
Abstract
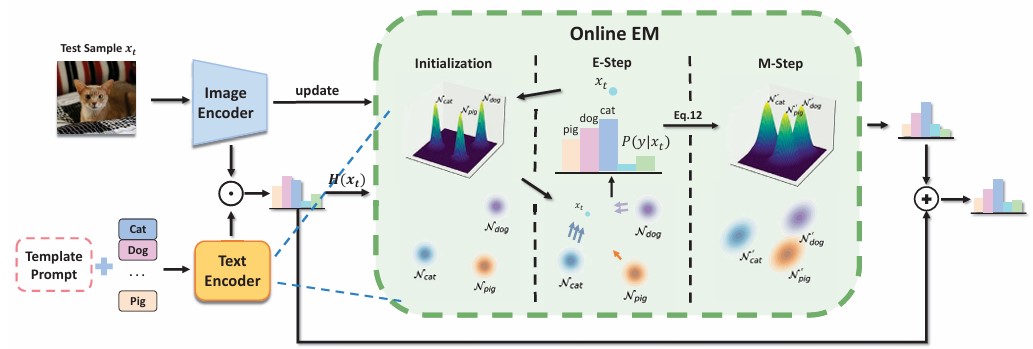
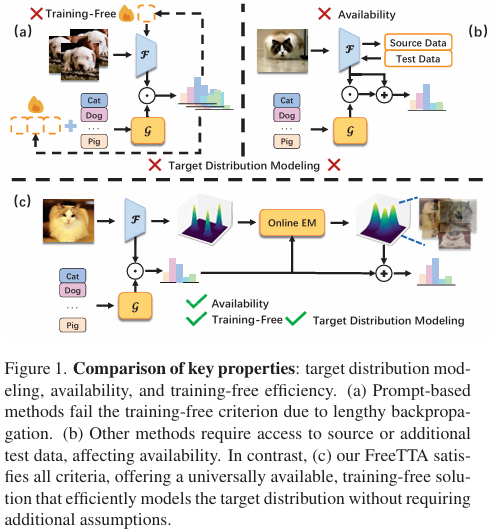
Vision-Language Models (VLMs) have become promi nent in open-world image recognition for their strong gen eralization abilities. Yet, their effectiveness in practical ap plications is compromised by domain shifts and distribu tional changes, especially when test data distributions di verge from training data. Therefore, the paradigm of test time adaptation (TTA) has emerged, enabling the use of on line off-the-shelf data at test time, supporting independent sample predictions, and eliminating reliance on test anno tations. Traditional TTA methods, however, often rely on costly training or optimization processes, or make unrealis tic assumptions about accessing or storing historical training and test data. Instead, this study proposes FreeTTA, a training-free and universally available method that makes no assumptions, to enhance the flexibility of TTA. More im portantly, FreeTTA is the first to explicitly model the test data distribution, enabling the use of intrinsic relationships among test samples to enhance predictions of individual samples without simultaneous access—a direction not pre viously explored. FreeTTA achieves these advantages by introducing an online EM algorithm that utilizes zero-shot predictions from VLMs as priors to iteratively compute the posterior probabilities of each online test sample and up date parameters. Experiments demonstrate that FreeTTA achieves stable and significant improvements compared to state-of-the-art methods across 15 datasets in both cross domain and out-of-distribution settings
Framework

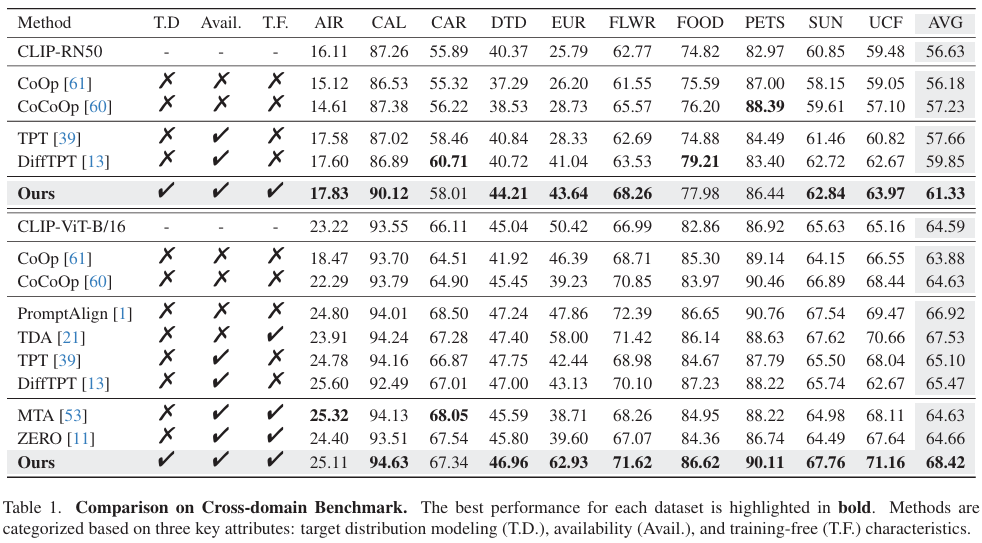
Experiment


Conclusion
proach forVLMs, leveraging theGaussiandiscriminant analysisandanadaptiveonlineEMalgorithmtoimprove adaptabilityunderdomainshifts. ByincorporatingVLM priorsasuncertaintymeasurement,ourmethodeffectively handles varying sequential online samples andenhances model stabilityduring adaptation. Experimental results demonstrate that our approach significantly improves performancewithout relyingonsourcedomaindataand costly training, showcasing its robustness andefficiency.
Acknowledgement
ThisworkwassupportedbytheNa tionalNaturalScienceFoundationofChina(No.62206174)
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab