
Abstract
Existing visual question answering methods often suffer from cross-modal spurious correlations and oversimplifified event-level reasoning processes that fail to capture event temporality, causality, and dynamics spanning over the video. In this work, to address the task of event-level visual question answering, we propose a framework for cross-modal causal relational reasoning. In particular, a set of causal intervention operations is introduced to discover the underlying causal structures across visual and linguistic modalities. Our framework, named Cross-Modal Causal RelatIonal Reasoning (CMCIR), involves three modules: i) Causality-aware Visual-Linguistic Reasoning (CVLR) module for collaboratively disentangling the visual and linguistic spurious correlations via front-door and back-door causal interventions; ii) Spatial-Temporal Transformer (STT) module for capturing the fifine-grained interactions between visual and linguistic semantics; iii) Visual-Linguistic Feature Fusion (VLFF) module for learning the global semantic-aware visual-linguistic representations adaptively. Extensive experiments on four event-level datasets demonstrate the superiority of our CMCIR in discovering visual-linguistic causal structures and achieving robust event-level visual question answering. The datasets, code, and models are available at https://github.com/HCPLab-SYSU/CMCIR.
Framework
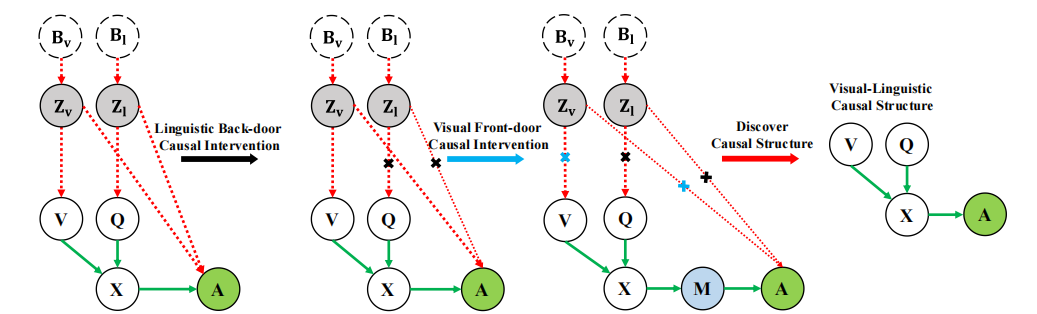
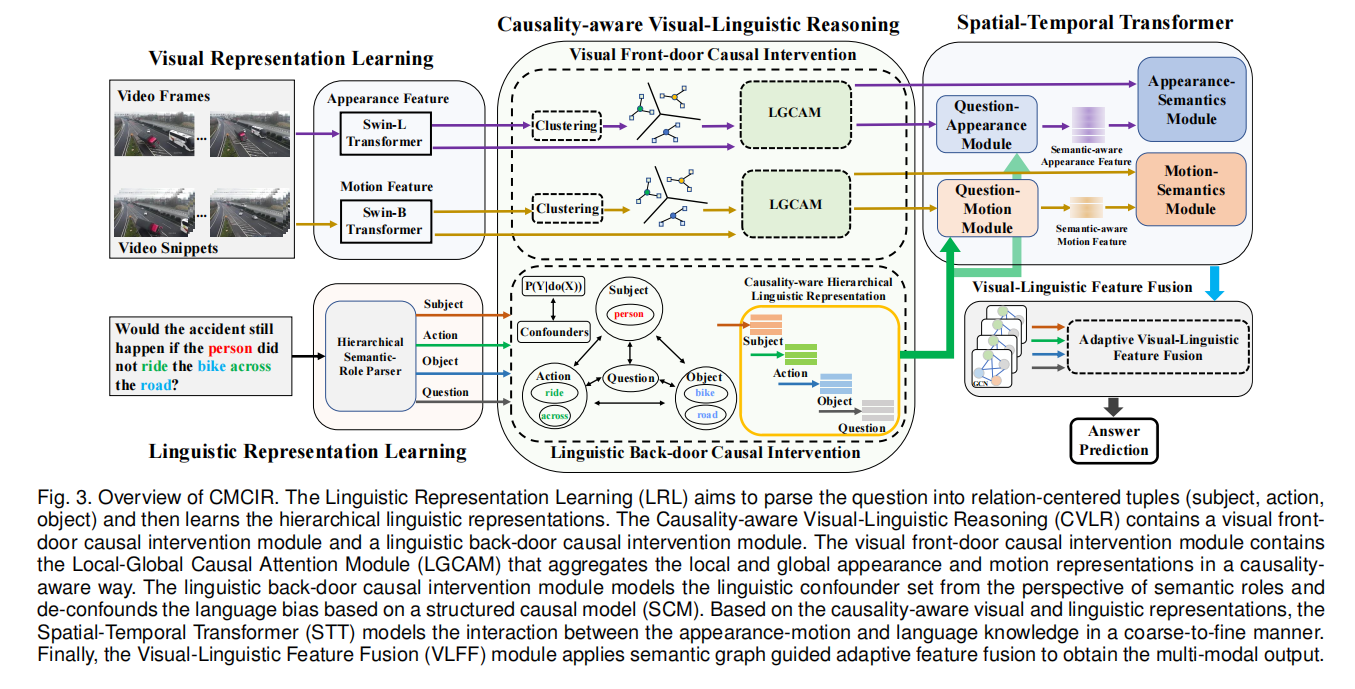
We propose a causality-aware event-level visual question answering framework named Cross-Modal Causal RelatIonal Reasoning (CMCIR), to discover true causal structures via causal intervention on the integration of visual and linguistic modalities and achieve robust event-level visual question answeringperformance. To the best of our knowledge, we arethe first to discover cross-modal causal structures for the event-level visual question answering task.
