
Abstract
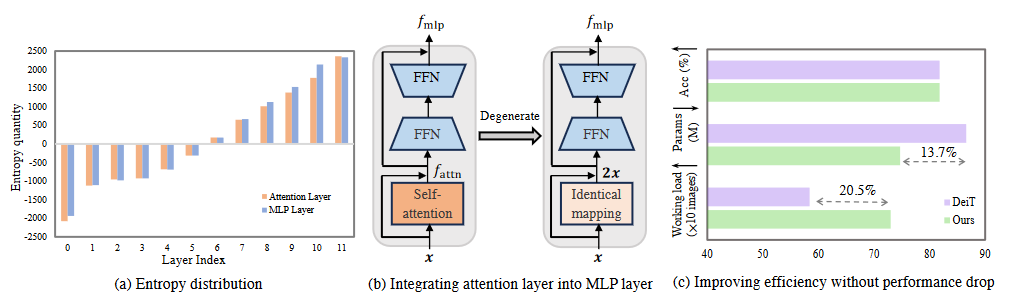
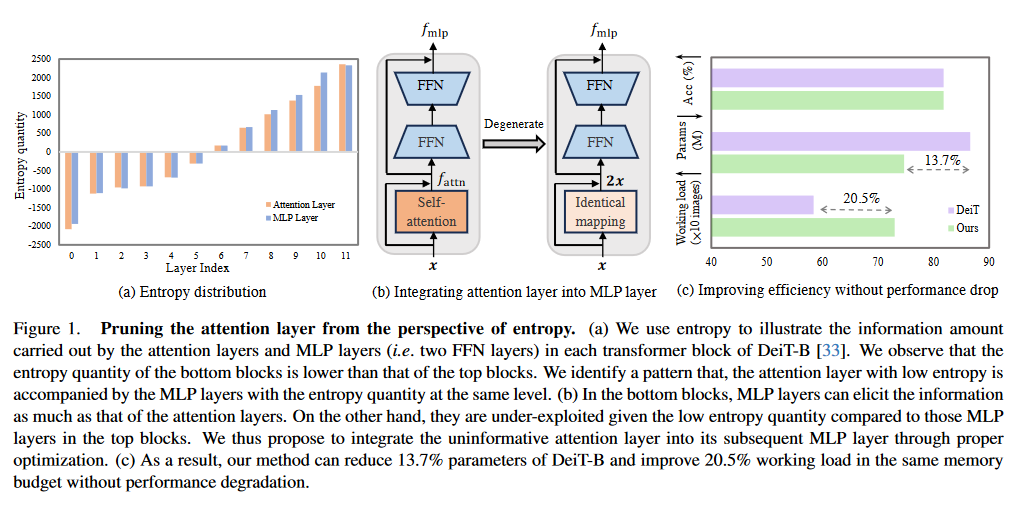
Self-attention mechanism is the key of the Transformer but often criticized for its computation demands. Previous token pruning works motivate their methods from the view of computation redundancy but still need to load the full network and require same memory costs. This paper introduces a novel strategy that simplifies vision transformers and reduces computational load through the selective removal of non-essential attention layers, guided by entropy considerations. We identify that regarding the attention layer in bottom blocks, their subsequent MLP layers, i.e. two feed-forward layers, can elicit the same entropy quantity. Meanwhile, the accompanied MLPs are under-exploited since they exhibit smaller feature entropy compared to those MLPs in the top blocks. Therefore, we propose to integrate the uninformative attention layers into their subsequent counterparts by degenerating them into identical mapping, yielding only MLP in certain transformer blocks. Experimental results on ImageNet-1k show that the proposed method can remove 40% attention layer of DeiT-B, improving throughput and memory bound without performance compromise.
Framework

Experiment

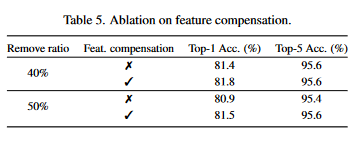
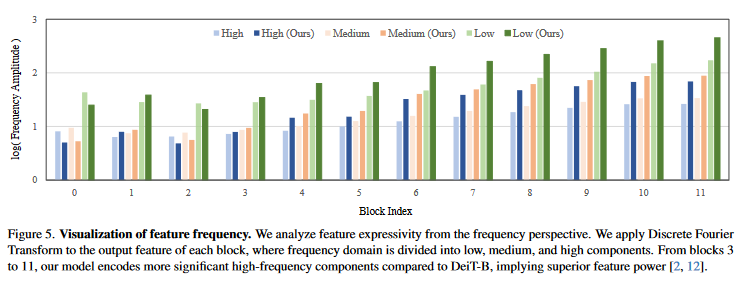
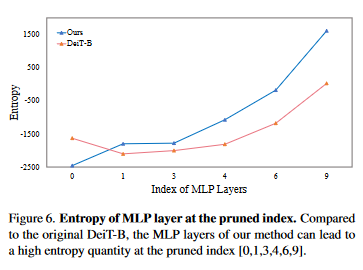
Conclusion
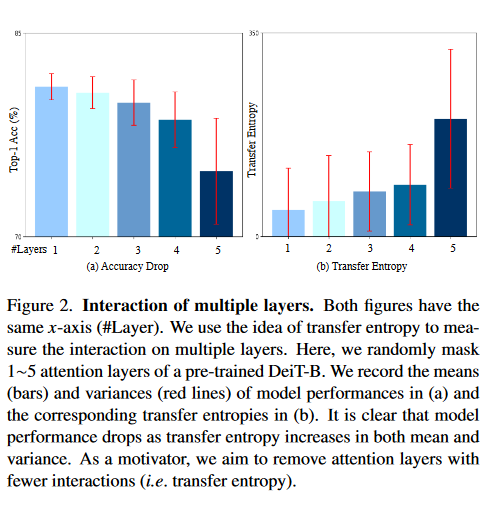
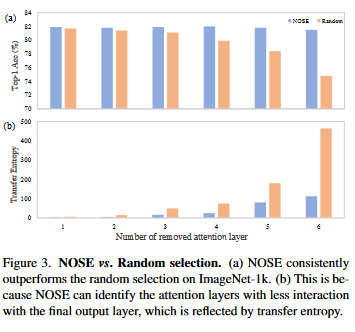
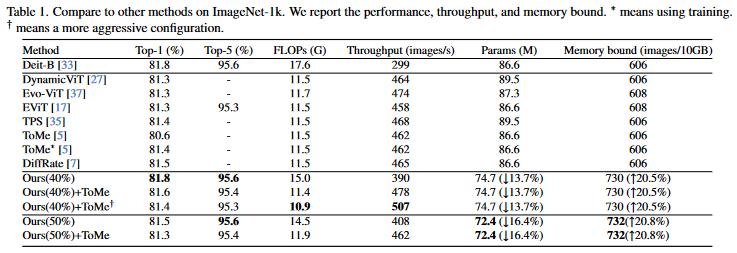
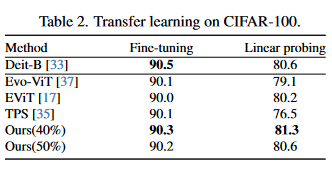
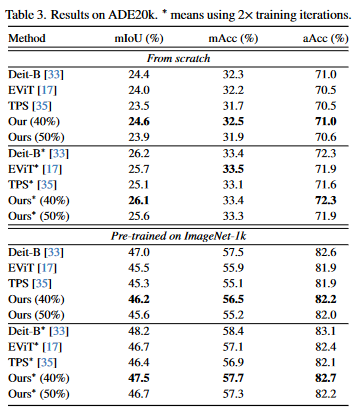
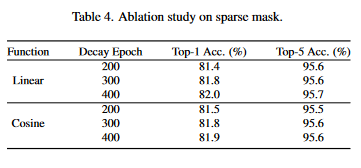
This work aims to remove the attention layers from the perspective of entropy. In particular, we propose the entropyguided selection strategy (NOSE) to measure the interaction among multiple layers, which identifies the combination of attention layers that has the least influence on the model outputs. Then, we gradually degenerate those attention layers into identical mapping using a dilution learning technique, yielding only MLP in those transformer blocks. We demonstrate the effectiveness of our method on ImageNet1k, ADE20k, and CIFAR-100 by comparing it to current state-of-the-art strategies. Our method reduces the network parameters as well as memory requirements. Therefore, it is able to increase the working load, which remains untouched by previous token pruning methods. Combined with the unsupervised token merging method, it strikingly boosts the throughput of the vision transformer. We also discuss the learned features of our model through DFT. The result shows that compared to
Acknowledgement
This work was supported in part by the National Science and Technology Major Project under Grant No. 2020AAA0109704, Guangdong Outstanding Youth Fund (Grant No. 2021B1515020061), and Australian Research Council (ARC) Discovery Program under Grant No. DP240100181. The authors thank Yuetian Weng (@MonashU) for discussions.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab