
Abstract
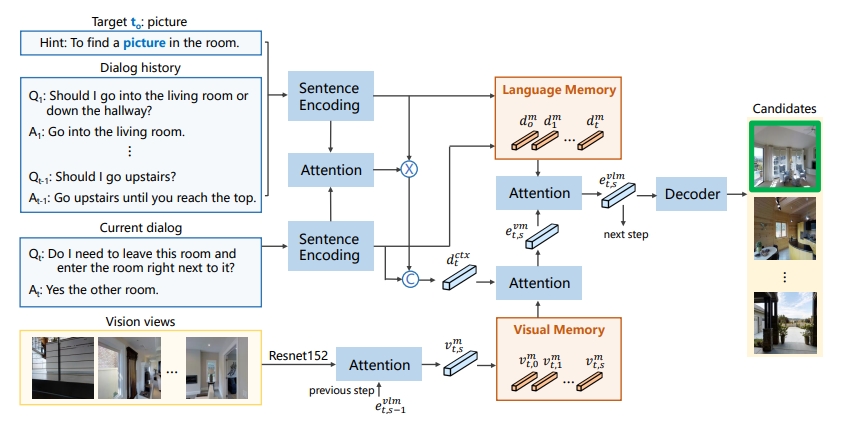
Vision-dialog navigation posed as a new holy-grail task in vision-language disciplinary targets at learning an agent endowed with the capability of constant conversation for help with natural language and navigating according to human responses. Besides the common challenges faced in visual language navigation, vision-dialog navigation also requires to handle well with the language intentions of a series of questions about the temporal context from dialogue history and co-reasoning both dialogs and visual scenes. In this paper, we propose the Cross-modal Memory Network (CMN) for remembering and understanding the rich information relevant to historical navigation actions. Our CMN consists of two memory modules, the language memory module (L-mem) and the visual memory module (V-mem). Specifically, L-mem learns latent relationships between the current language interaction and a dialog history by employing a multi-head attention mechanism. V-mem learns to associate the current visual views and the cross-modal memory about the previous navigation actions. The cross-modal memory is generated via a vision-to-language attention and a language-to-vision attention. Benefiting from the collaborative learning of the L-mem and the V-mem, our CMN is able to explore the memory about the decision making of historical navigation actions which is for the current step. Experiments on the CVDN dataset show that our CMN outperforms the previous state-of-the-art model by a significant margin on both seen and unseen environments.
Framework
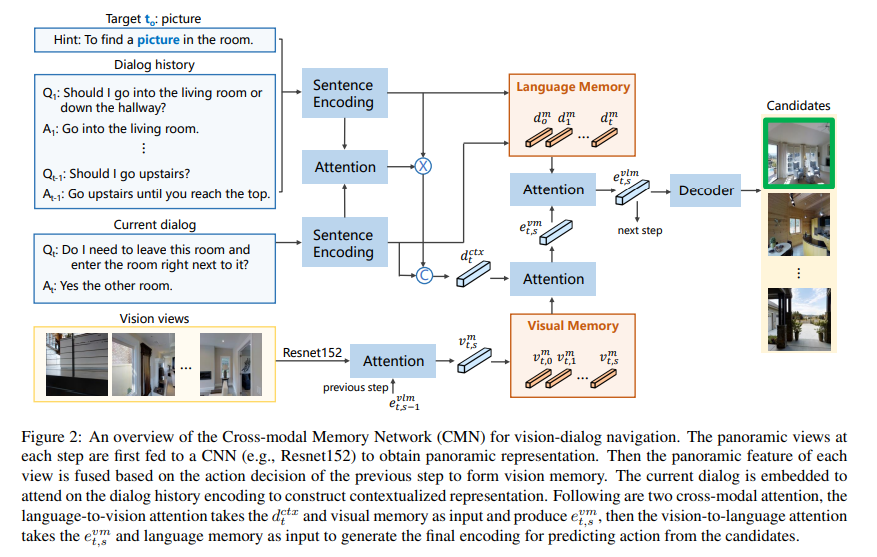
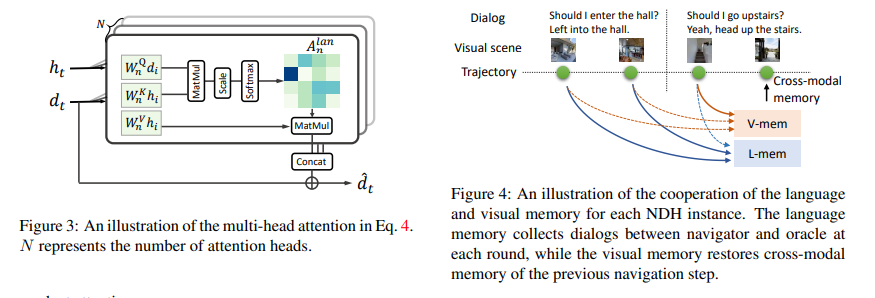
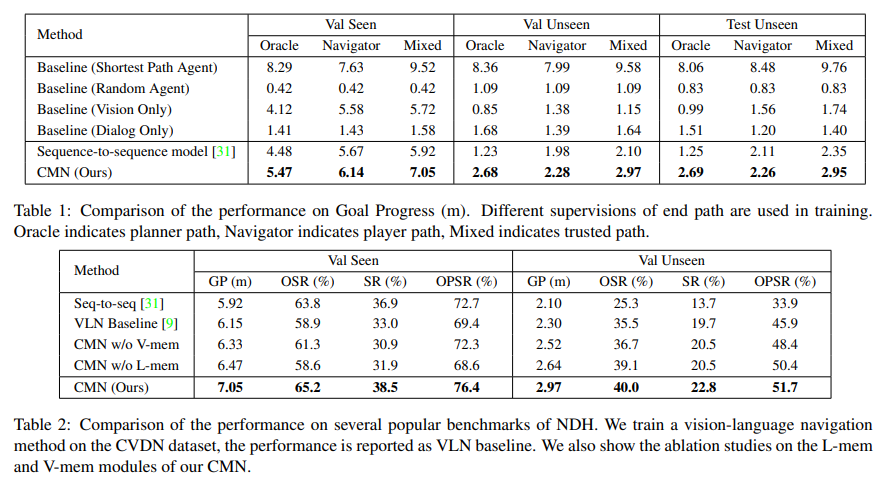
Experiment

Conclusion
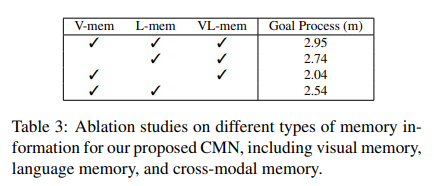
In this work, we propose the Cross-modal Memory Network (CMN) to tackle the challenging task of visual dialogue navigation by exploring cross-modal memory of the agent. The language memory can help the agent better understand the responses from the oracle based on the communication context. The visual memory aims to explore visually grounded information on the previous navigation path, providing temporal correlations for the views. Benefiting from the collaboration of both visual and language memory, CMN is proved to achieve constant improvement over popular benchmarks on visual dialogue navigation, especially when generalizing to the unseen environments.
Acknowledgement
This work was supported in part by National Key R&D Program of China under Grant No.2018AAA0100300, National Natural Science Foundation of China under Grant No.U19A2073, No.61976233, No.61836012, and No.61771447 and Nature Science Foundation of Shenzhen Under Grant No.2019191361.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab