

Abstract
Aiming at facilitating a real-world, ever-evolving and scalable autonomous driving system, we present a large-scale dataset for standardizing the evaluation of different self-supervised and semi-supervised approaches by learning from raw data, which is the first and largest dataset to date. Existing autonomous driving systems heavily rely on ‘perfect’ visual perception models (i.e., detection) trained using extensive annotated data to ensure safety. However, it is unrealistic to elaborately label instances of all scenarios and circumstances (i.e., night, extreme weather, cities) when deploying a robust autonomous driving system. Motivated by recent advances of self-supervised and semi-supervised learning, a promising direction is to learn a robust detection model by collaboratively exploiting large-scale unlabeled data and few labeled data. Existing datasets (i.e., BDD100K, Waymo) either provide only a small amount of data or covers limited domains with full annotation, hindering the exploration of large-scale pre-trained models. Here, we release a Large-Scale 2D Self/semi-supervised Object Detection dataset for Autonomous driving, named as SODA10M, containing 10 million unlabeled images and 20K images labeled with 6 representative object categories. To improve diversity, the images are collected within 27833 driving hours under different weather conditions, periods and location scenes of 32 different cities. We provide extensive experiments and deep analyses of existing popular self-supervised and semi-supervised approaches, and give some interesting findings in autonomous driving scope. Experiments show that SODA10M can serve as a promising pre-training dataset for different selfsupervised learning methods, which gives superior performance when fine-tuning with different downstream tasks (i.e. detection, semantic/instance segmentation) in autonomous driving domain. This dataset has been used to hold the ICCV2021 SSLAD challenge. More information can refer to https://soda-2d.github.io.
Examples

Comparison with existing driving datasets
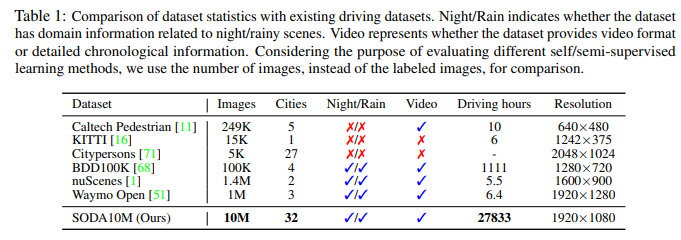
Benchmark
As SODA10M is regarded as a new autonomous driving dataset, we provide the fully supervised baseline results based on several representative one-stage and two-stage detectors. With the massive amount of unlabeled data, we carefully select most representative self-supervised and semi-supervised methods (Fig. 3) and study the generalization ability of those methods on SODA10M, and further provide some interesting findings under autonomous driving scope.
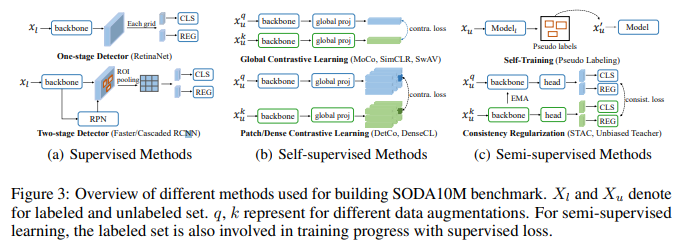
Conclusion
Focusing on self-supervised and semi-supervised learning, we present SODA10M, a large-scale 2D autonomous driving dataset that provides a large amount of unlabeled data and a small set of high-quality labeled data collected from various cities under diverse weather conditions, periods and location scenes. Compared with the existing self-driving datasets, SODA10M is the largest in scale and obtained in much more diversity. Furthermore, we build a benchmark for self-supervised and semi-supervised learning in autonomous driving scenarios and show that SODA10M can serve as a promising dataset for training and evaluating different self/semi-supervised learning methods. Inspired by the experiment results, we summarize some guidance for dealing with SODA10M dataset. For self-supervised learning, method which focuses on dealing with multi-instance consistency should be proposed for driving scenarios. For semi-supervised learning, domain adaptation can be one of the most important topics. For both self and semi-supervised learning, efficient training with high-resolution and large-scale images will be promising for future research. We hope that SODA10M can promote the exploration and standardized evaluation of advanced techniques for robust and real-world autonomous driving systems.
Acknowledgement
We thank our two data suppliers, named Testin (http://www.testin.cn) and Speechocean (4 http://en.speechocean.com, collected from King-IM-055), for helping us collect and annotate SODA10M dataset
References
[1] Han J, Liang X, Xu H, et al. SODA10M: A Large-Scale 2D Self/Semi-Supervised Object Detection Dataset for Autonomous Driving[C]//Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021.
[2] 重磅!华为诺亚方舟实验室联合中山大学发布最新一代2D自动驾驶数据集SODA10M数据集!规模庞大、多样性、泛化能力强 https://zhuanlan.zhihu.com/p/400182954
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab