

Abstract
Text-driven 3D scene editing has gained significant attention owing to its convenience and user-friendliness. However, existing methods still lack accurate control of the specified appearance and location of the editing result due to the inherent limitations of the text description. To this end, we propose a 3D scene editing framework, TIP-Editor, that accepts both text and imageprompts and a 3D bounding box to specify the editing region. With the image prompt, users can conveniently specify the detailed appearance/style of the target content in complement to the text description, enabling accurate control of the appearance. Specifically, TIP-Editor employs a stepwise 2D personalization strategy to better learn the representation of the existing scene and the reference image, in which a localization loss is proposed to encourage correct object placement as specified by the bounding box. Additionally, TIP-Editor utilizes explicit and flexible 3D Gaussian splatting (GS) as the 3D representation to facilitate local editing while keeping the background unchanged. Extensive experiments have demonstrated that TIPEditor conducts accurate editing following the text and image prompts in the specified bounding box region, consistently outperforming the baselines in editing quality, and the alignment to the prompts, qualitatively and quantitatively.
Framework
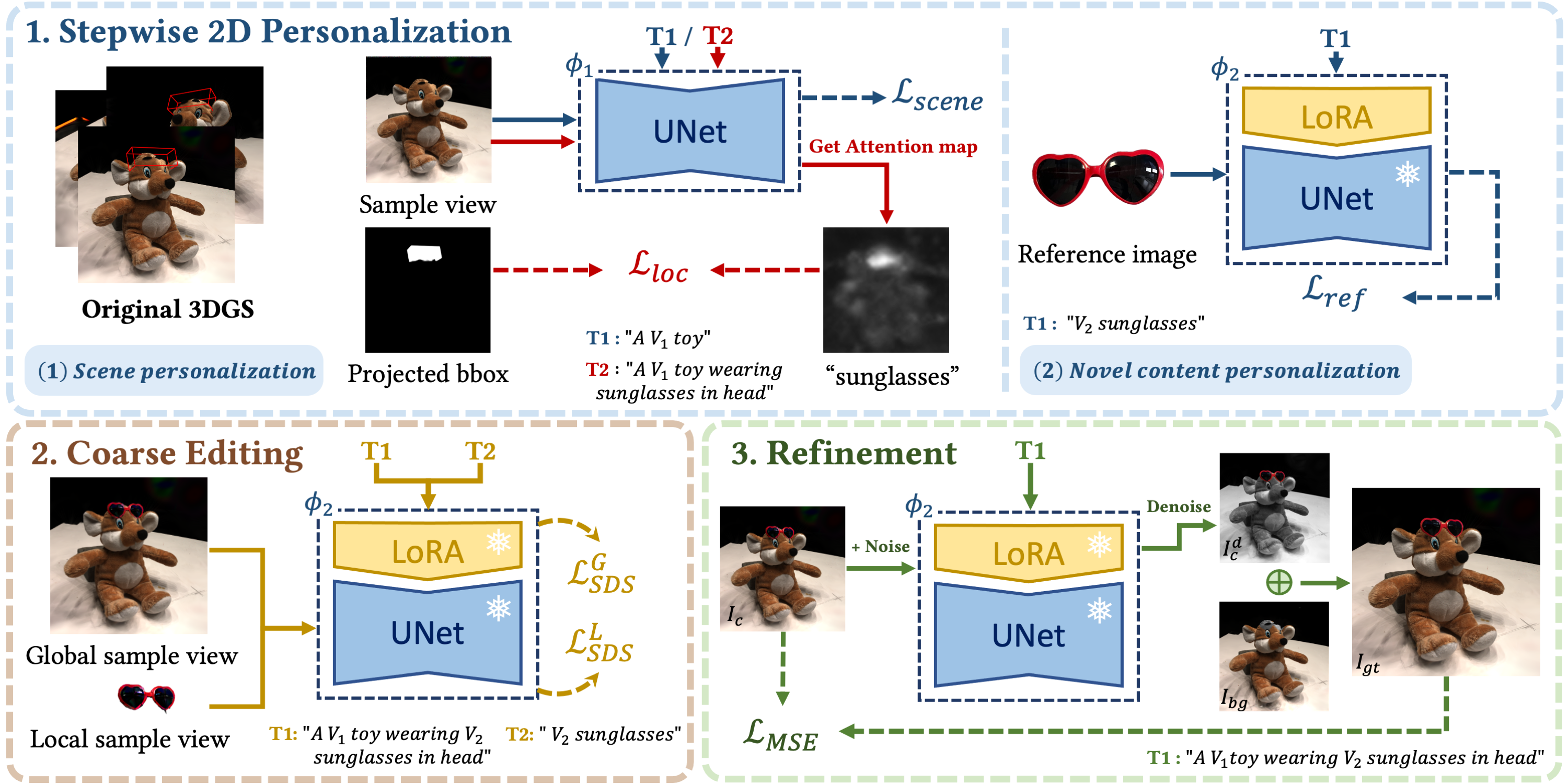
TIP-Editor optimizes a 3D scene that is represented as 3D Gaussian splatting (GS) to conform with a given hybrid text-image prompt. The editing process includes three stages: 1) a stepwise 2D personalization strategy, which features a localization loss in the scene personalization step and a separate novel content personalization step dedicated to the reference image based on LoRA; 2) a coarse editing stage using SDS; and 3) a pixel-level texture refinement stage, utilizing carefully generated pseudo-GT image from both the rendered image 𝐼𝑐 and the denoised image 𝐼𝑑 𝑐 .
Experiment
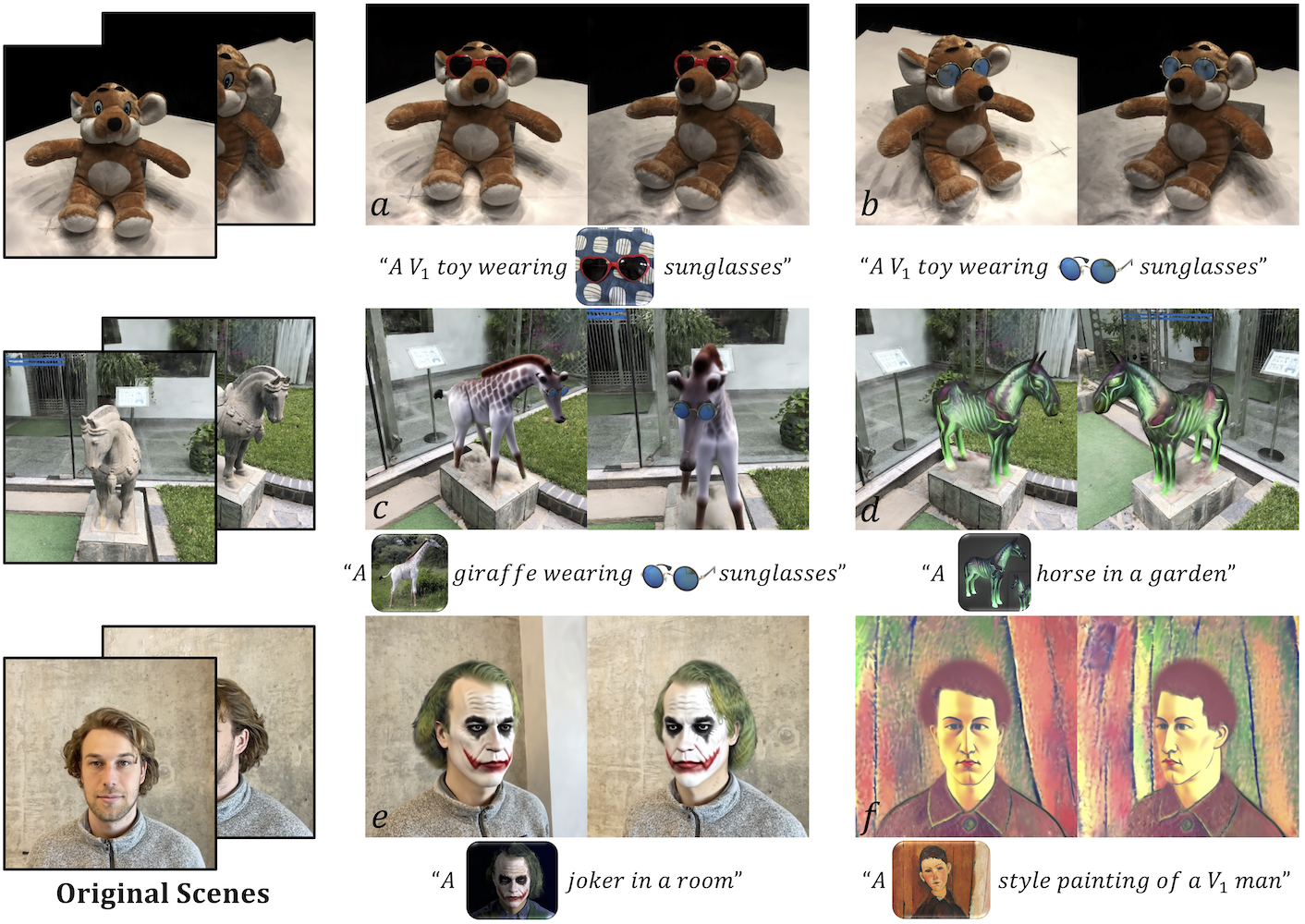
Fig. 1. TIP-Editor excels in precise and high-quality localized editing given a 3D bounding box, and allows the users to perform various types of editing on a 3D scene, such as object insertion (𝑎, 𝑏 ), whole object replacement (𝑑 ), part-level object editing (𝑒 ), combination of these editing types (i.e. sequential editing,(𝑐 )), and stylization (𝑓 ). The editing process is guided by not only the text but also one reference image, which serves as the complement of the textualdescription and results in more accurate editing control. Images in the text prompts denote their associated rare tokens, which are fixed without optimization.
Keeping unique characteristics specified by the reference image. One of the most distinguishable differences between TIP-Editor and previous methods is that TIP-Editor also supports an image prompt, which offers more accurate control and makes it more user-friendly in real applications. Results in Fig. 1&3 demonstrate high consistency between the updated 3D scene and the reference image (e.g. the styles of the sunglasses; the white giraffe; the virtual ghost horse; the joker make-up appeared in movie The Dark Knight). Moreover, as depicted in the bottom of Fig. 1, our method can also perform global scene editing, such as transferring the entire scene in theModigliani style of the reference image.

Fig. 4. Sequential editing results. We show two rendered images of the 3D scene after every editing step, indicated by the number in the top-left corner. 𝑉∗,𝑉∗∗, and 𝑉∗∗∗ represent the special tokens of the scene in different sequences of editing.
Sequential editing. TIP-Editor can sequentially edit the initial scene multiple times thanks to the local update of the GS and the stepwise 2D personalization strategy, which effectively reduces the interference between the existing scene and the novel content. Results in Fig.4 demonstrate the sequential editing capability. There is no observable quality degradation after multiple times of editing and no interference between different editing operations

Fig. 5. Results of using a generated image as the reference. We first generate several candidate images by the diffusion model using text prompts, then we choose one as the reference image for editing.
Using generated image as the reference. In the absence of the reference image, we can generate multiple candidates from a T2I model and let the user choose a satisfactory one. This interaction offers the user more control and makes the final result more predictable. Fig. 5 shows some examples.

Fig. 6. Visual comparisons between different methods. Our method produces obviously higher-quality results and accurately follows the reference image input (bottom-right corner in column 1). Instruct-N2N sometimes misunderstands (row 1) or overlooks (row 2) the keywords. DreamEditor faces difficulty in making obvious shape changes (row 2). Both of them do not support image prompts to specify detailed appearance/style, producing less controlled results.
Fig.6 shows visual comparisons between our method and the baselines. Since both baselines do not support image prompts as input, they generate an uncontrolled (probably the most common) item belonging to the object category. In contrast, our results consistently maintain the unique characteristics specified in the reference images (i.e., the heart-shaped sunglasses; the whitegiraffe; the joker from the movie The Dark Knight).
Moreover, Instruct-N2N sometimes misunderstands (row 1) or overlooks (row 2) the keywords, or cannot generate a specified appearance in limited experiments (row 3), probably due to limited supported instructions in Instruct-Pix2Pix. DreamEditor also faces difficulty if the user wants to add a specified sunglasses item (row 1). Additionally, it is difficult for DreamEditor to make obvious shape changes (row 2) to the existing object due to its adoption of a less flexible mesh-based representation (i.e., NeuMesh).
Conclusion
In this paper, our proposed TIP-Editor equips the emerging textdriven 3D editing with an additional image prompt as a complement to the textual description and produces high-quality editing results accurately aligned with the text and image prompts while keeping the background unchanged. TIP-Editor offers significantly enhanced controllability and enables versatile applications, including object insertion, object replacement, re-texturing, and stylization.
Acknowledgement
This work was supported in part by the National Natural Science Foundation of China (NO.~62322608), in part by the CAAI-MindSpore Open Fund, developed on OpenI Community,in part by the Open Project Program of State Key Laboratory of Virtual Reality Technology and Systems, Beihang University (No.VRLAB2023A01).
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab