
Abstract
Vision-and-Language Navigation (VLN), as a crucial research problem of Embodied AI, requires an embodied agent to navigate through complex 3D environments following natural language instructions. Recent research has highlighted the promising capacity of large language models (LLMs) in VLN by improving navigational reasoning accuracy and interpretability. However, their predominant use in an offline manner usually suffers from substantial domain gap between the VLN task and the LLM training corpus. This paper proposes a novel strategy called Navigational Chain-of-Thought (NavCoT), where we fulfill parameter-efficient in-domain training to enable self-guided navigational decision, leading to a significant mitigation of the domain gap in a cost-effective manner. Specifically, at each timestep, the LLM is prompted to forecast the navigational chain-of-thought by: 1) acting as a world model to imagine the next observation according to the instruction, 2) selecting the candidate observation that best aligns with the imagination, and 3) determining the action based on the reasoning from the prior steps. In this way, the action prediction can be effectively simplified benefiting from the disentangled reasoning. Through constructing formalized labels for training, the LLM can learn to generate desired and reasonable chain-of-thought outputs for improving the action decision. Experimental results across various training settings and popular VLN benchmarks (e.g., Room-to-Room (R2R), Room-across-Room (RxR), Room-for-Room (R4R)) show the significant superiority of NavCoT over the direct action prediction variants. Through simple parameter-efficient finetuning, our NavCoT outperforms a recent GPT4-based approach with ∼7% relative improvement on the R2R dataset. We believe that NavCoT will help unlock more task-adaptive and scalable LLM-based embodied agents, which are helpful for developing real-world robotics applications.
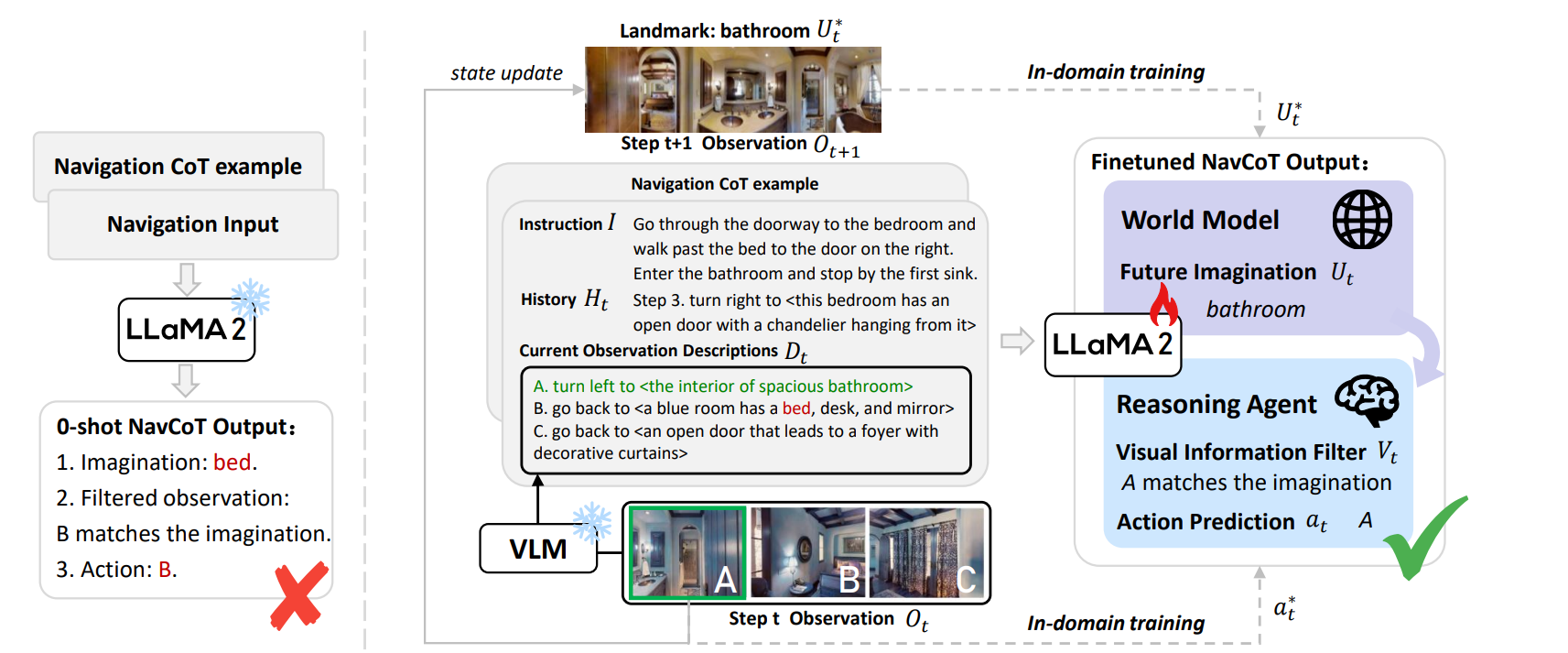
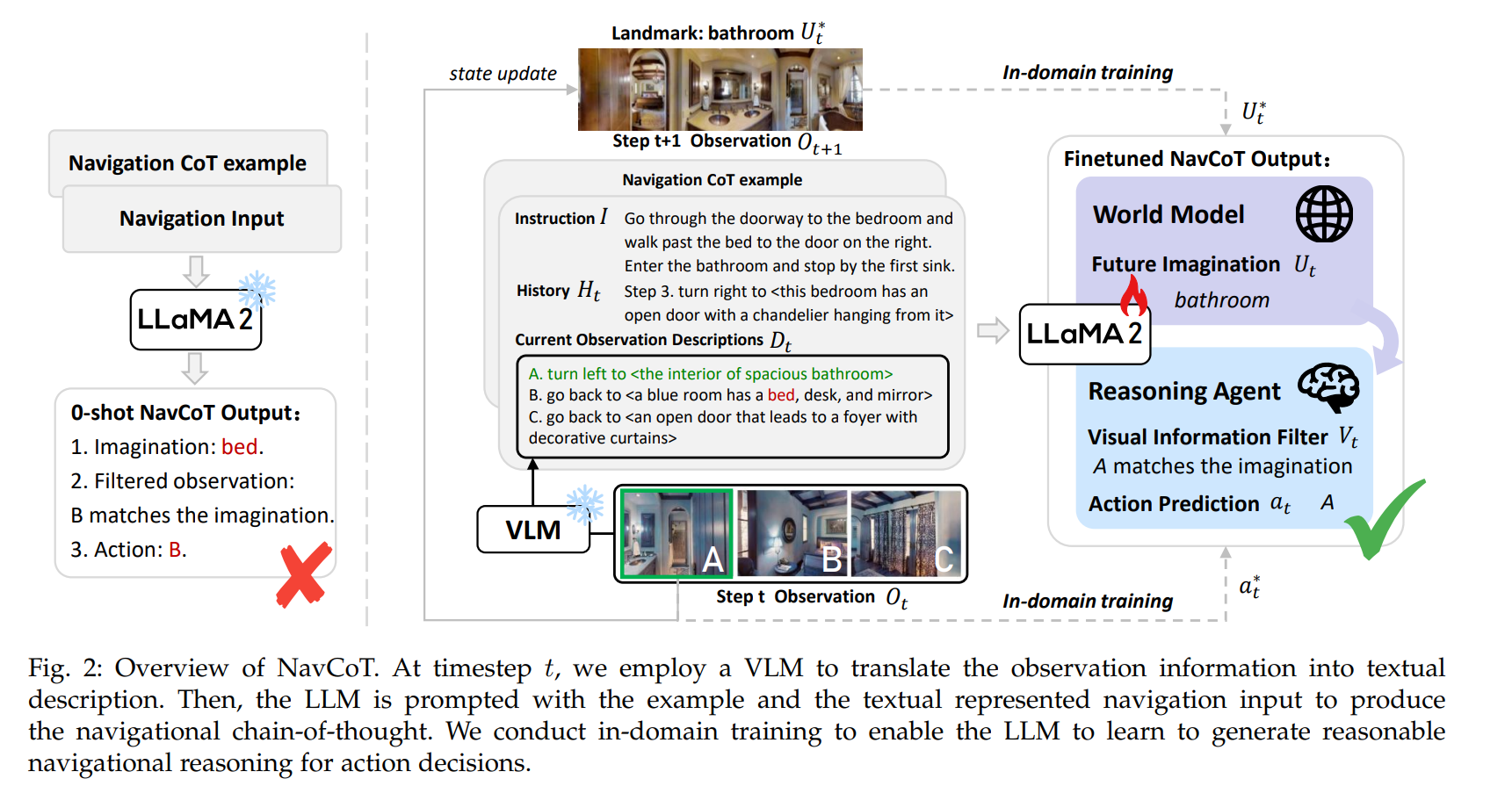
Framework


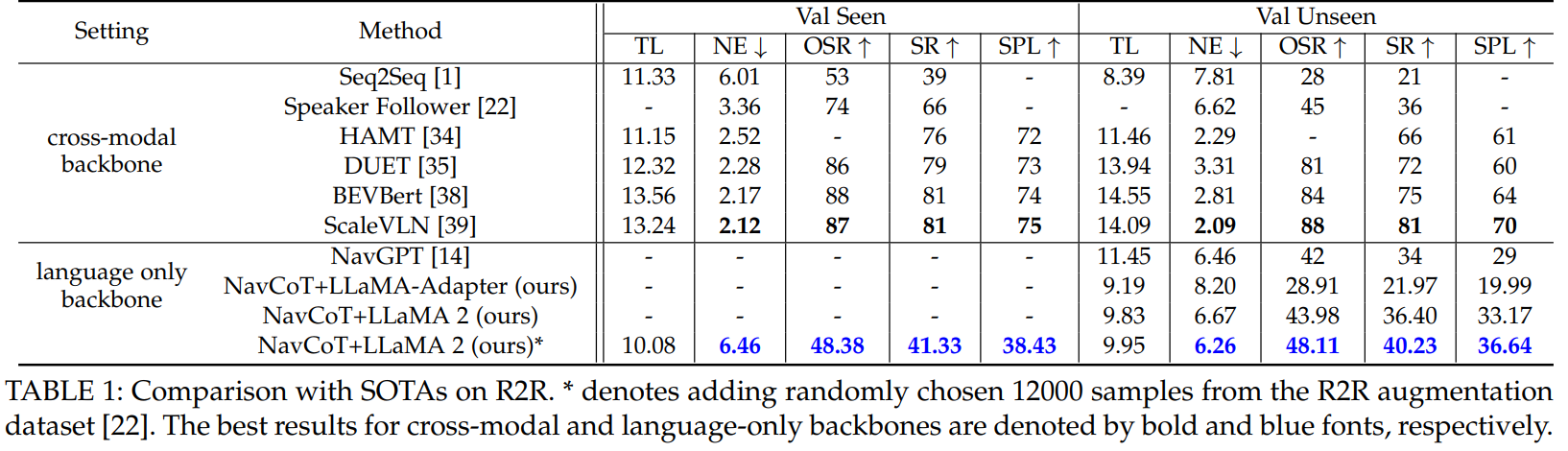
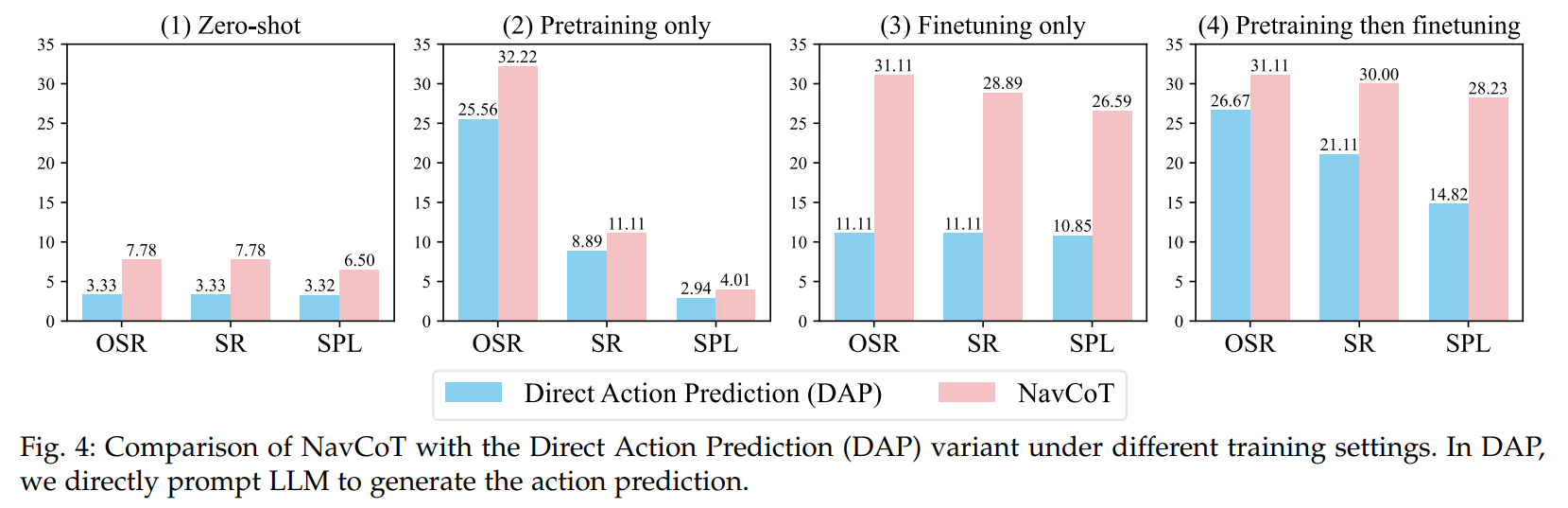
Experiment




Conclusion
This work introduces NavCoT, which fulfills parameterefficient in-domain training for enabling LLMs to perform self-guided navigational decisions. Experimental results show the great superiority of NavCoT over a recent highcost LLM-based VLN approach and direct action prediction variants. We believe that our method makes a solid step towards developing scalable LLM-based VLN approaches and provides a meaningful reference in designing trainable navigational reasoning generation strategies for improving both the accuracy and interpretability of action decision. Constrained by the detail information loss during the vision-totext transformation, the LLM may fail to make accurate decisions in some cases. Future direction includes introducing our NavCoT into powerful large vision-language models to further improve the navigation performance.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab