
Abstract
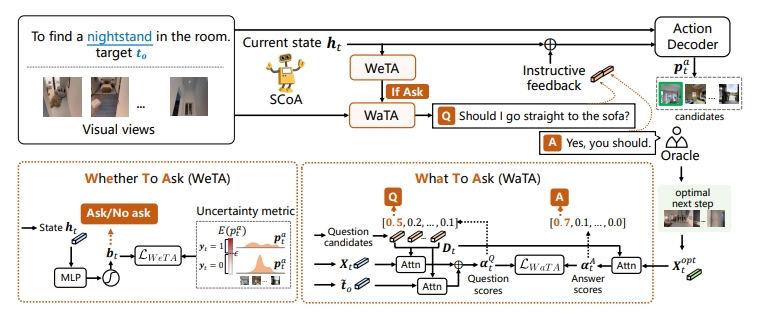
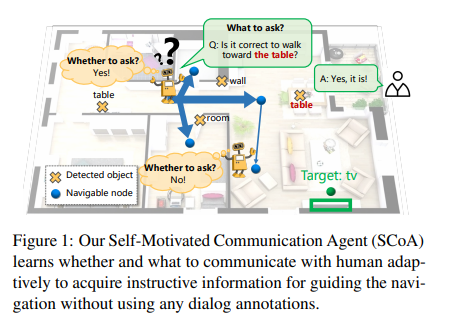
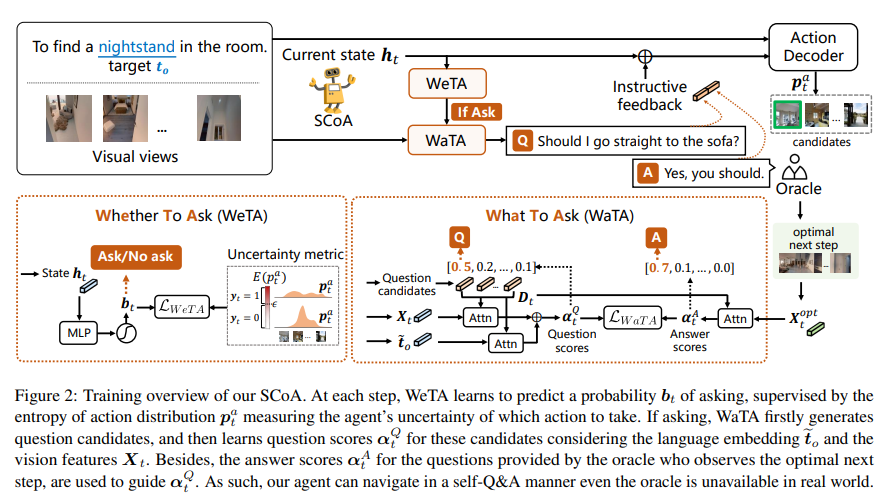
Vision-Dialog Navigation (VDN) requires an agent to ask questions and navigate following the human responses to find target objects. Conventional approaches are only allowed to ask questions at predefined locations, which are built upon expensive dialogue annotations, and inconvenience the real-word human-robot communication and cooperation. In this paper, we propose a Self-Motivated Communication Agent (SCoA) that learns whether and what to communicate with human adaptively to acquire instructive information for realizing dialogue annotation-free navigation and enhancing the transferability in real-world unseen environment. Specifically, we introduce a whether-to-ask (WeTA) policy, together with uncertainty of which action to choose, to indicate whether the agent should ask a question. Then, a what-to-ask (WaTA) policy is proposed, in which, along with the oracle's answers, the agent learns to score question candidates so as to pick up the most informative one for navigation, and meanwhile mimic oracle's answering. Thus, the agent can navigate in a self-Q&A manner even in real-world environment where the human assistance is often unavailable. Through joint optimization of communication and navigation in a unified imitation learning and reinforcement learning framework, SCoA asks a question if necessary and obtains a hint for guiding the agent to move towards the target with less communication cost. Experiments on seen and unseen environments demonstrate that SCoA shows not only superior performance over existing baselines without dialog annotations, but also competing results compared with rich dialog annotations based counterparts.
Framework
Experiment
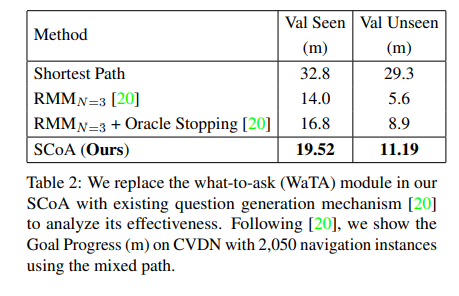
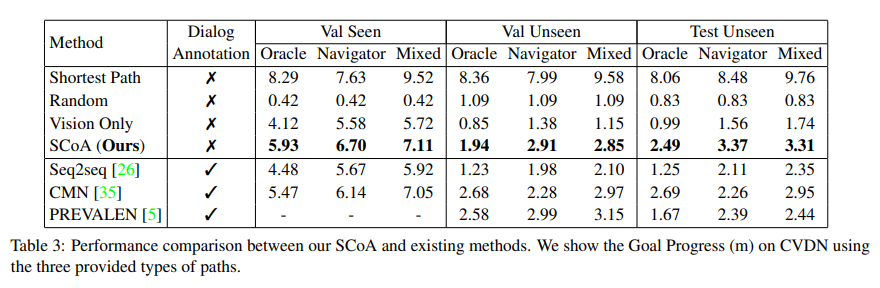

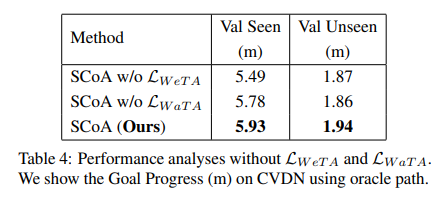
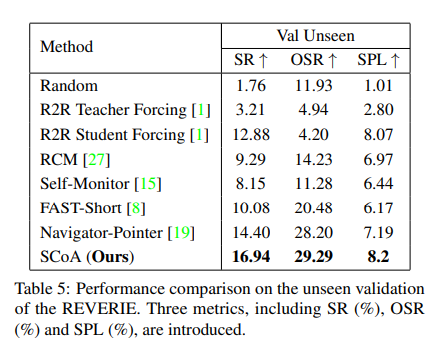
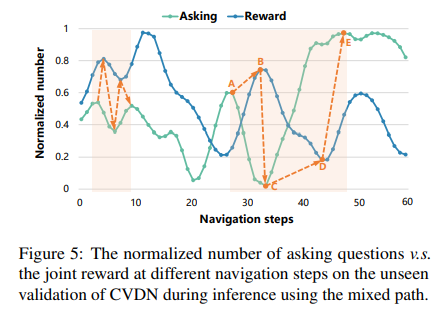
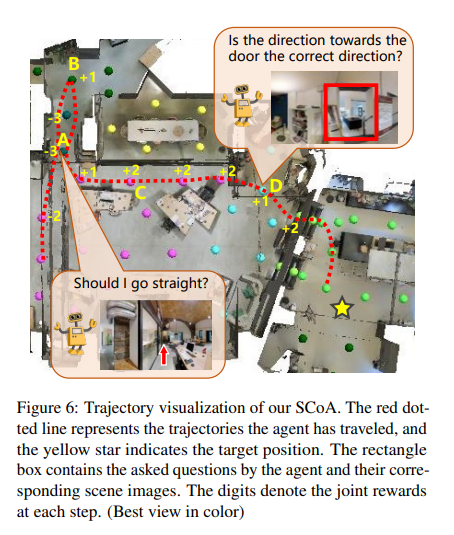
Conclusion
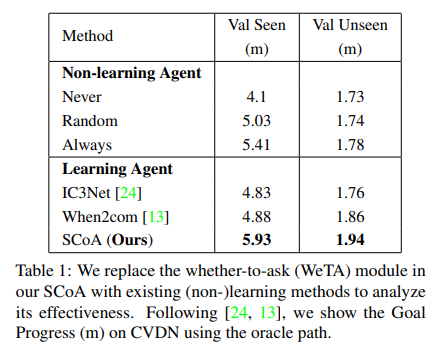
In this paper, we propose the Self-Motivated Communication Agent (SCoA) to tackle the challenging problem of inflexible and annotation-dependent communication for real-world vision-dialog navigation by learning to adaptively decide whether and what to communicate with human to acquire instructive information for guiding the navigation. By jointly learning to communicate and navigate, SCoA explores to balance the communication benefit and cost. SCoA significantly outperforms existing baseline methods without dialog annotations, and even achieves comparable performance to the counterparts that use rich dialog annotations as inputs. Our SCoA gets rid of the limitation of expensive language annotations and shows great potential for navigating in real and open-ended environments.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab