
Abstract
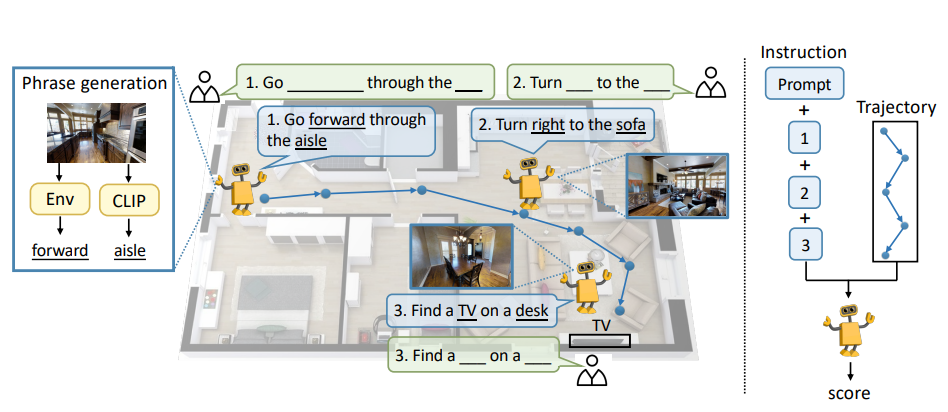
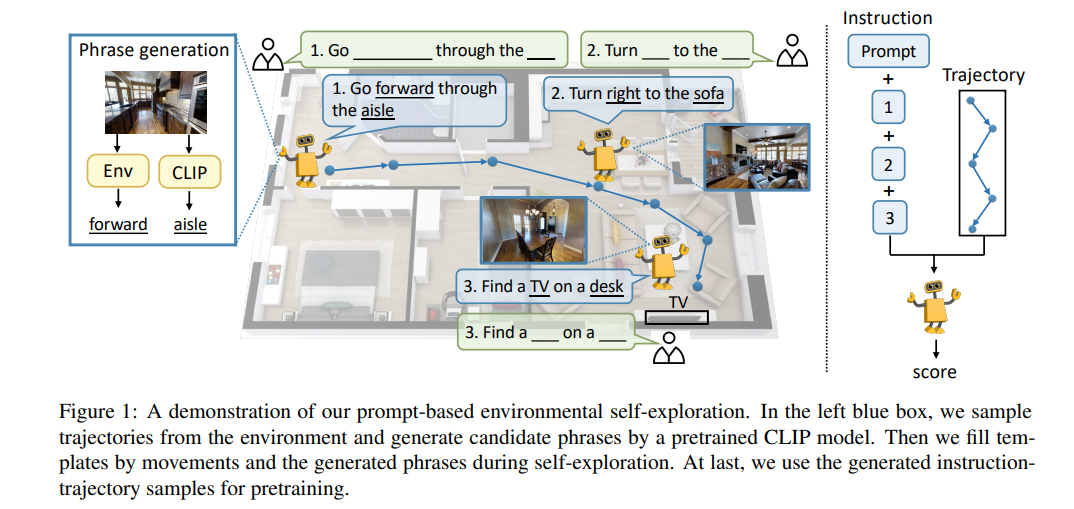
Vision-language navigation (VLN) is a challenging task due to its large searching space in the environment. To address this problem, previous works have proposed some methods of fine-tuning a large model that pretrained on large-scale datasets. However, the conventional fine-tuning methods require extra human-labeled navigation data and lack self-exploration capabilities in environments, which hinders their generalization of unseen scenes. To improve the ability of fast cross-domain adaptation, we propose Prompt-based Environmental Self-exploration (ProbES), which can self-explore the environments by sampling trajectories and automatically generates structured instructions via a large-scale cross-modal pretrained model (CLIP). Our method fully utilizes the knowledge learned from CLIP to build an in-domain dataset by self-exploration without human labeling. Unlike the conventional approach of fine-tuning, we introduce prompt-based learning to achieve fast adaptation for language embeddings, which substantially improves the learning efficiency by leveraging prior knowledge. By automatically synthesizing trajectory-instruction pairs in any environment without human supervision and efficient prompt-based learning, our model can adapt to diverse vision-language navigation tasks, including VLN and REVERIE. Both qualitative and quantitative results show that our ProbES significantly improves the generalization ability of the navigation model.
Framework

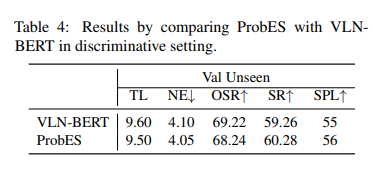
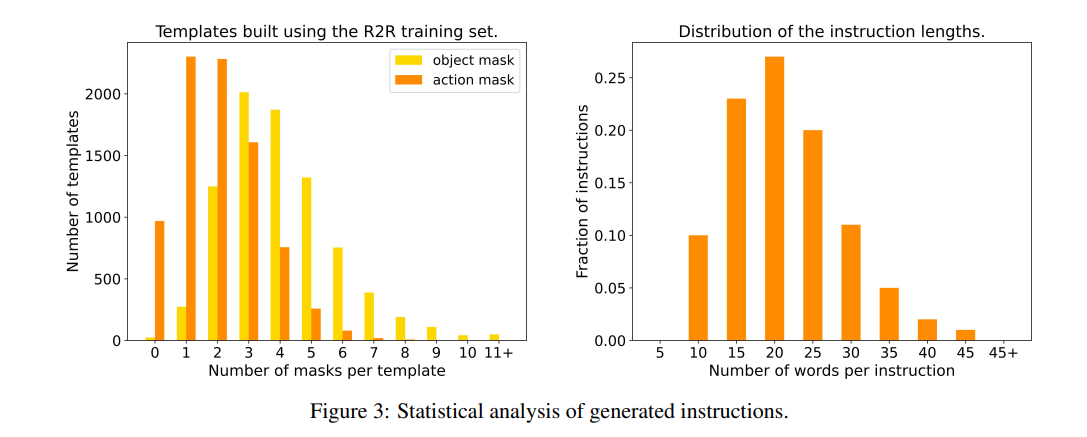
Experiment



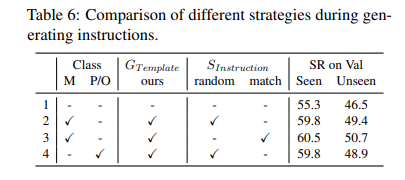
Conclusion
In this work, we first introduce an effective way to generate in-domain data for pretraining the VLN model: leveraging a large pretrained CLIP model to generate captions for each viewpoint and sampling actions in the environment. Experiments show that the domain gap between pretraining data and VLN tasks can be mitigated. We also propose a promptbased architecture, which introduces prompt tuning to adapt the pretrained model fastly. Our proposed ProbES achieves better results compared to baseline on both R2R and REVERIE datasets, and ablations show the contribution of each module and the effectiveness of the generated data.
Acknowledgement
This work was supported in part by National Natural Science Foundation of China (NSFC) No.61976233, Guangdong Province Basic and Applied Basic Research (Regional Joint Fund-Key) Grant No.2019B1515120039, Guangdong Outstanding Youth Fund (Grant No. 2021B1515020061), Shenzhen Fundamental Research Program (Project No. RCYX20200714114642083, No.JCYJ20190807154211365) and CAAI-Huawei MindSpore Open Fund. We thank MindSpore for the partial support of this work, which is a new deep learning computing framwork , and supported by Guangdong Provincial Key Laboratory of Fire Science and Intelligent Emergency Technology, Guangzhou 510006, China.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab