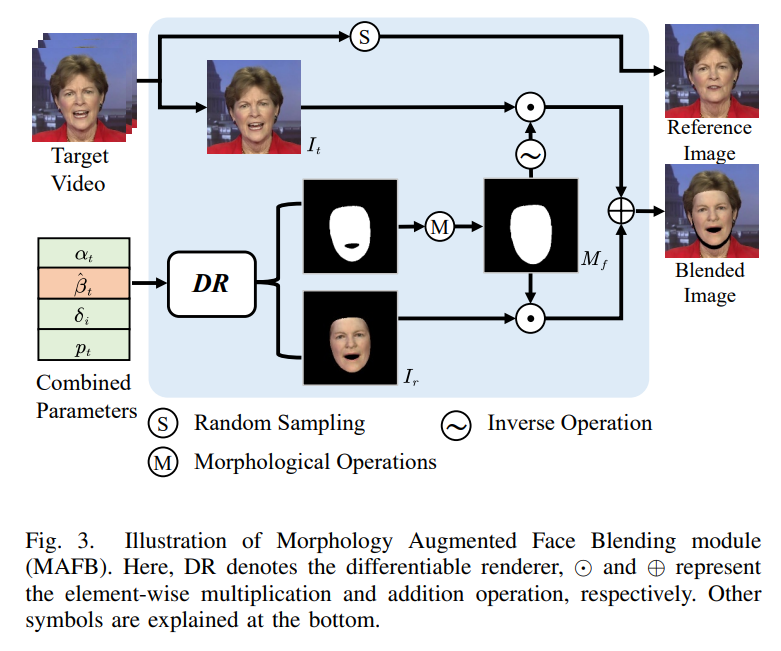
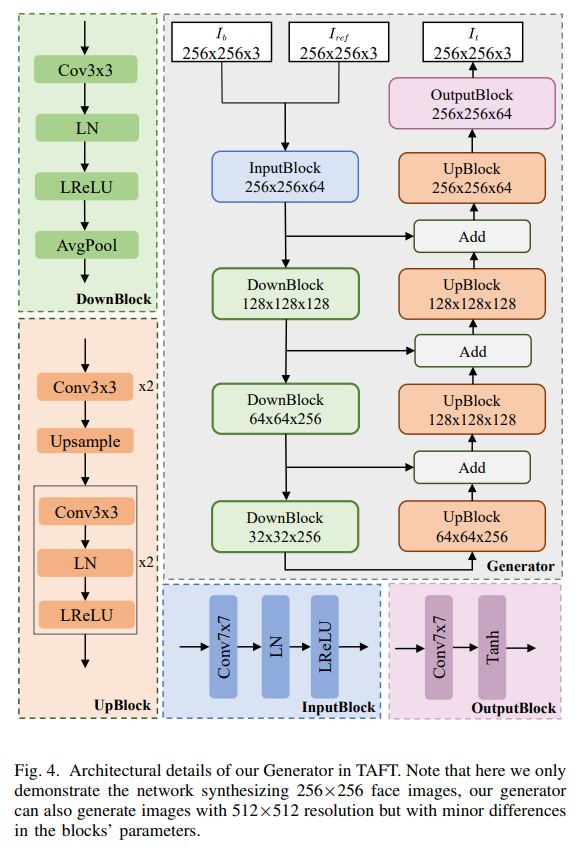
We introduce GSmoothFace, a simple yet effective talking face generation framework via making full use of the fine-grained 3D face model. On one hand, we consider the fact that the limitations of existing 3D face reconstruction algorithms and propose explicitly supervising the expression parameters in dense facial vertices aspect. And in this case, we have the flexibility to attach more weights on the speechrelated areas, e.g. the mouth region. On the other hand, the carefully designed TAFT module leverages the rendered 3D face and binary facial mask image from the 3DMM model without further effort, resulting in synthesizing the photorealistic talking face videos with few artifacts. Our method generalized to unseen identities without re-training, owing to the well-designed TAFT module. Extensive experimental results validate the effectiveness of our method.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab