
CVPR 2025
PS-Diffusion: Photorealistic Subject-Driven Image Editing with Disentangled Control and Attention
Abstract
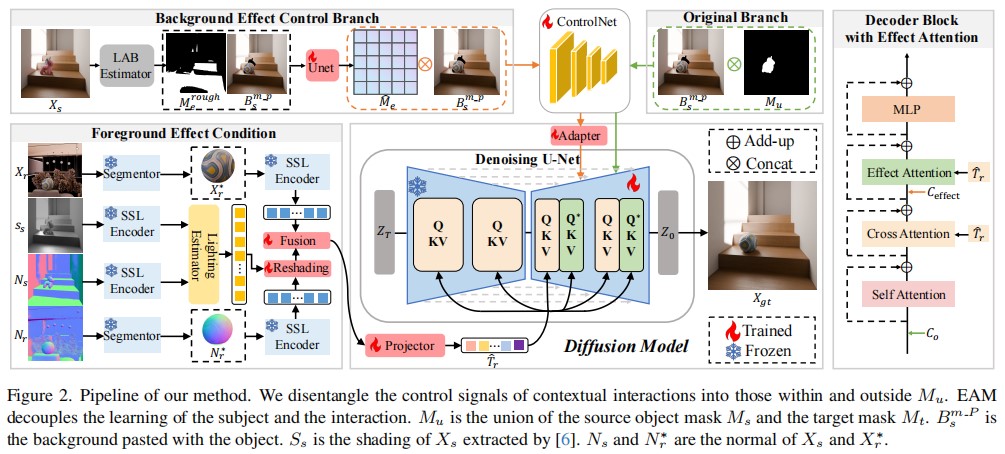
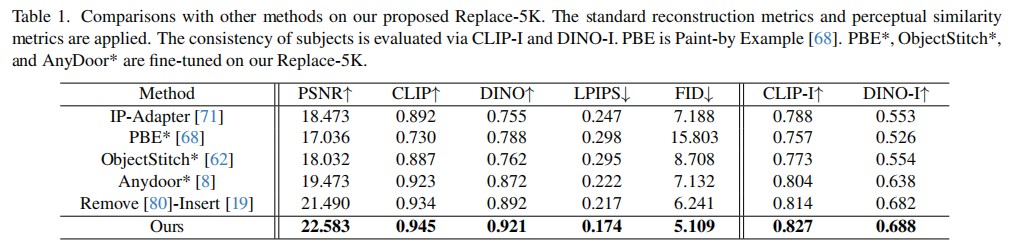
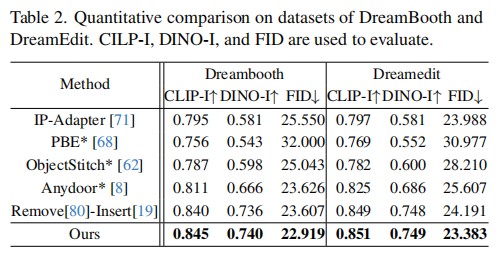
Diffusion models pre-trained on large-scale paired image-text data achieve significant success in image editing. To convey more fine-grained visual details, subject-driven editing integrates subjects in user-provided reference images into existing scenes. However, it is challenging to obtain photorealistic results, which simulate contextual interactions, such as reflections, illumination, and shadows, induced by merging the target object into the source image. To address this issue, we propose PS-Diffusion, which ensures realistic and consistent object-scene blending while maintaining invariance of subject appearance during editing. Specifically, we first divide the contextual interactions into those occurring in the foreground and the background areas. The effect of the former is estimated through intrinsic image decomposition, and the region of the latter is predicted in an additional background effect control branch. Moreover, we propose an effect attention module to disentangle the learning processes of interaction and subject, alleviating confusion between them. Additionally, we introduce a synthesized dataset, Replace-5K, consisting of 5,000 image pairs with invariant subject and contextual interactions via 3D rendering. Extensive quantitative and qualitative experiments on our dataset and two real-world datasets demonstrate that our method achieves state-of-the-art performance.
Framework


Experiment




Conclusion
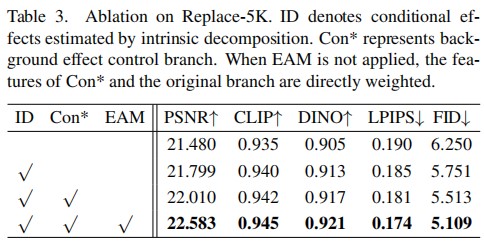
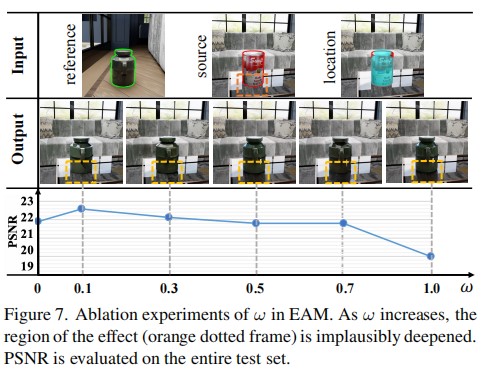
In this paper, we propose PS-Diffusion for photorealistic subject-driven image editing. We first disentangle the control signals of contextual interactions based on their affecting regions. To be specific, for those within the mask, we condition the diffusion model with effects estimated by intrinsic image decomposition. An additional background effect control branch is used to identify regions of effect outside the mask. To alleviate confusion between editing objects and effects tasks, the effect attention module in the denoising U-Net is introduced to separate the learning of effects of contextual interactions and subject features. Extensive experiments demonstrate the effectiveness and scalability of our approach.
中山大学人机物智能融合实验室
Human Cyber Physical Intelligence Integration Lab
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号
Official Account

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab
©2026 HCP in SYSU 粤ICP备2021037607号
©2026 HCP in SYSU
粤ICP备2021037607号