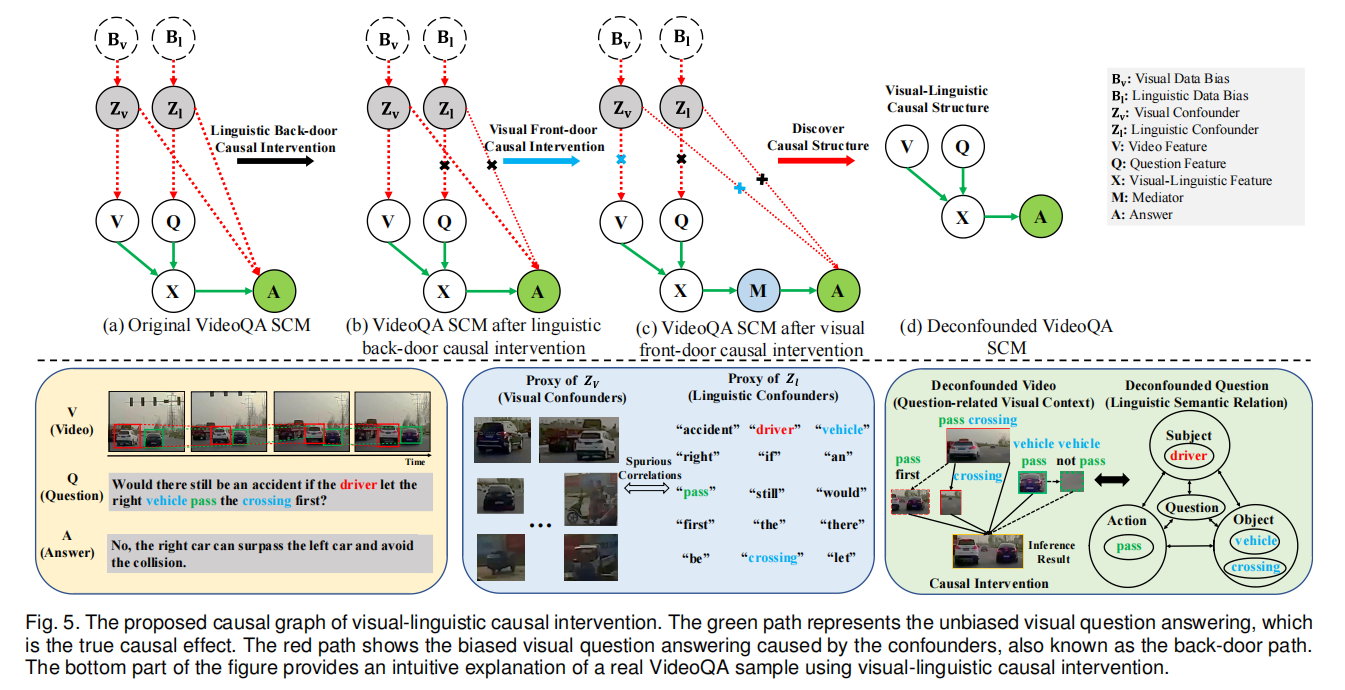
We introduce a linguistic back-door causal intervention module guided by linguistic semantic relations to mitigate the spurious biases and uncover the causal dependencies within the linguistic modality. To disentangle the visual spurious correlations, we propose a Local-Global Causal Attention Module (LGCAM) that aggregates the local and global visual representations by front-door causal intervention.
We construct a Spatial-Temporal Transformer (STT) that models the multi-modal co-occurrence interactions between the visual and linguistic knowledge, to discover the fifine-grained interactions among linguistic semantics, spatial, and temporal representations.
To adaptively fuse the causality-aware visual and linguistic features, we introduce a Visual-Linguistic Feature Fusion (VLFF) module that leverages the hierarchical linguistic semantic relations to learn the global semantic-aware visual-linguistic features.
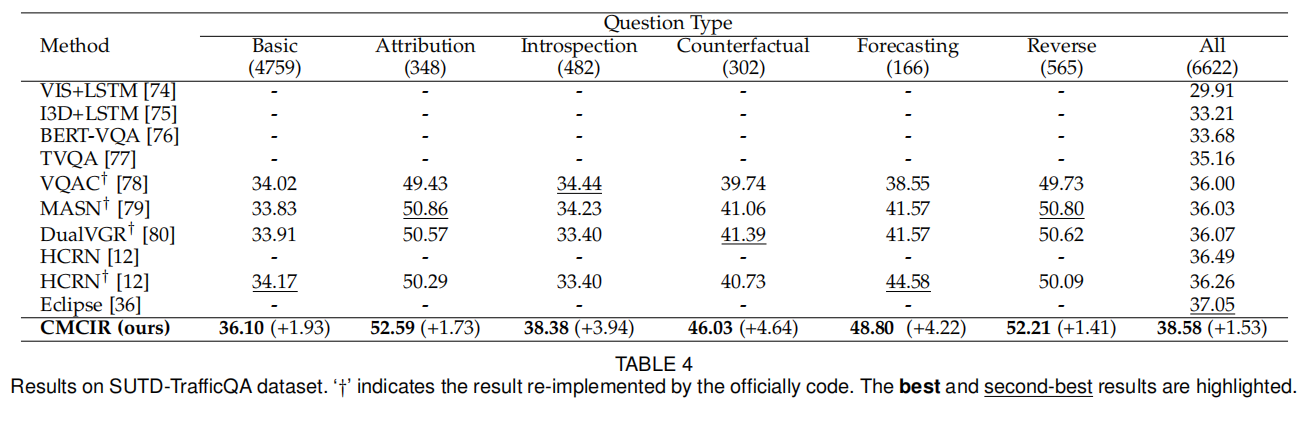
Extensive experiments on SUTD-TraffificQA, TGIF-QA, MSVD-QA, and MSRVTT-QA datasets show the effectiveness of our CMCIR for discovering visuallinguistic causal structures and achieving promising event-level visual question answering performance.
Experiment

Conclusion
We propose an event-level visual question answering framework named Cross-Modal Causal RelatIonal Reasoning (CMCIR), to mitigate the spurious correlations and discover the causal structures for visual-linguistic modality. To uncover causal structures for visual and linguistic modalities, we propose a Causality-aware Visual-Linguistic Reasoning (CVLR) module, which leverages front-door and back-door causal interventions to disentangle the spurious correlations between visual and linguistic modalities. Extensive experiments on the event-level urban dataset SUTD-TraffificQA and three benchmark real-world datasets TGIF-QA, MSVD-QA, and MSRVTT-QA demonstrate the effectiveness of CMCIR in discovering visual-linguistic causal structures and achieving robust event-level visual question answering. Unlike previous methods that simply eliminate either the linguistic or visual bias without considering cross-modal causality discovery, we apply front-door and back-door causal intervention modules to discover cross-modal causal structures. We believe our work could shed light on exploring new boundaries of causal analysis in vision-language tasks (Causal-VLReasoning1 ). In the future, we will further explore more comprehensive causal discovery methods to discover the question-critical scene elements in event-level visual question answering, particularly in the temporal aspect. By further exploiting the fifine-grained temporal consistency in videos, we may achieve a model that pursues better causality. Additionally, we can leverage object-level causal relational inference to alleviate the spurious correlations from object-centric entities. Besides, we will incorporate external expert knowledge into our intervention process. Moreover, due to the inherent unobservable nature of properties, how to quantitatively analyze spurious correlations within datasets remains a challenging problem. Thus, we will discover more intuitive and reasonable metrics to compare the effectiveness of different methods in reducing spurious correlations.
Acknowledgement
This work is supported in part by the National Key R&D Program of China under Grant No.2021ZD0111601, in part by the National Natural Science Foundation of China under Grant No.62002395 and No.61976250, in part by the Guangdong Basic and Applied Basic Research Foundation under Grant No.2023A1515011530, No.2021A1515012311 and No.2020B1515020048, and in part by the Guangzhou Science and Technology Planning Project under Grant No. 2023A04J2030.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab