
Abstract
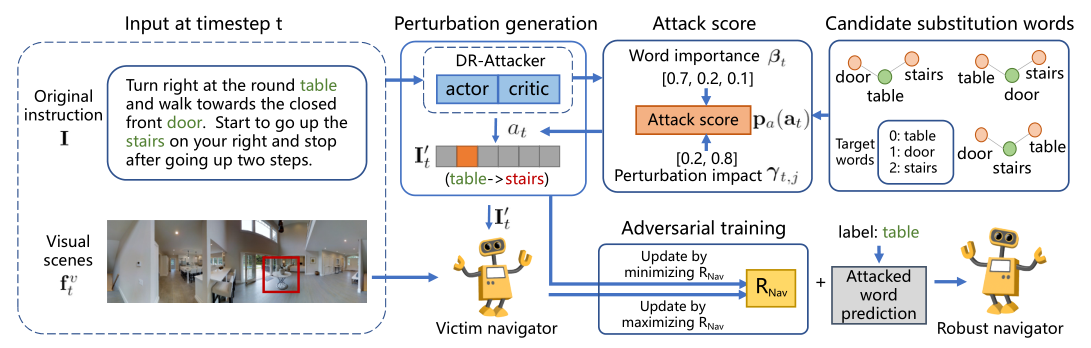
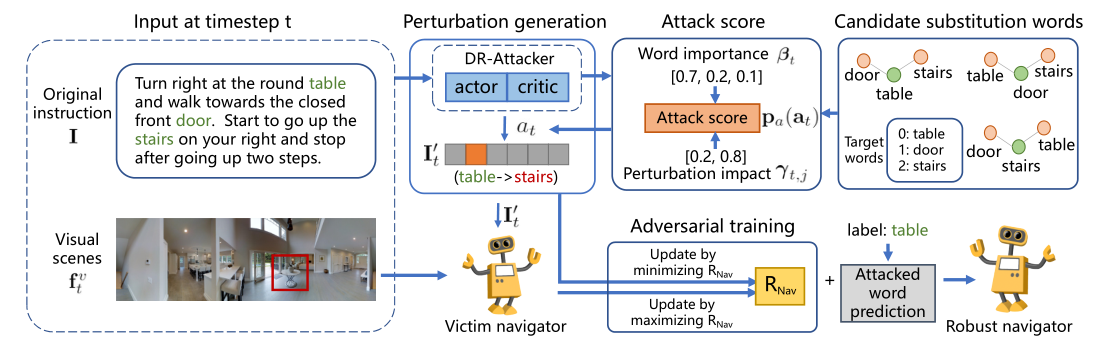
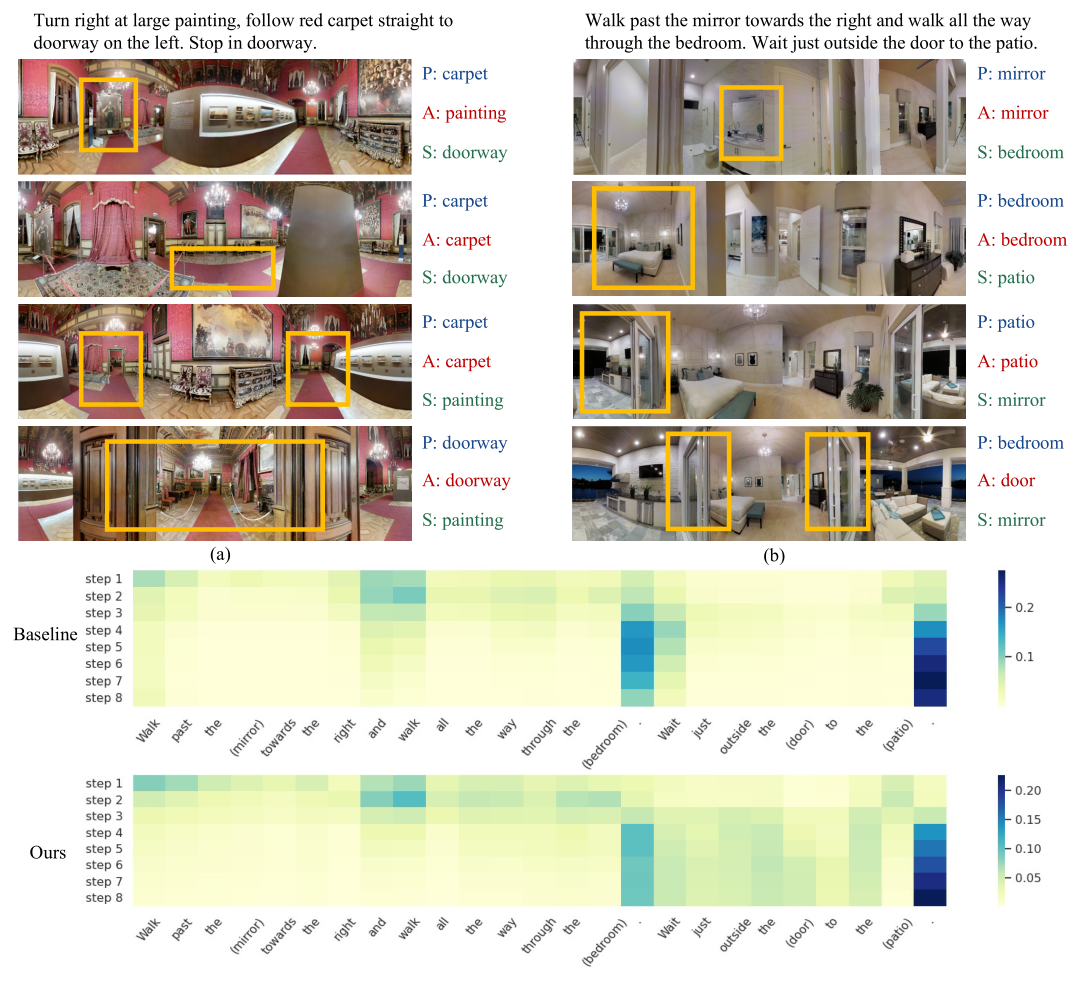
Language instruction plays an essential role in the natural language grounded navigation tasks. However, navigators trained with limited human-annotated instructions may have difficulties in accurately capturing key information from the complicated instruction at different timesteps, leading to poor navigation performance. In this paper, we exploit to train a more robust navigator which is capable of dynamically extracting crucial factors from the long instruction, by using an adversarial attacking paradigm. Specifically, we propose a Dynamic Reinforced Instruction Attacker (DR-Attacker), which learns to mislead the navigator to move to the wrong target by destroying the most instructive information in instructions at different timesteps. By formulating the perturbation generation as a Markov Decision Process, DR-Attacker is optimized by the reinforcement learning algorithm to generate perturbed instructions sequentially during the navigation, according to a learnable attack score. Then, the perturbed instructions, which serve as hard samples, are used for improving the robustness of the navigator with an effective adversarial training strategy and an auxiliary self-supervised reasoning task. Experimental results on both Vision-and-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks show the superiority of our proposed method over state-of-the-art methods. Moreover, the visualization analysis shows the effectiveness of the proposed DR-Attacker, which can successfully attack crucial information in the instructions at different timesteps.
Framework
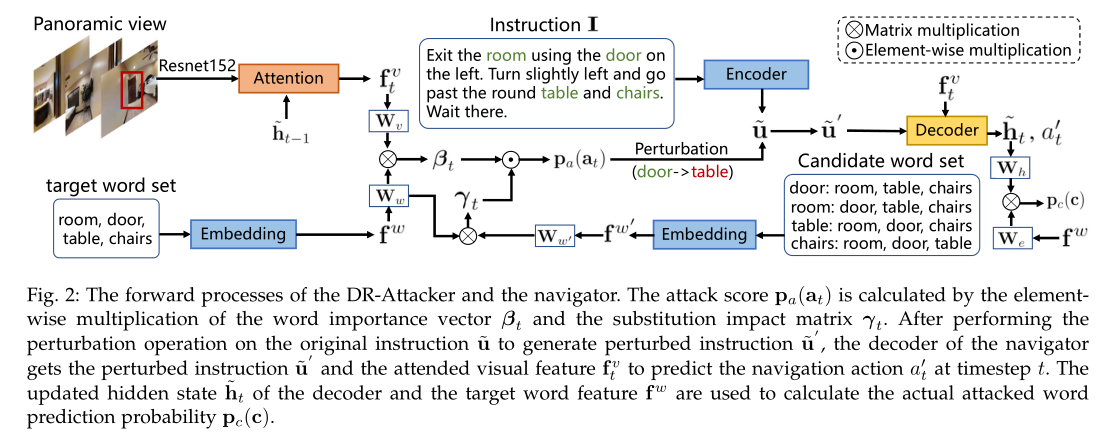
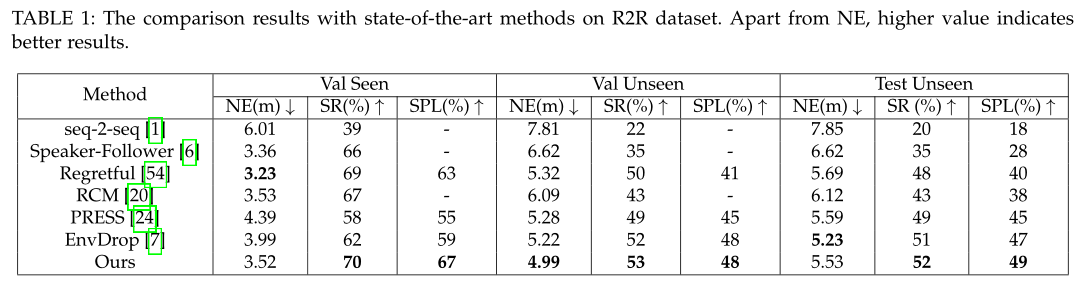
Experiment

Conclusion
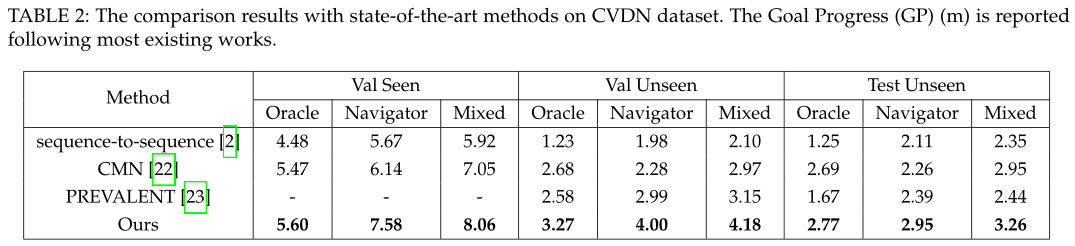
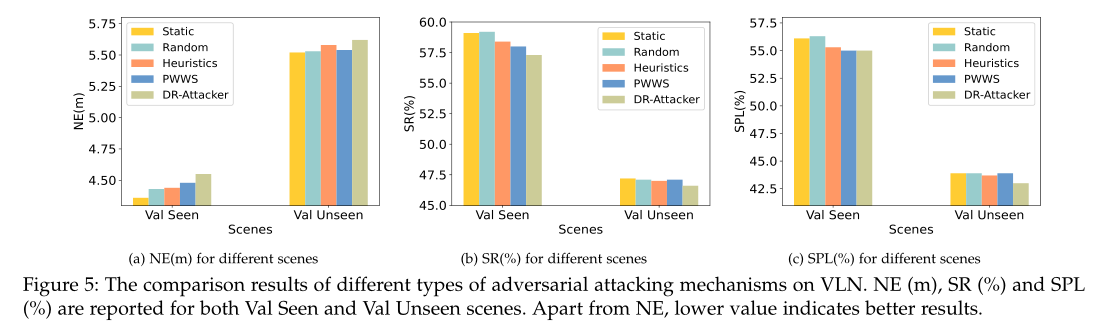
In this work, we propose Dynamic Reinforced Instruction Attacker (DR-Attacker) for the natural language grounded visual navigation tasks. By formulating the perturbation generation using the RL framework, DR-Attacker can be optimized iteratively to capture the crucial parts in instructions and generate meaningful adversarial samples. Through adversarial training using perturbed instructions, the robustness of the navigator can be effectively enhanced with an auxiliary self-supervised reasoning task. Experiments on both VLN and NDH tasks show the effectiveness of the proposed method.
In the future, we plan to improve the training strategy of the proposed instruction attacker and exploit to design more effective attacks on the navigation instruction. Moreover, we would like to develop multi-modality adversarial attacks for the embodied navigation task to further verify and improve the robustness of the navigator.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab