
Abstract
Grounding referring expressions in images aims to locate the object instance in an image described by a referring expression. It involves a joint understanding of natural language and image content, and is essential for a range of visual tasks related to human-computer interaction. As a language-to-vision matching task, the core of this problem is to not only extract all the necessary information (i.e., objects and the relationships among them) in both the image and referring expression, but also make full use of context information to align cross-modal semantic concepts in the extracted information. Unfortunately, existing work on grounding referring expressions fails to accurately extract multi-order relationships from the referring expression and associate them with the objects and their related contexts in the image. In this paper, we propose a cross-modal relationship extractor (CMRE) to adaptively highlight objects and relationships (spatial and semantic relations) related to the given expression with a cross-modal attention mechanism, and represent the extracted information as a language-guided visual relation graph. In addition, we propose a Gated Graph Convolutional Network (GGCN) to compute multimodal semantic contexts by fusing information from different modes and propagating multimodal information in the structured relation graph. Experimental results on three common benchmark datasets show that our Cross-Modal Relationship Inference Network, which consists of CMRE and GGCN, significantly surpasses all existing state-of-the-art methods.
Framework
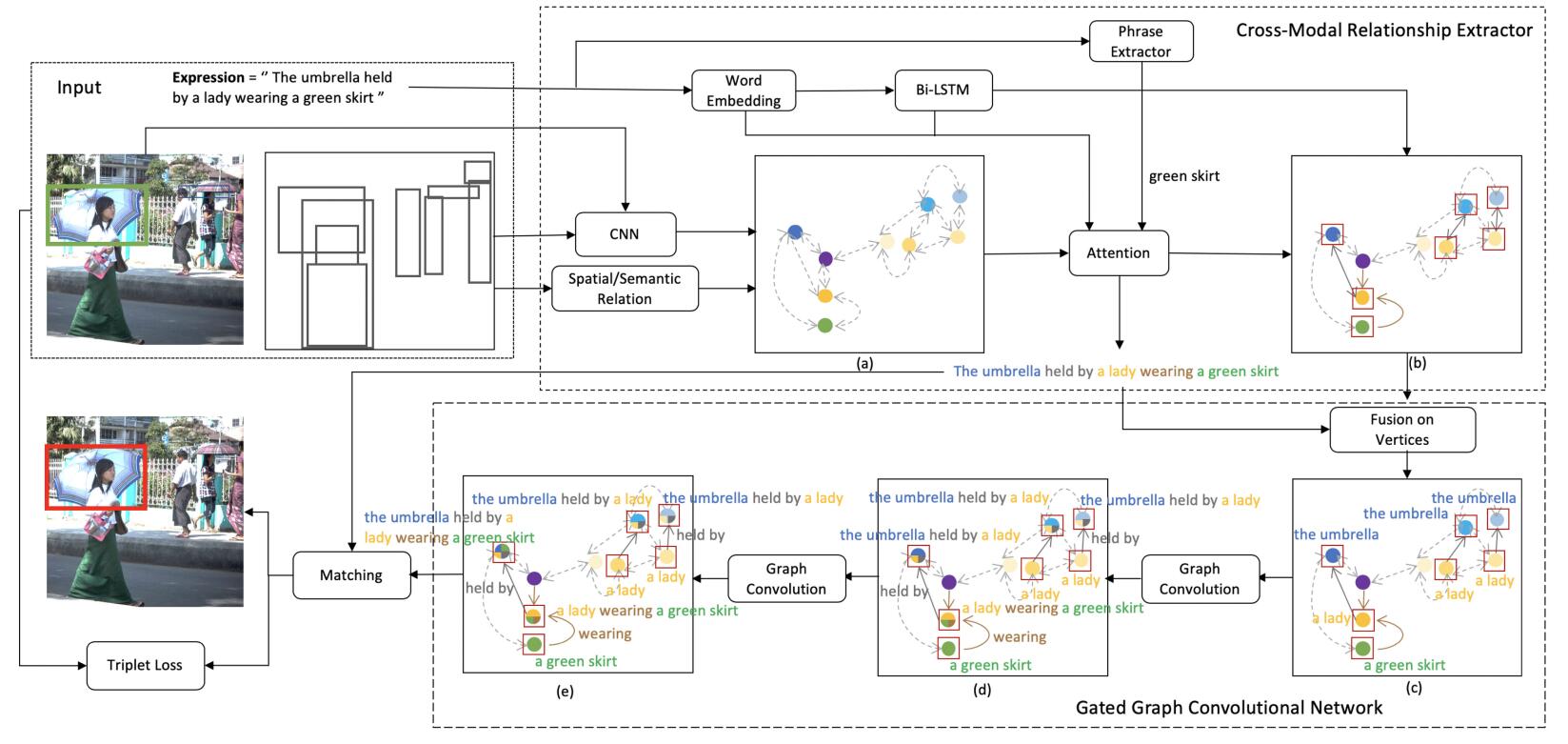
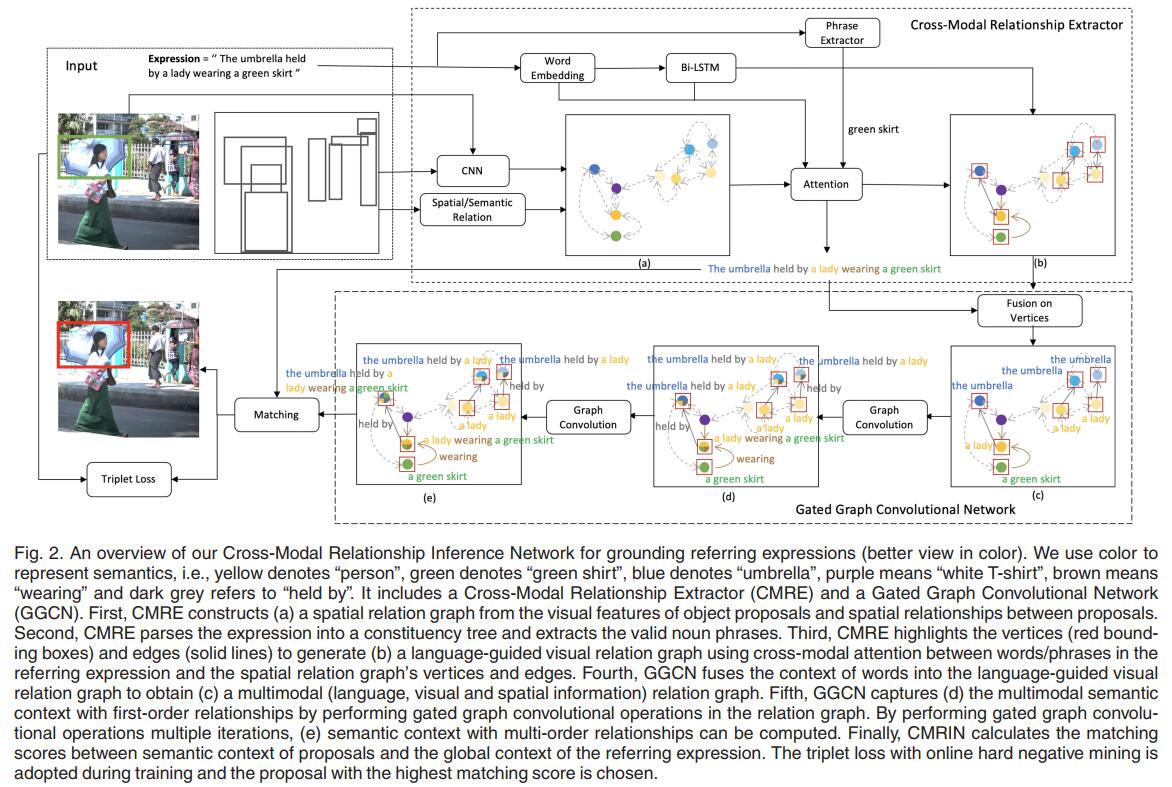
Our proposed Cross-Modal Relationship Inference Network (CMRIN) relies on relationships among objects and context captured in the multimodal relation graph to choose the target object proposal in the input image referred to by the input expression. First, CMRIN constructs a languageguided visual relation graph using the Cross-Modal Relationship Extractor. Second, it captures multimodal context from the relation graph based on the Gated Graph Convolutional Network. Finally, a matching score is computed for each object proposal according to its multimodal context and the context of the input expression. The overall architecture of our CMRIN for grounding referring expressions is illustrated in Fig. 2.
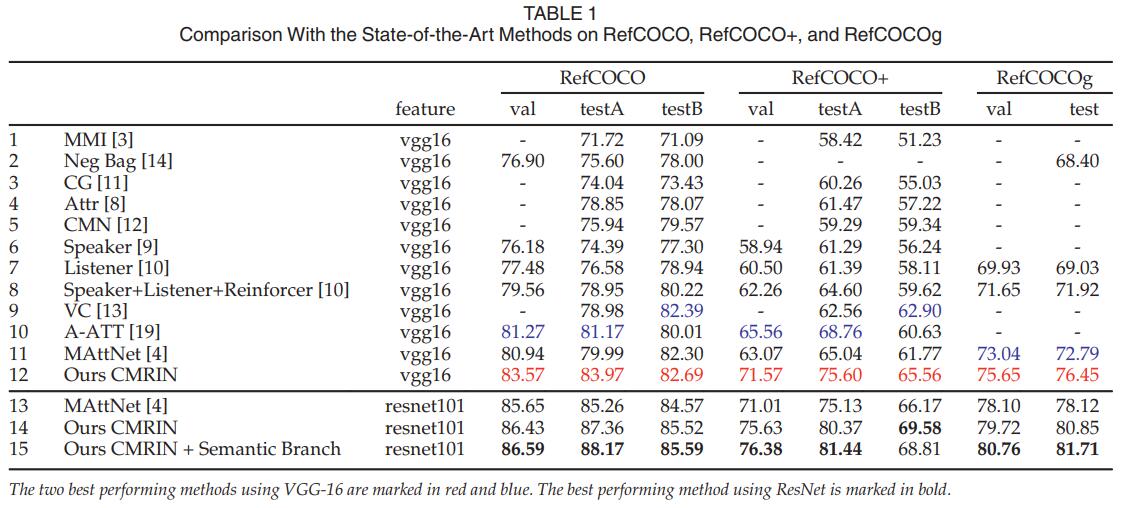
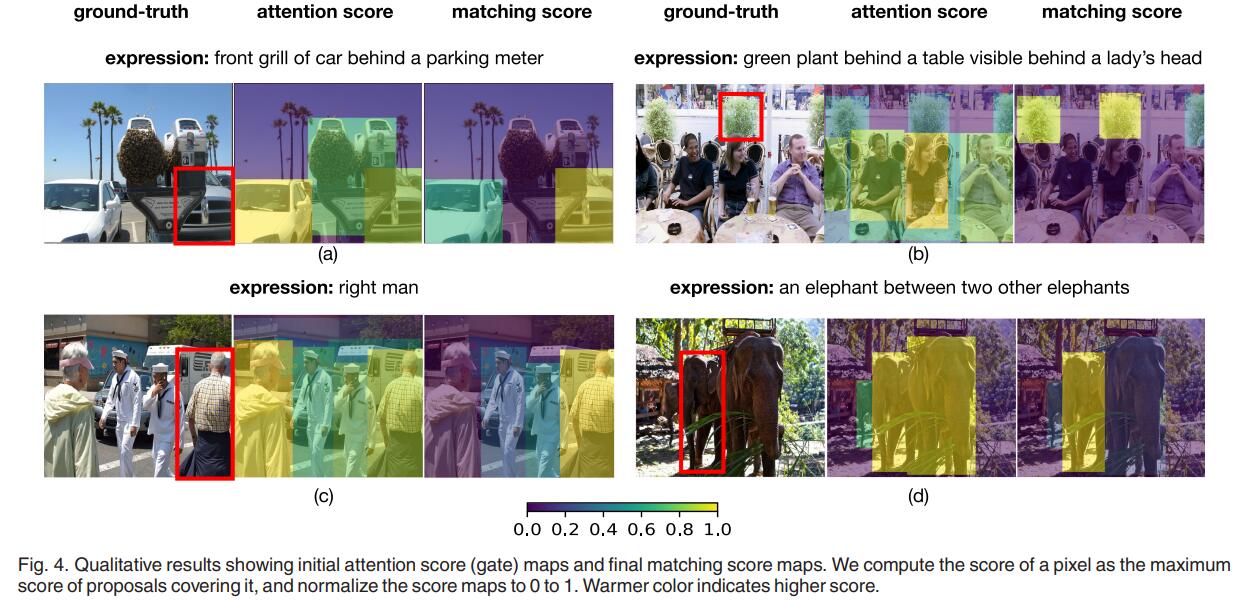
Experiment
Conclusion
In this paper, we focus on the task of referring expression comprehension in images, and demonstrate that a feasible solution for this task needs to not only extract all the necessary information in both the image and referring expressions, but also compute and represent multimodal contexts for the extracted information. In order to overcome the challenges, we propose an end-to-end Cross-Modal Relationship Inference Network (CMRIN), which consists of a Cross-Modal Relationship Extractor (CMRE) and a Gated Graph Convolutional Network (GGCN). CMRE extracts all the required information adaptively for constructing language-guided visual relation graphs with cross-modal attention. GGCN fuses information from different modes and propagates the fused information in the language-guided relation graphs to obtain multi-order semantic contexts. Experimental results on three commonly used benchmark datasets show that our proposed method outperforms all existing state-of-the-art methods.
Acknowledgement
This work was supported in part by the National Key Research and Development Program of China under Grant No. 2019YFC0118100, the National Natural Science Foundation of China under Grant No. 61976250 and No. 61702565, the Science and Technology Program of Guangdong Province under Grant No. 2017B010116001 and the Hong Kong PhD Fellowship. This paper was presented at the IEEE Conference CVPR, 2019[1].
References
[1]S. Yang, G. Li, and Y. Yu, “Cross-modal relationship inference for grounding referring expressions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 4145–4154.
[2]C. Deng, Q. Wu, Q. Wu, F. Hu, F. Lyu, and M. Tan, “Visual grounding via accumulated attention,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 7746–7755
[3]L. Yu et al., “MAttNet: Modular attention network for referring expression comprehension,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 1307–1315.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab