

Binbin Yang1, Kangyang Xie2, Xinyu Xiao3, Meng Wang3, Yang Liu1, Jingdong Chen3, Ming Yang3, Liang Lin1
1Sun Yat-sen University, 2Zhejiang University, 3Antgroup

VidMaestro utilizes a reference image (the leftmost frame), and uses a pair of appearance and motion descriptions as prompts to generate a video.
Abstract
Recent advances in diffusion models have greatly propelled the progress of text-to-image (T2I) generation. However, generating both high-fidelity and high-dynamic videos poses greater challenges due to the high-dimensional latent space, the intricate spatial-temporal relationships, and the strong reliance on high-quality training data. Prior works have sought to extend a T2I diffusion model to a text/image-to-video model by incorporating temporal convolution modules. While the integration of temporal operations can enhance temporal consistency, they often suffer from limited object animation and unsatisfactory motion patterns. An underlying cause is the straightforward reuse of frame-wise spatial feature transformation and semantic alignment from the text-to-image backbone, which is insufficient to comprehensively capture the intricate spatial-temporal dynamics. In this work, we present VidMaestro, a video diffusion model to generate high-definition videos with controllable motion by separately guiding the appearance and motion information. Specifically, our method takes inputs as an appearance prompt comprising a reference image and a textual description, and a motion prompt detailing the movement and actions within the video. Unlike previous works that solely use spatial 2D self-attention and cross-attention to individually align each frame with the appearance prompt, our VidMaestro introduces a motion-aware 3D attention module to comprehensively capture video dynamics in the spatial-temporal space and thereby improve the semantic alignment with the input motion cues. By explicitly guiding the spatial and temporal content with these two cues, our VidMaestro exhibits the capability to generate controllable and high-dynamic motions rather than minimal animations. Extensive experiments have been conducted to demonstrate the superior spatial-temporal generative performance of our method, especially with temporal consistency and controllable motion.
Spatial 2D cross-attention v.s. Motion-aware 3D cross-attention
Spatial 2D cross-attention fails to correctly associate the "roaring" token with appropriate region. By contrast, our motion-aware 3D cross-attention successfully localizes the mouth of the mechanical white tiger and captures its moving trajectory.

2D Cross-attention 3D Cross-attention
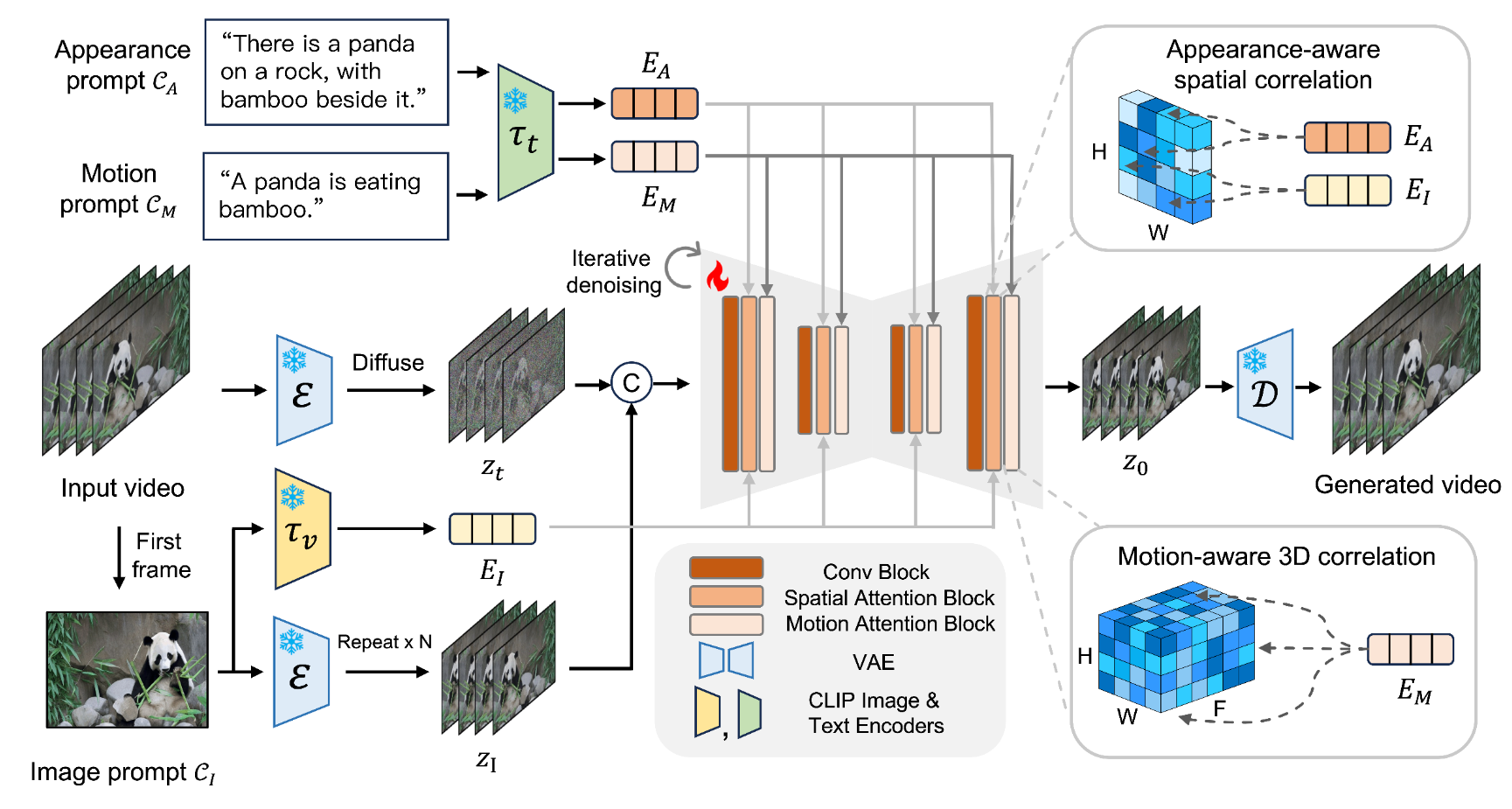
Model Architecture
Gallery
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab