

Abstract
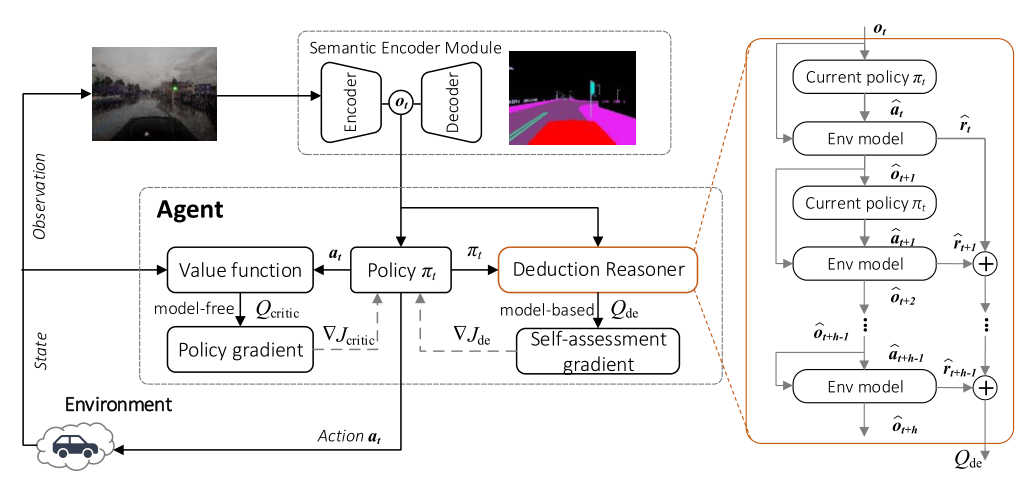
Existing deep reinforcement learning (RL) are devoted to research applications on video games, e.g., The Open Racing Car Simulator (TORCS) and Atari games. However, it remains under-explored for vision-based autonomous urban driving navigation (VB-AUDN). VB-AUDN requires a sophisticated agent working safely in structured, changing, and unpredictable environments; otherwise, inappropriate operations may lead to irreversible or catastrophic damages. In this work, we propose a deductive RL (DeRL) to address this challenge. A deduction reasoner (DR) is introduced to endow the agent with ability to foresee the future and to promote policy learning. Specifically, DR first predicts future transitions through a parameterized environment model. Then, DR conducts self-assessment at the predicted trajectory to perceive the consequences of current policy resulting in a more reliable decision-making process. Additionally, a semantic encoder module (SEM) is designed to extract compact driving representation from the raw images, which is robust to the changes of the environment. Extensive experimental results demonstrate that DeRL outperforms the state-of-the-art model-free RL approaches on the public CAR Learning to Act (CARLA) benchmark and presents a superior performance on success rate and driving safety for goal-directed navigation.
Framework
Experiment
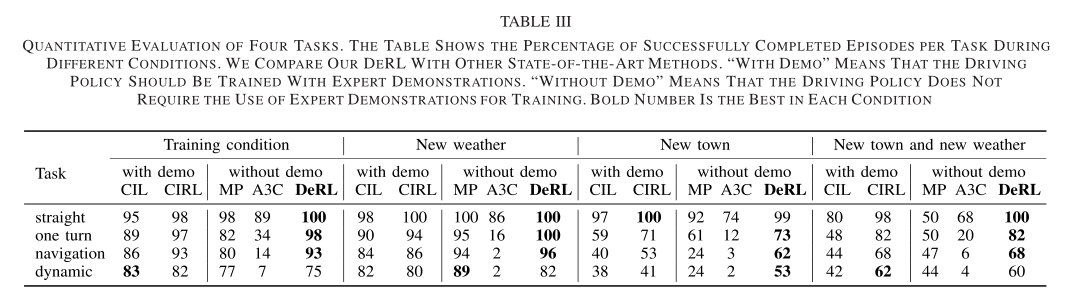
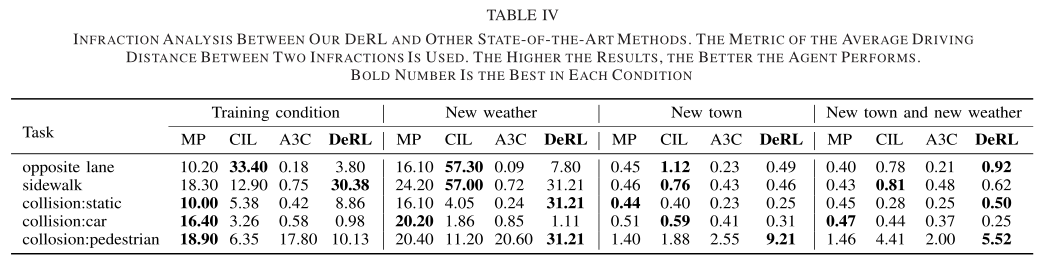
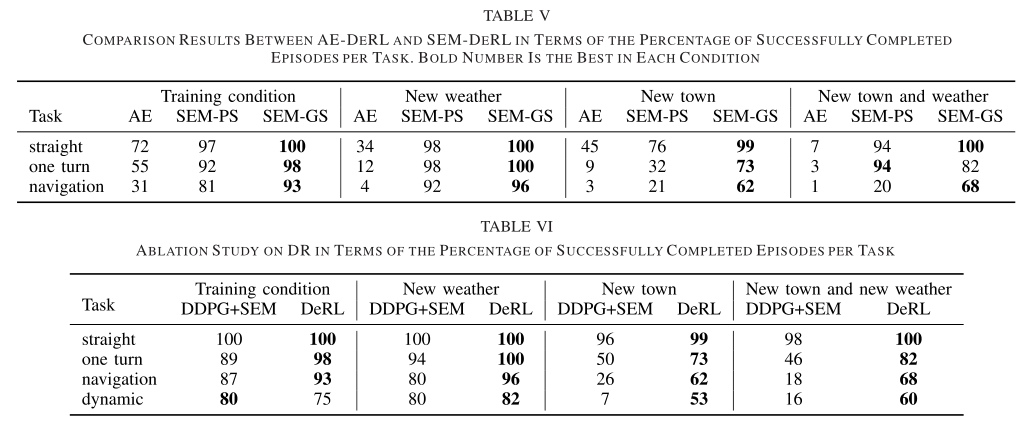
Video
Conclusion
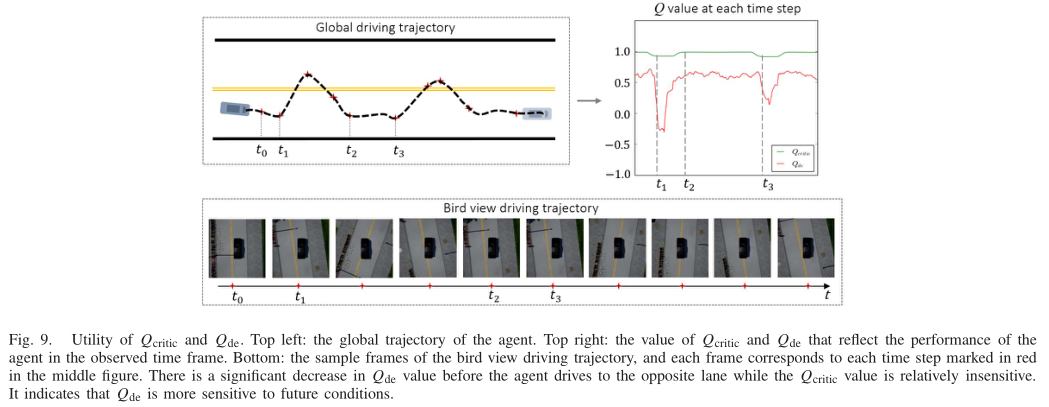
In this article, we propose a DeRL method, named DeRL, to address the challenging problems of vision-based autonomous urban driving. Our DeRL embeds a DR into DDPG to resolve the sample inefficiency problem that is intractable in RL research. With the help of DR, our DeRL agent is able to foresee future trajectories from the current state. It also has an appealing property for self-assessing about future actions and states and reactively navigating for an effective response to unforeseen and complex circumstances. In addition, we deploy a novel SEM to learn effective intermediate representations from raw images observed in various driving scenes. Extensive experimental results demonstrate that our DeRL improves the performance of DDPG on vision-based autonomous urban driving tasks both in terms of the success rate and traffic infraction metric. Finally, inspired by Ye et al. , we plan to equip our DR with meta RL (MRL) to transfer driving policy from simulation to the real world.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab