
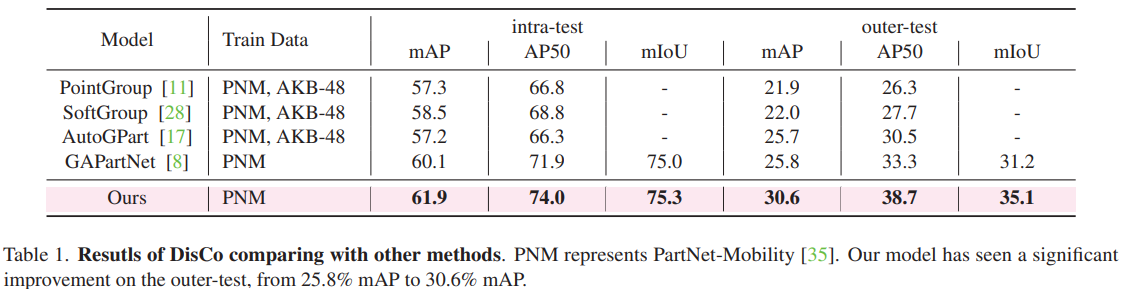
Abstract
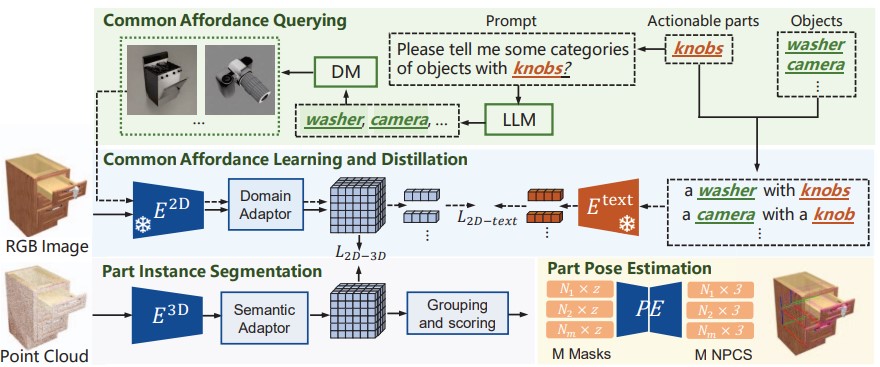
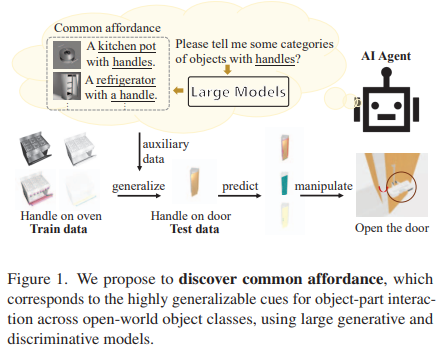
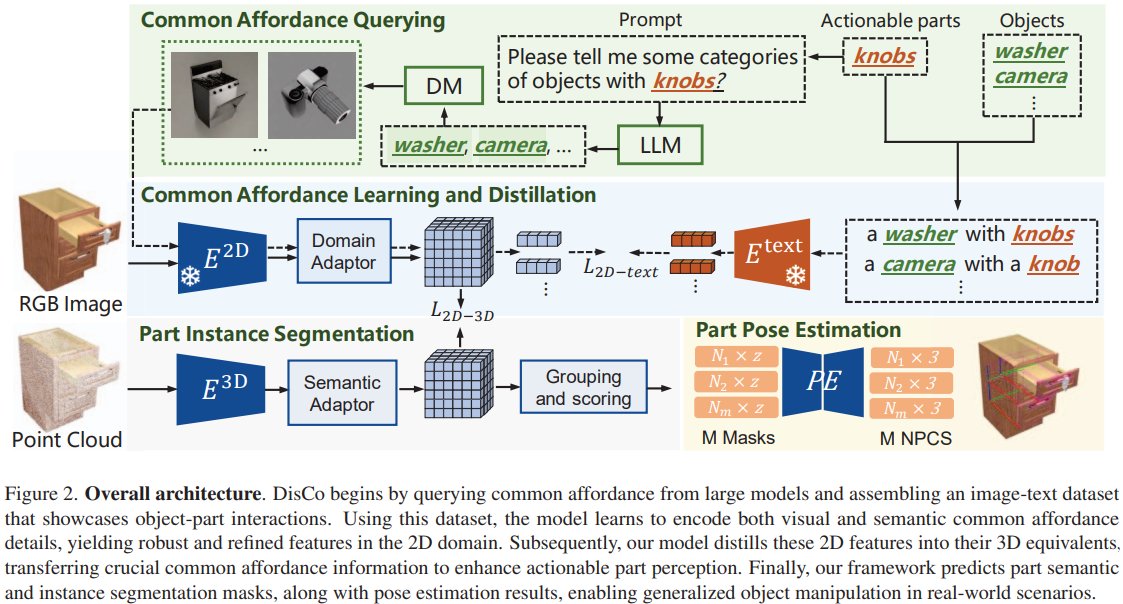
Actionable part perception for robotic object manipulation needs to perceive parts over open-world object categories within 3D space, which is challenging as the appearance of the same part on different objects varies greatly. It is frequently observed that despite the huge intra-class difference in appearance, the parts share common interactive functions over different objects, i.e., common affordance. According to this observation, we propose DisCo, a novel technique that Discovers Common affordance information from powerful large models for guiding the actionable part perception across open-world objects. Specifically, we first use a large language model to identify the object names that each part potentially belongs to and a text-to-image generative model to generate image examples for the queried objects, constructing image-text paired data that indicate visual and semantic information of common affordance. Then, our model encodes the common affordance information by learning to pair the object-part images with their text descriptions. Subsequently, the 2D-pixel features are distilled into 3D space, thus the 3D point features are enriched with not only the semantic information of open-set objects but also the common affordance information which is highly generalizable. Finally, a segmentation head and a pose regression network are developed to predict more accurate results of part segmentation and pose estimation, improving the success rate of robotic object manipulation. Extensive experiments show that our method outperforms existing methods on the part instance and semantic segmentation by significant margins of 4.8% mAp, 5.4% AP50, and 3.9% mIoU on the unseen object categories.
Framework
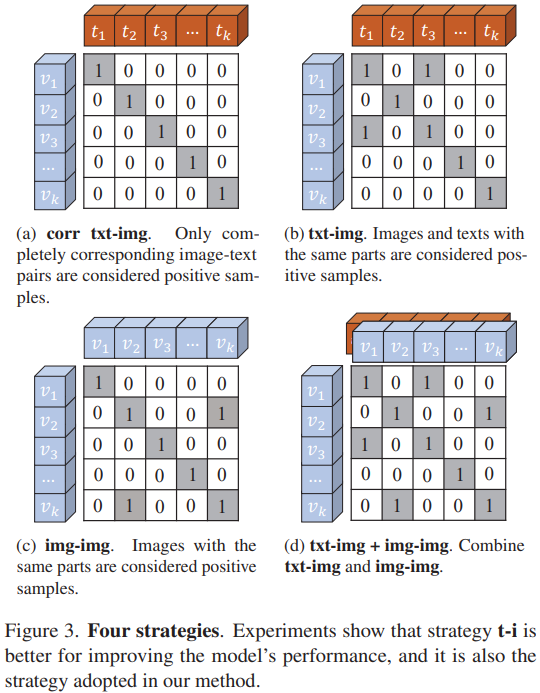
Experiment

Conclusion
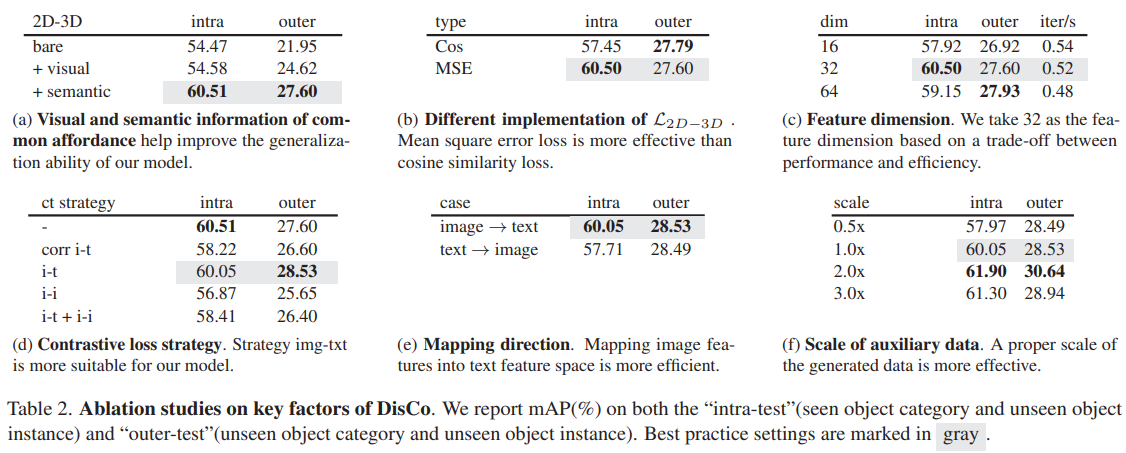
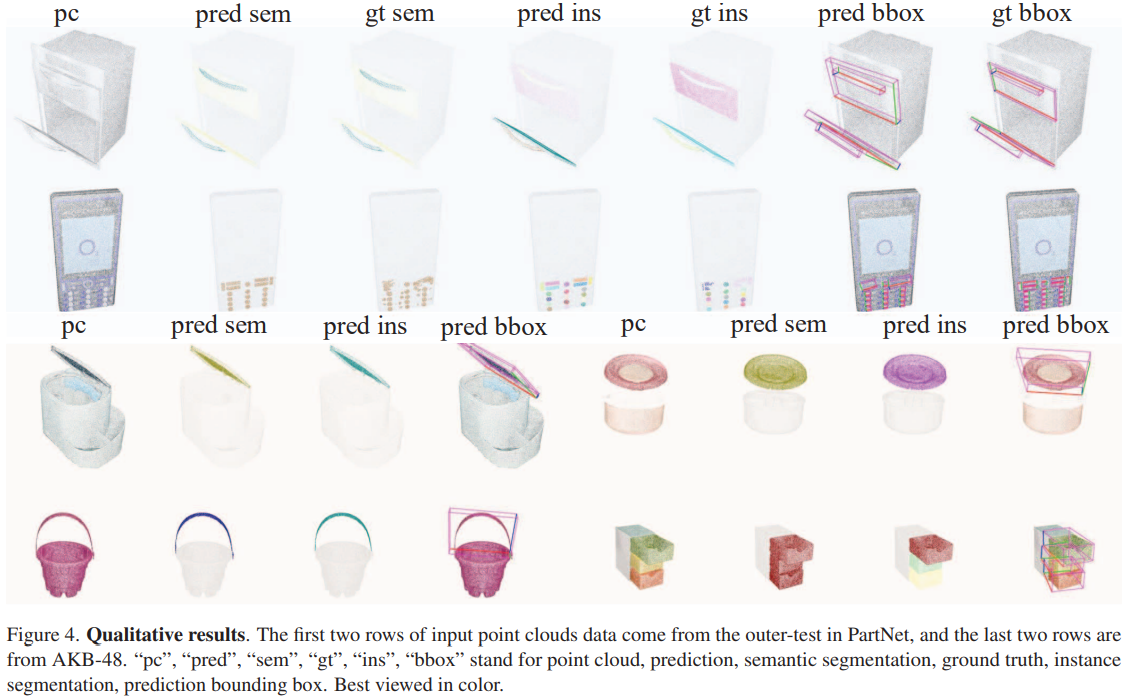
We introduce DisCo, a method that queries, learns, and distills common affordance to create robust and distinctive representations for perceiving actionable parts. Leveraging a Large Language Model and a diffusion model, DisCo harnesses rich visual and functional interaction details to capture common affordance information among objects’ actionable parts. This information is encoded into fine-grained image features and then distilled from 2D to 3D point features. Experimental results showcase DisCo’s exceptional generalization capabilities and highlight its substantial impact on enhancing actionable part perception, thereby improving open-world object manipulation.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab