
Abstract
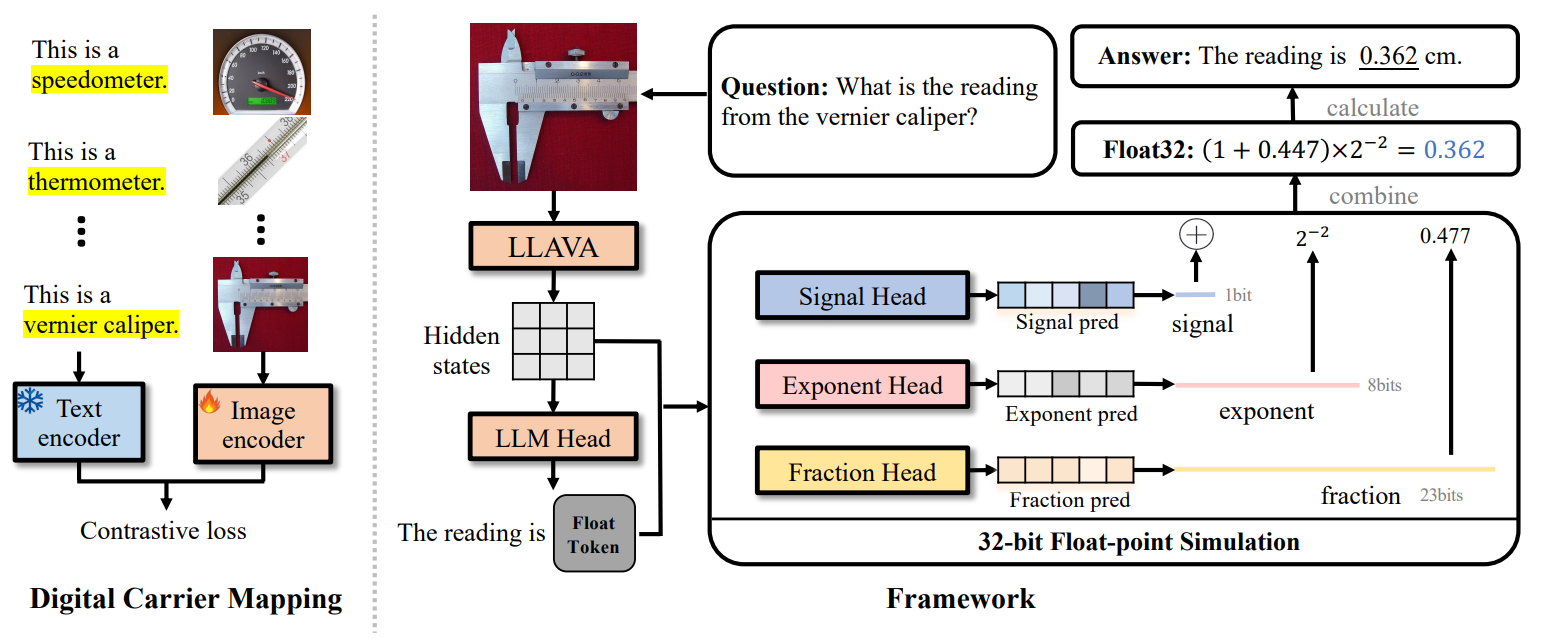
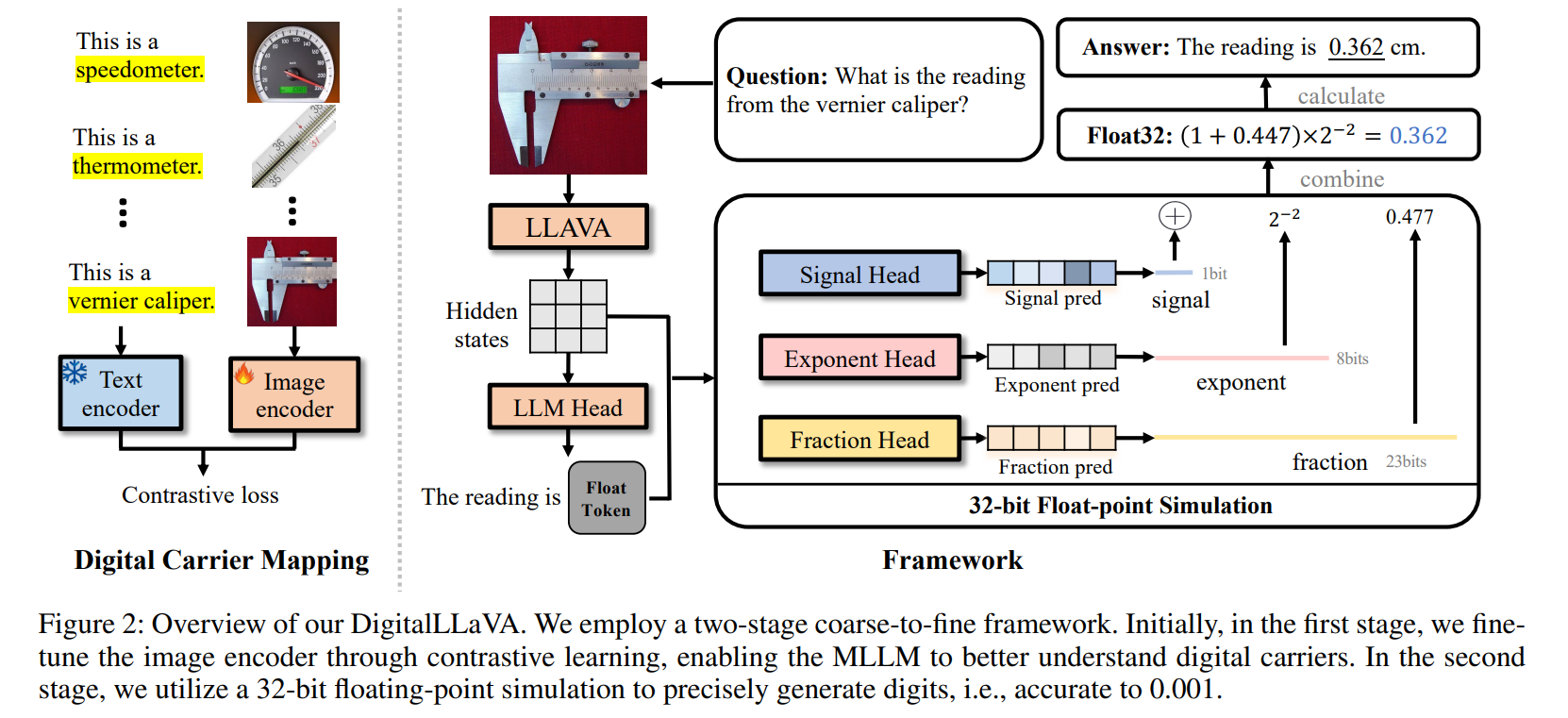
Multimodal Large Language Models (MLLMs) have shown remarkable cognitive capabilities in various cross-modal tasks.However, existing MLLMs struggle with tasks that require physical digital cognition, such as accurately reading an electric meter or pressure gauge. This limitation significantly reduces their effectiveness in practical applications like industrial monitoring and home energy management, where digital sensors are not feasible. For humans, physical digits are artificially defined quantities presented on specific carriers, which require training to recognize. As existing MLLMs are only pre-trained in the manner of object recognition, they fail to comprehend the relationship between digital carriers and their reading. To this end, referring to human behavior, we propose a novel DigitalLLaVA method to explicitly inject digital cognitive abilities into MLLMs in a two-step manner. In the first step, to improve the MLLM's understanding of physical digit carriers, we propose a digit carrier mapping method. This step utilizes object-level text-image pairs to enhance the model's comprehension of objects containing physical digits. For the second step, unlike previous methods that rely on sequential digital prediction or digit regression, we propose a 32 bit floating point simulation approach that treats digit prediction as a whole. Using digit-level text-image pairs, we train three float heads to predict 32-bit floating-point numbers using 0/1 binary classification. This step significantly reduces the search space, making the prediction process more robust and straightforward. Being simple but effective, our method can identify very precise metrics (i.e., accurate to ±0.001) and provide floating-point results, showing its applicability in digital carrier domains.
Framework

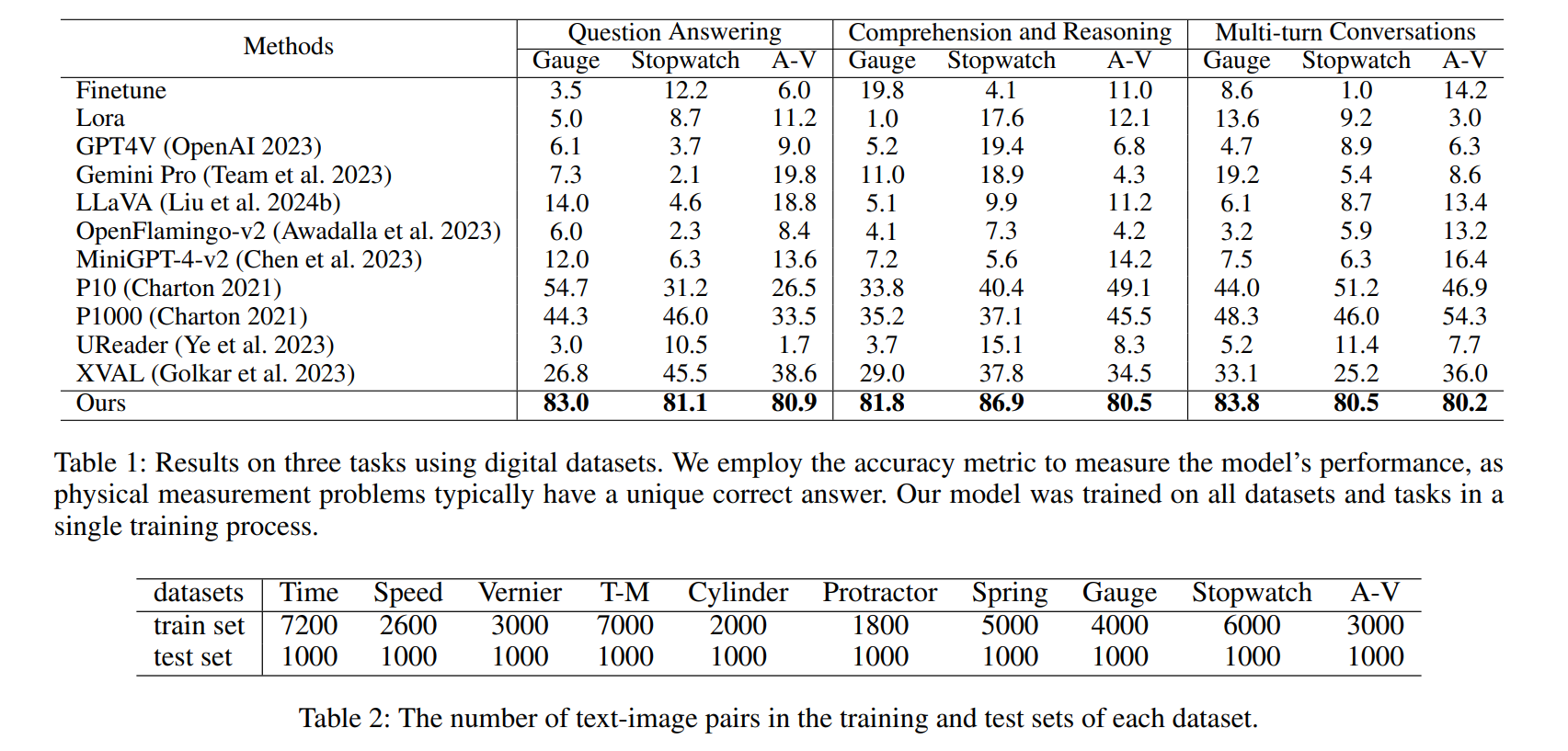
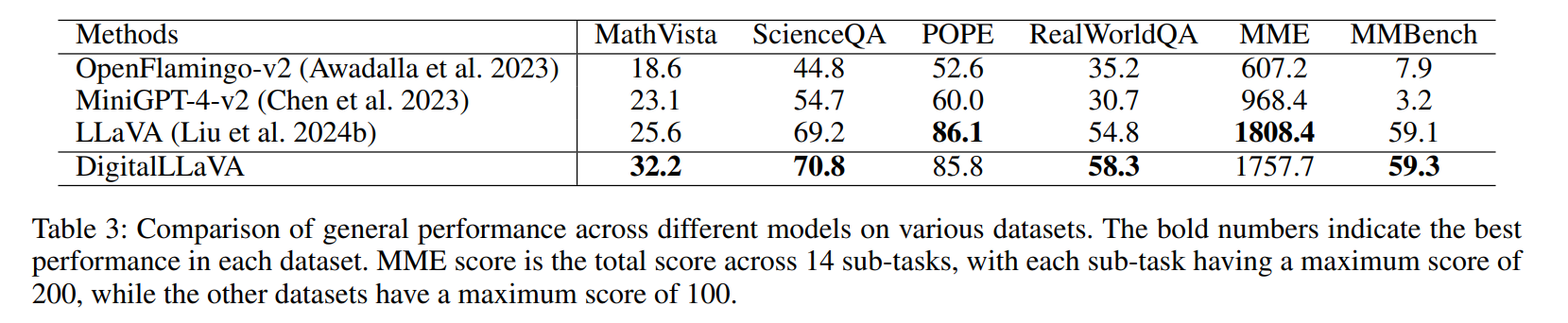
Experiment

Conclusion
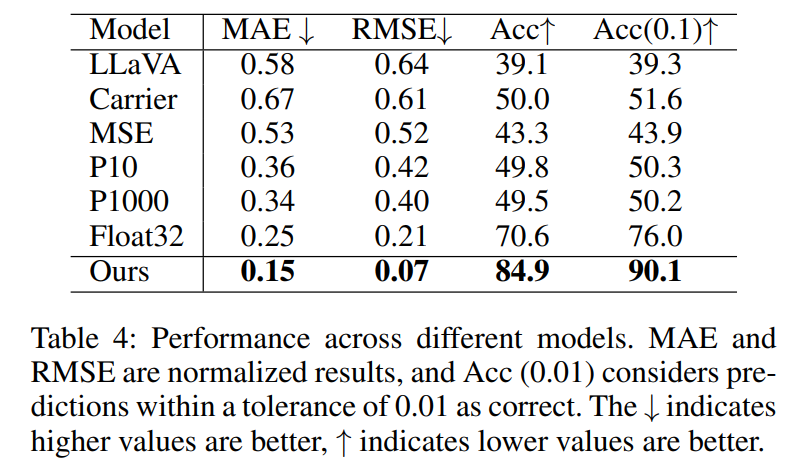
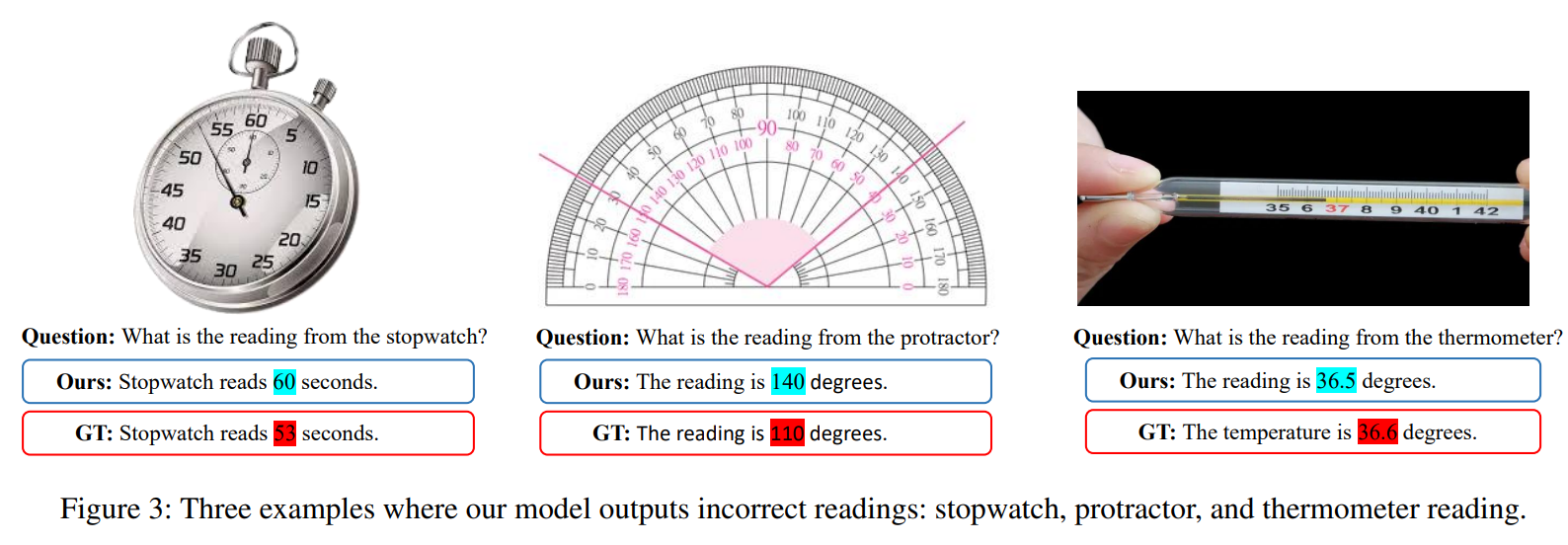
In this paper, we enhance Multimodal Large Language Models (MLLMs) with the capability for physical digital cognition. Specifcally, since humans must identify the carriers before reading digits, and noting that previous MLLMs did not have a rich representation of the corresponding carriers, our DigitalLLaVA introduce a digit carrier mapping to improve the model’s understanding of these carriers. Furthermore, to enhance the model’s precision in reading digits from the carriers, we propose a 32-bit foating-point simulation to represent digits. Our DigitalLLaVA demonstrates robust performance across multiple datasets, effectively addressing the challenge of interpreting physical objects. Codes are accessible in supplementary material. Broader Impact. MLLMs have gained signifcant popularity in recent years, often seen as a key pathway towards achieving AGI (Artifcial General Intelligence). This paper identifes a critical gap in MLLMs’ capabilities for physical digital cognition, a crucial aspect due to the physical world’s integral role in human experience. By addressing this gap, we aim to contribute to the advancement of MLLMs within specialized domains and hope to inspire further development in these areas.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab