
Abstract
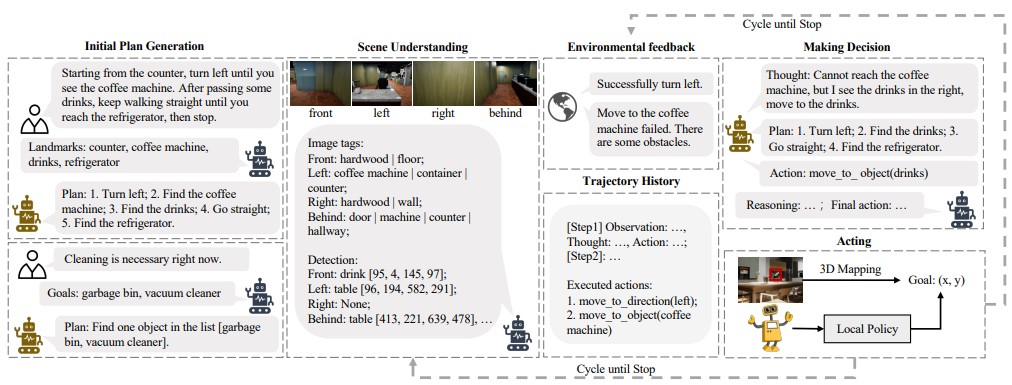
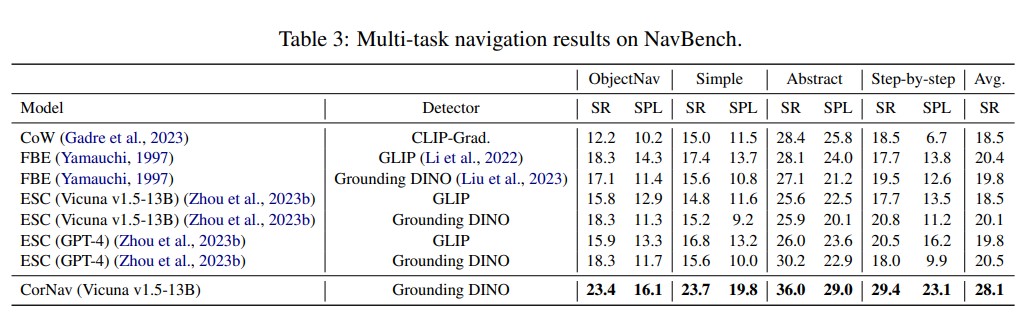
Understanding and following natural language instructions while navigating through complex, real-world environments poses a significant challenge for general-purpose robots. These environments often include obstacles and pedestrians, making it essential for autonomous agents to possess the capability of self-corrected planning to adjust their actions based on feedback from the surroundings. However, the majority of existing vision-andlanguage navigation (VLN) methods primarily operate in less realistic simulator settings and do not incorporate environmental feedback into their decision-making processes. To address this gap, we introduce a novel zero-shot framework called CorNav, utilizing a large language model for decision-making and comprising two key components: 1) incorporating environmental feedback for refining future plans and adjusting its actions, and 2) multiple domain experts for parsing instructions, scene understanding, and refining predicted actions. In addition to the framework, we develop a 3D simulator that renders realistic scenarios using Unreal Engine 5. To evaluate the effectiveness and generalization of navigation agents in a zero-shot multi-task setting, we create a benchmark called NavBench. Extensive experiments demonstrate that CorNav consistently outperforms all baselines by a significant margin across all tasks. On average, CorNav achieves a success rate of 28.1%, surpassing the best baseline’s performance of 20.5%.
Framework

Experiment

Conclusion
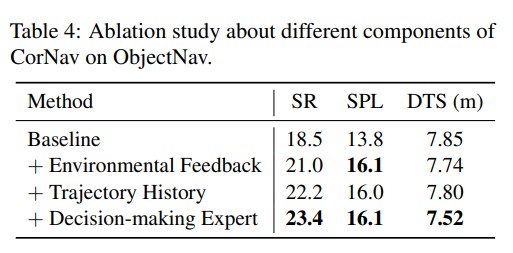
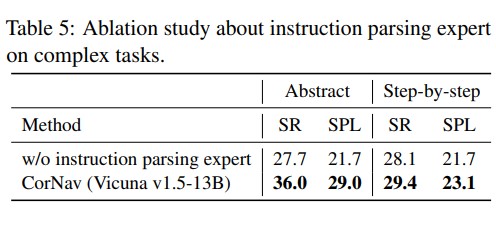
In this paper, we introduce CorNav, an innovative autonomous agent designed for zero-shot VLN. CorNav excels in leveraging environmental feedback to refine its plans in realistic scenarios, ensuring adaptability to dynamic surroundings. It also incorporates multiple domain experts for instruction parsing, scene comprehension, and action refinement. Our experimental results demonstrate CorNav’s significant performance advantages over baseline methods across various navigation tasks. Furthermore, we contribute to the field by developing a more realistic simulator powered by Unreal Engine 5. To evaluate our agent’s capabilities, we create NavBench, a comprehensive multi-task benchmark for open-set zero-shot VLN. Leveraging the powerful GPT-4, we generate and self-refine a range of free-form instructions for different tasks within NavBench, including goal-conditioned navigation, abstract object retrieval, and step-by-step instruction following. Our benchmark offers a challenging platform for assessing navigation methods.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab