
Abstract
Open vocabulary object detection (OVD) aims at seeking an optimal object detector capable of recognizing objects from both base and novel categories. Recent advances leverage knowledge distillation to transfer insightful knowledge from pre-trained large-scale vision-language models to the task of object detection, significantly generalizing the powerful capabilities of the detector to identify more unknown object categories. However, these methods face significant challenges in background interpretation and model overfitting and thus often result in the loss of crucial background knowledge, giving rise to sub-optimal inference performance of the detector. To mitigate these issues, we present a novel OVD framework termed LBP to propose learning background prompts to harness explored implicit background knowledge, thus enhancing the detection performance w.r.t. base and novel categories. Specifically, we devise three modules: Background Category-specific Prompt, Background Object Discovery, and Inference Probability Rectification, to empower the detector to discover, represent, and leverage implicit object knowledge explored from background proposals. Evaluation on two benchmark datasets, OV-COCO and OV-LVIS, demonstrates the superiority of our proposed method over existing state-of-the-art approaches in handling the OVD tasks.
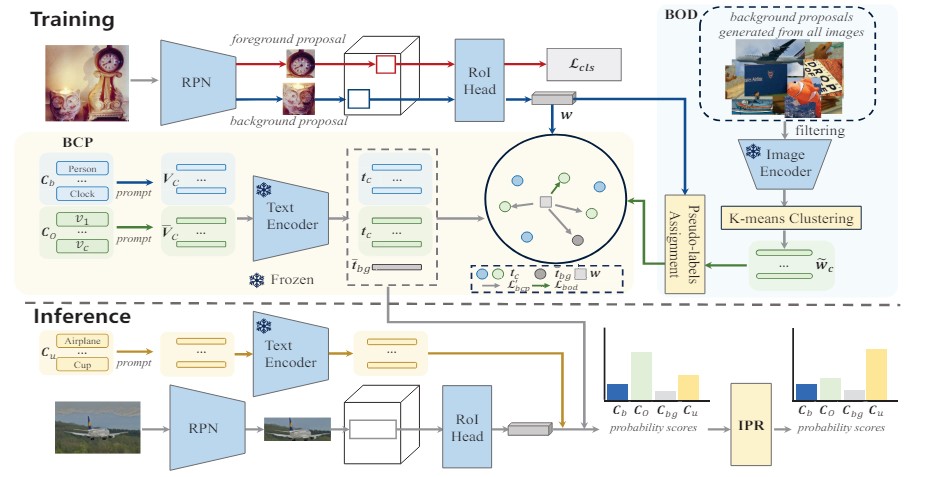
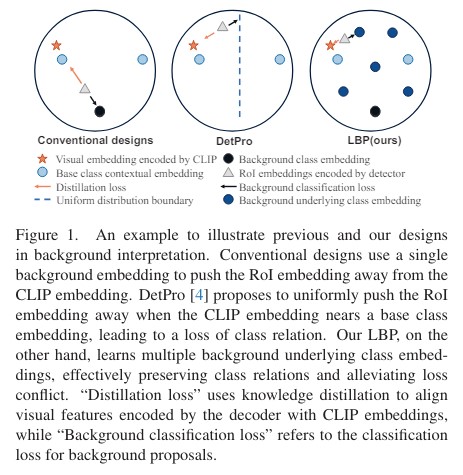
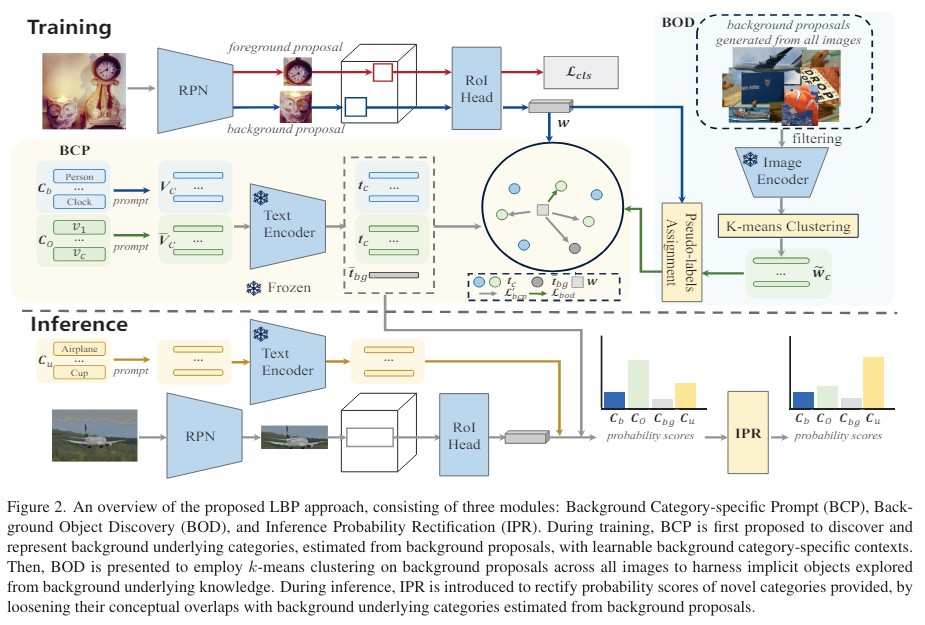
Framework
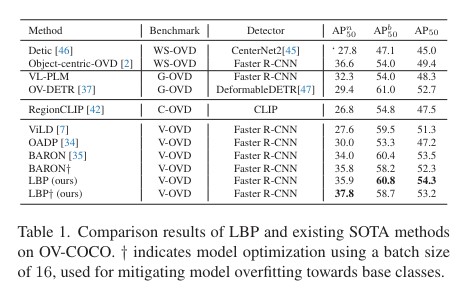
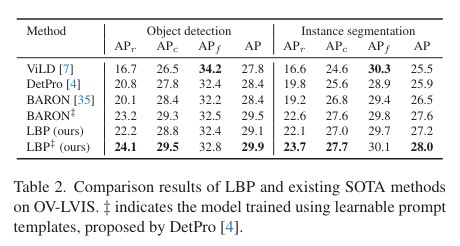
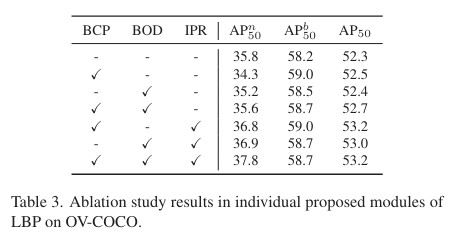
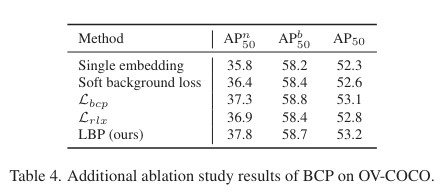
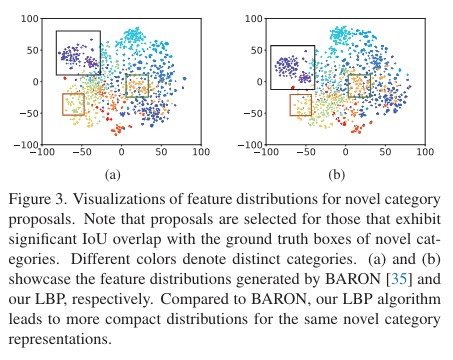
Experiment
Conclusion
In this paper, we have introduced LBP, a novel framework addressing the challenges of open-vocabulary object detection. In this approach, learning background prompts is proposed to harness explored implicit background knowledge. This can enhance the capacity of the detecter to recognize both base and novel categories during inference. To achieve this, we have devised three essential modules: Background Category-specific Prompt, Background Object Discovery, and Inference Probability Rectification. These modules collectively empower the detector to discover, represent, and leverage implicit object knowledge explored from background proposals. Our proposed approach has been rigorously evaluated through extensive experiments and thorough ablation studies, confirming its superior performance.
Acknowledgement
This work was supported in part by the National Natural Science Foundation of China (NO. 62322608), in part by the CAAI-MindSpore Open Fund, developed on OpenI Community, in part by the Shenzhen Science and Technology Program (NO. JCYJ20220530141211024), in part by the Open Project Program of State Key Laboratory of Virtual Reality Technology and Systems, Beihang University (No.VRLAB2023A01).
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab