
Abstract
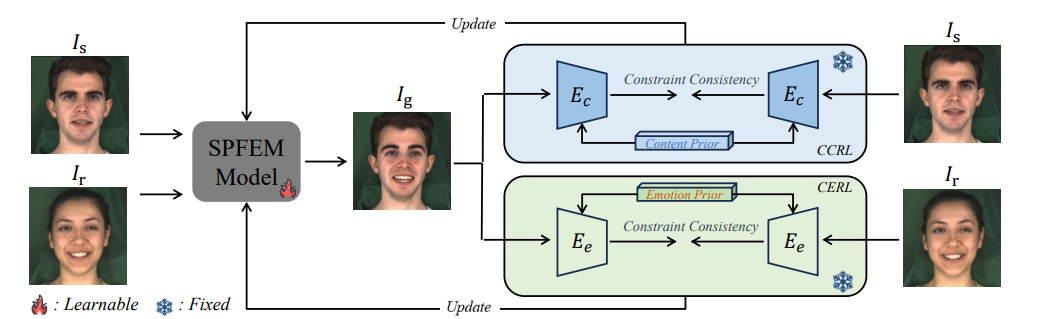
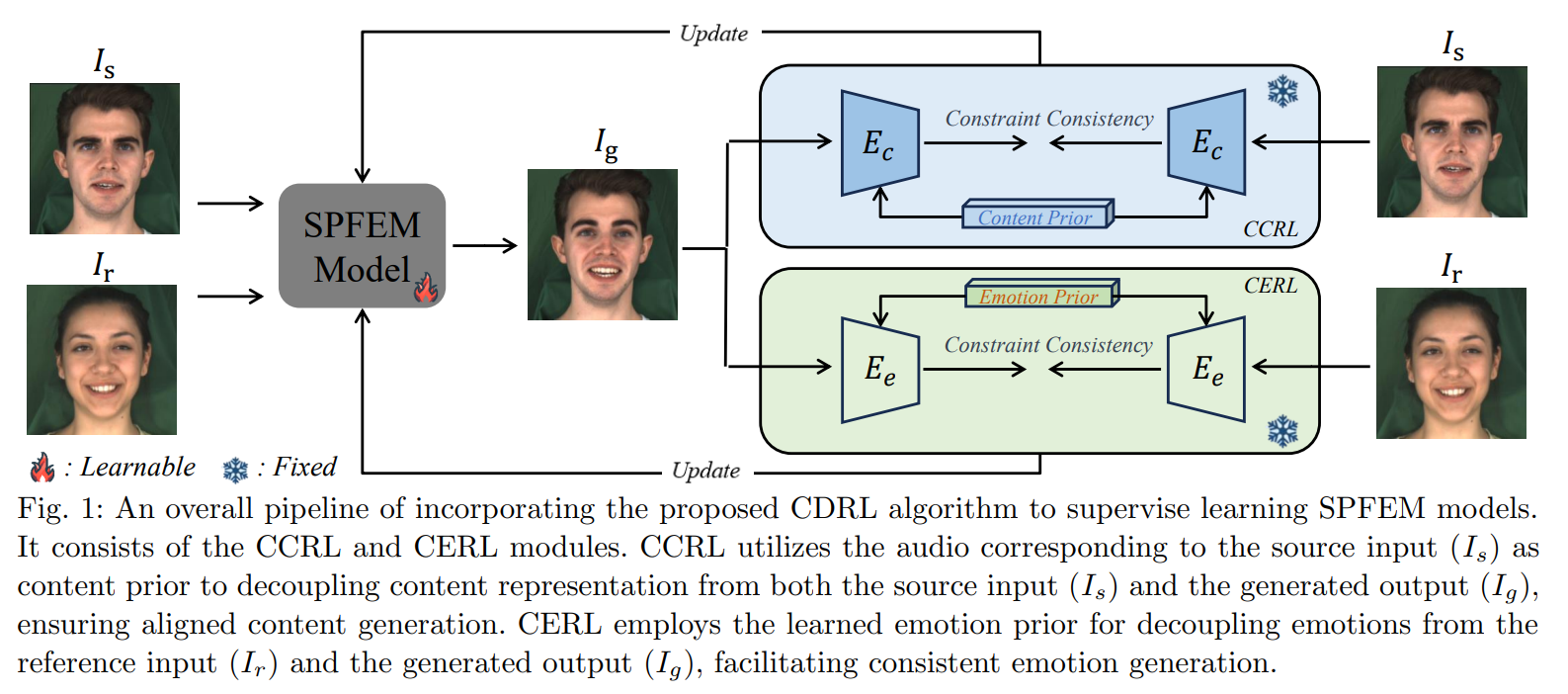
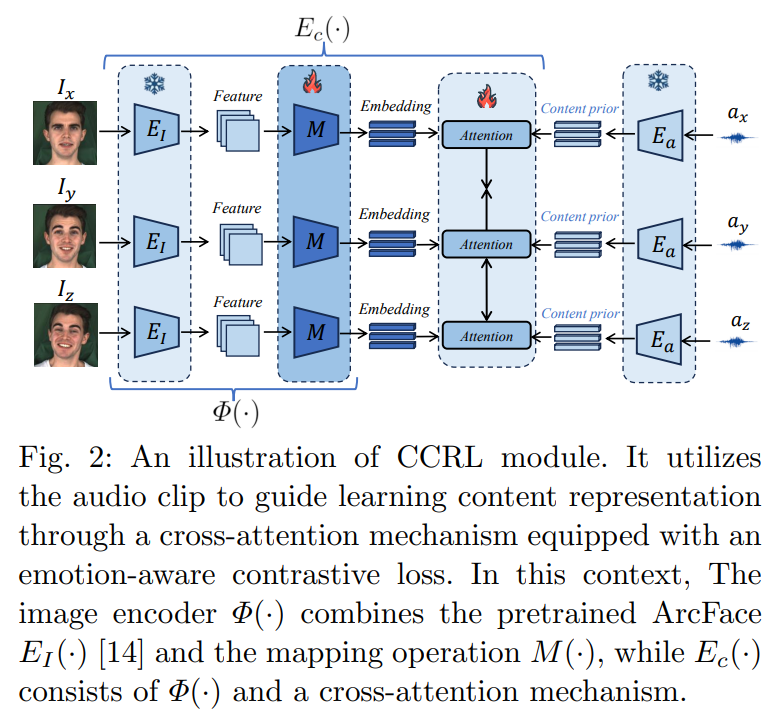
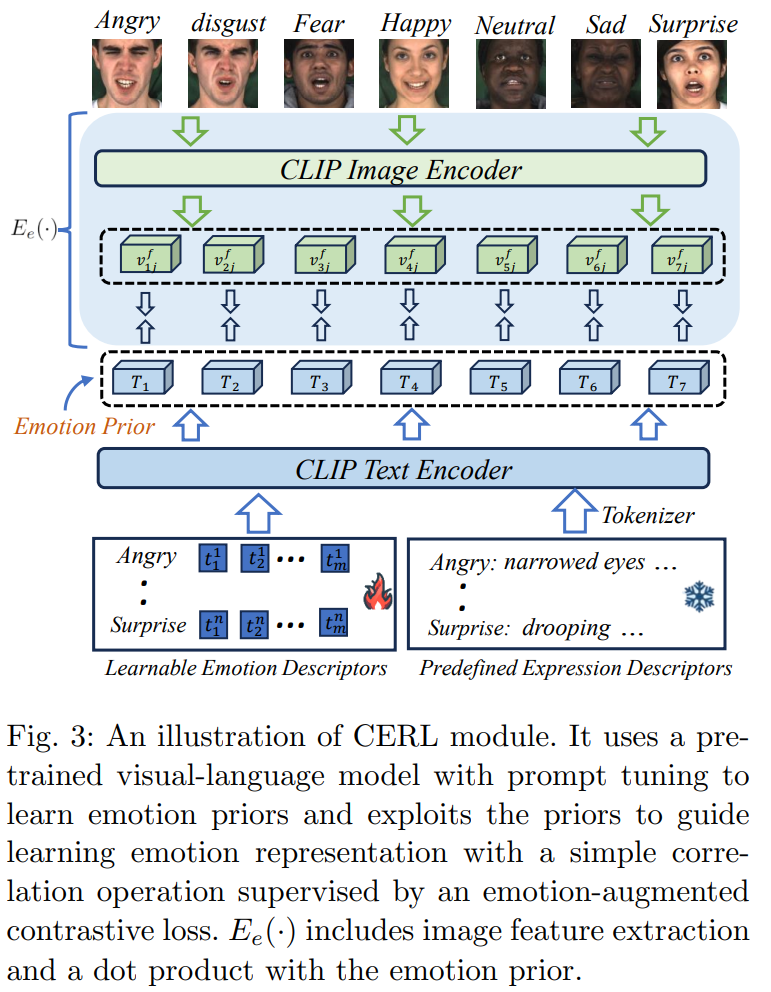
Speech-preserving facial expression manipulation (SPFEM) aims to modify a talking head to display a specific reference emotion while preserving the mouth animation of source spoken contents. Thus, emotion and content information existing in reference and source inputs can provide direct and accurate supervision signals for SPFEM models. However, the intrinsic intertwining of these elements during the talking process poses challenges to their effectiveness as supervisory signals. In this work, we propose to learn content and emotion priors as guidance augmented with contrastive learning to learn decoupled content and emotion representation via an innovative Contrastive Decoupled Representation Learning (CDRL) algorithm. Specifically, a Contrastive Content Representation Learning (CCRL) module is designed to learn audio feature, which primarily contains content information, as content priors to guide learning content representation from the source input. Meanwhile, a Contrastive Emotion Representation Learning (CERL) module is proposed to make use of a pre-trained visual-language model to learn emotion prior, which is then used to guide learning emotion representation from the reference input. We further introduce emotion-aware and emotion-augmented contrastive learning to train CCRL and CERL modules, respectively, ensuring learning emotion-independent content representation and content-independent emotion representation. During SPFEM model training, the decoupled content and emotion representations are used to supervise the generation process, ensuring more accurate emotion manipulation together with audio-lip synchronization. Extensive experiments and evaluations on various benchmarks show the effectiveness of the proposed algorithm.
Framework
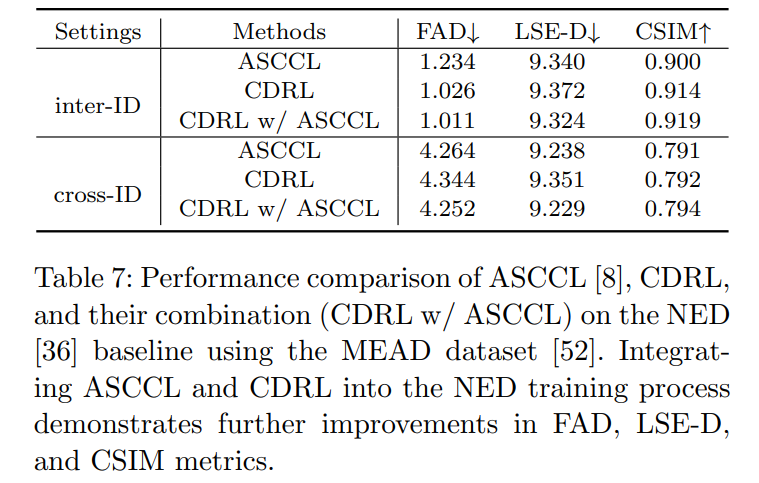
Experiment
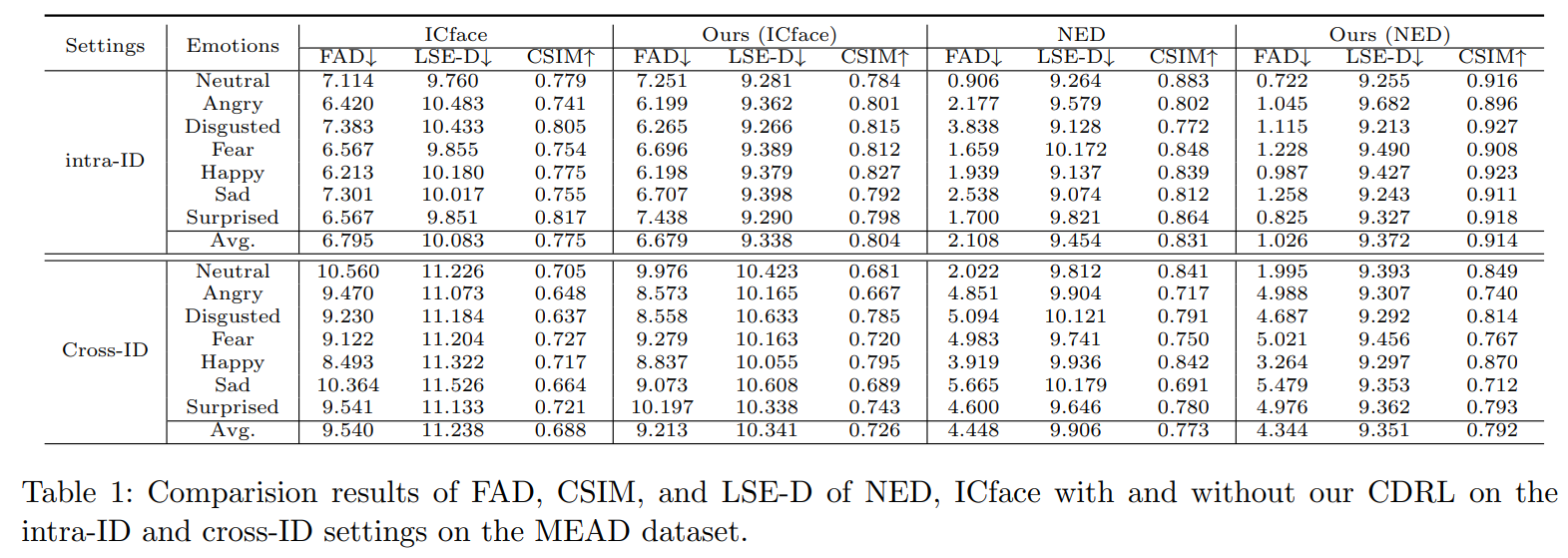
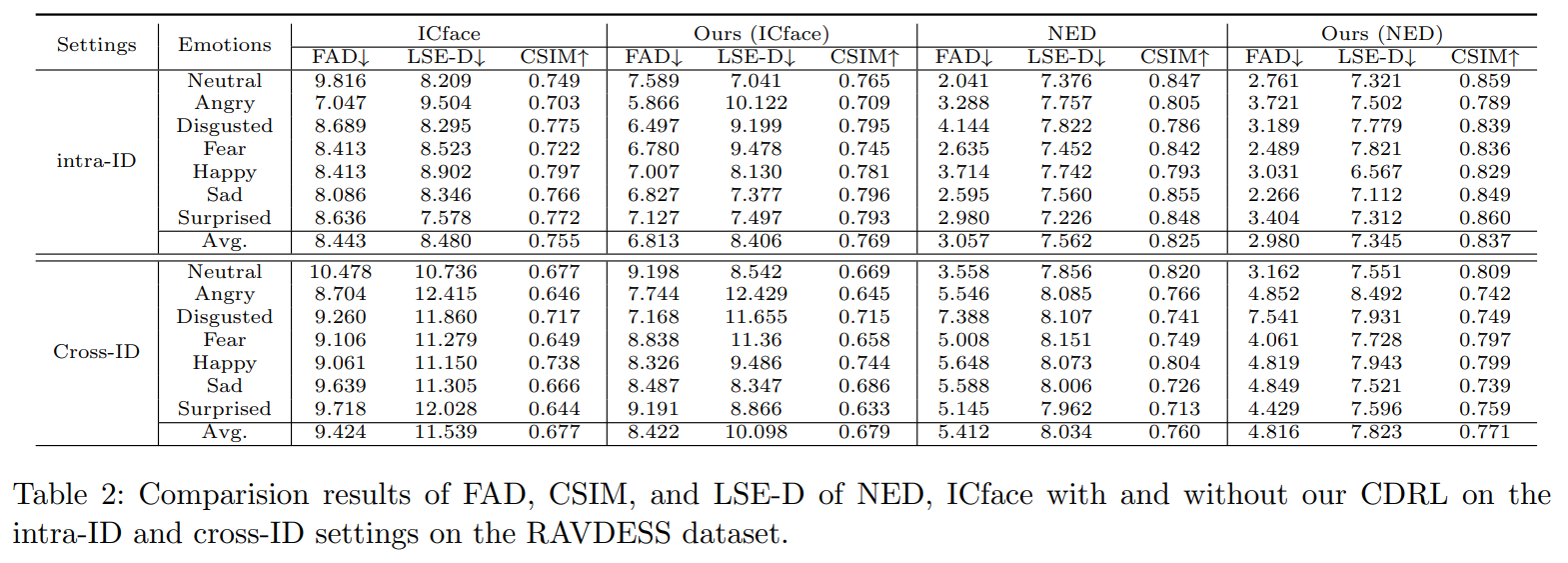

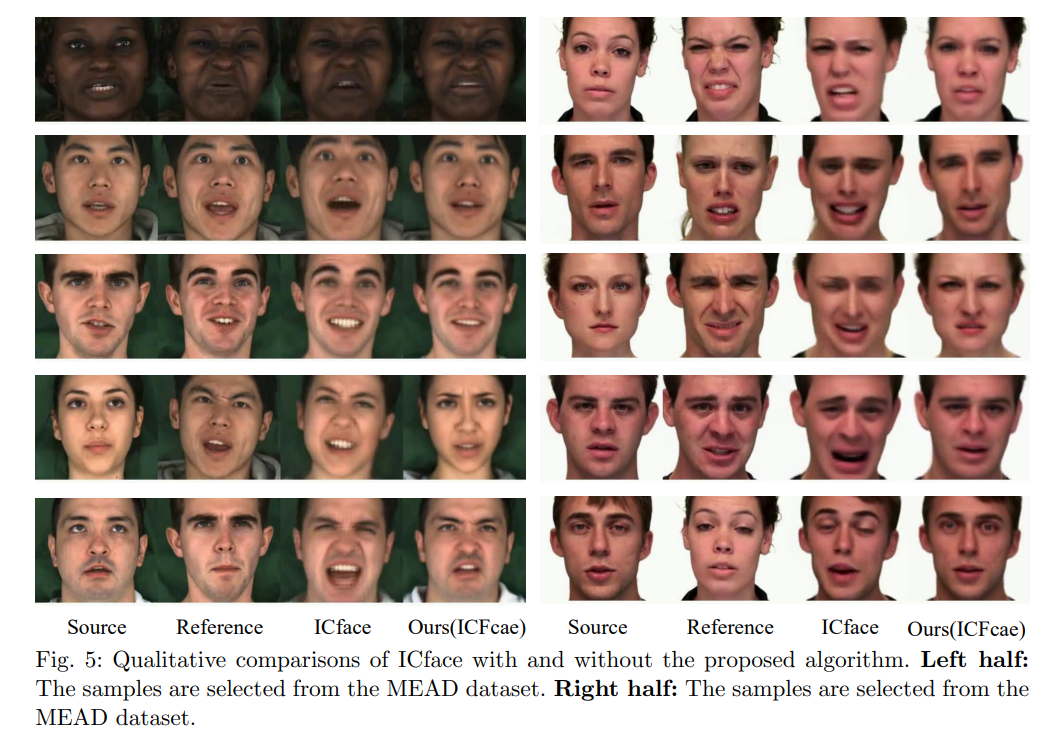
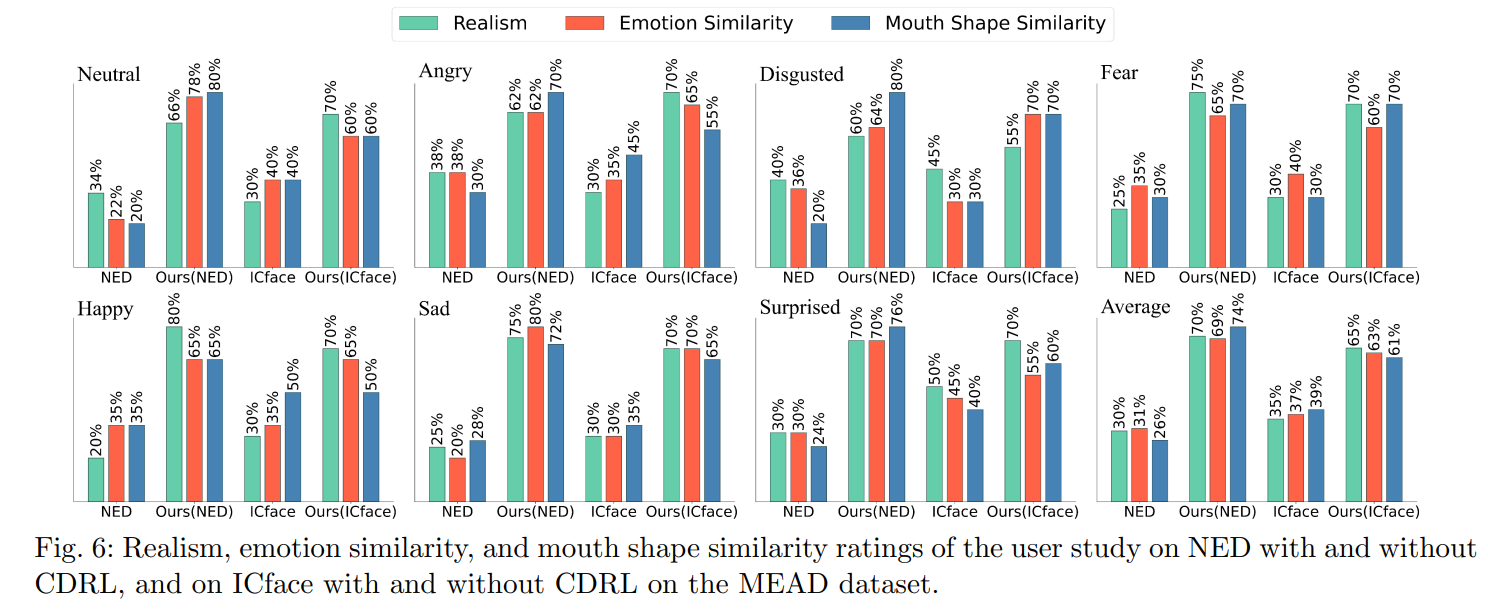
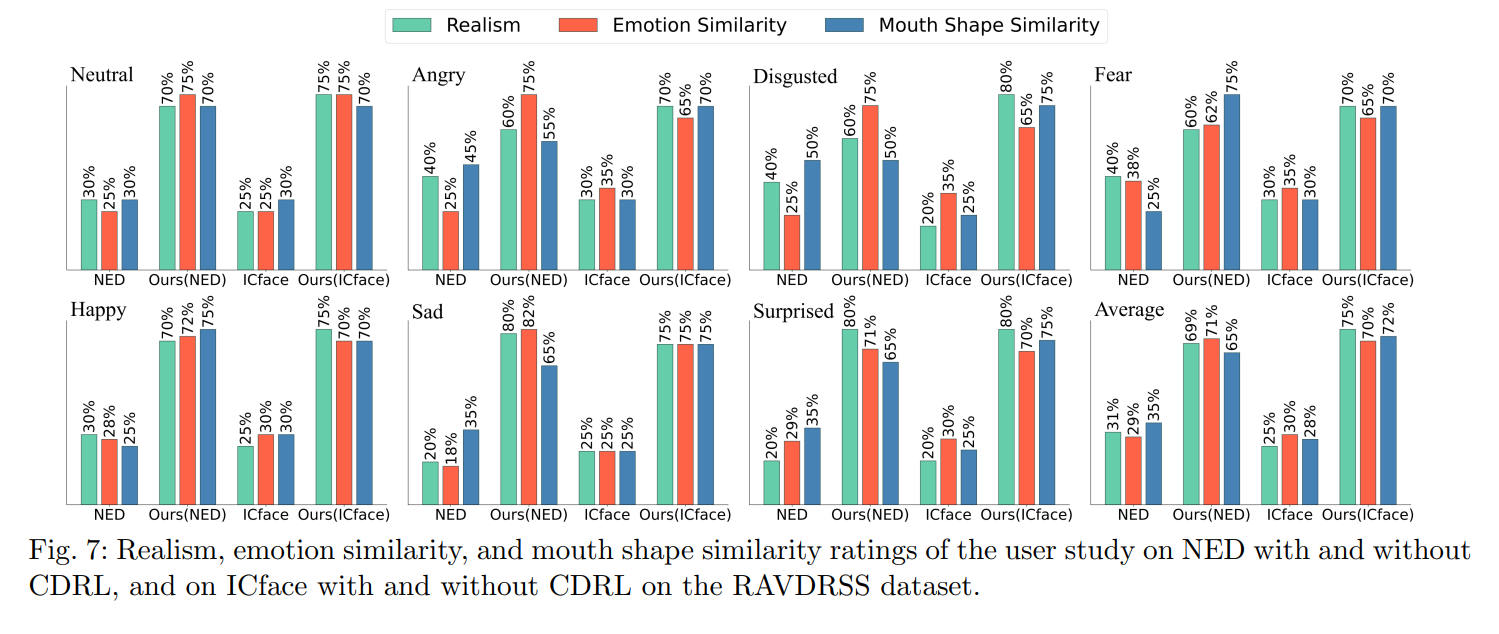
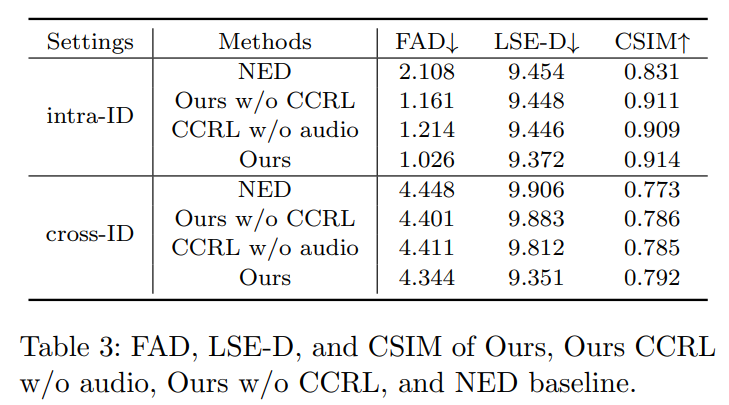
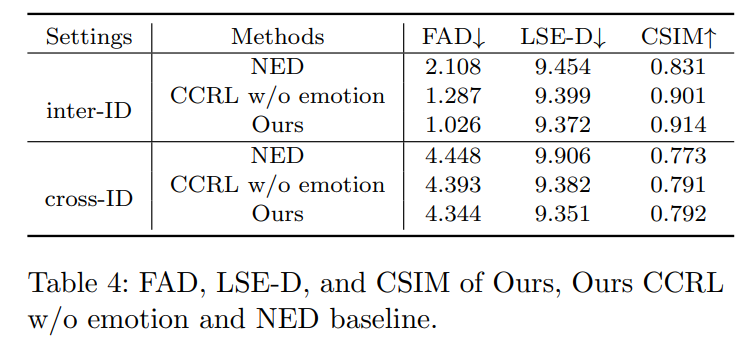

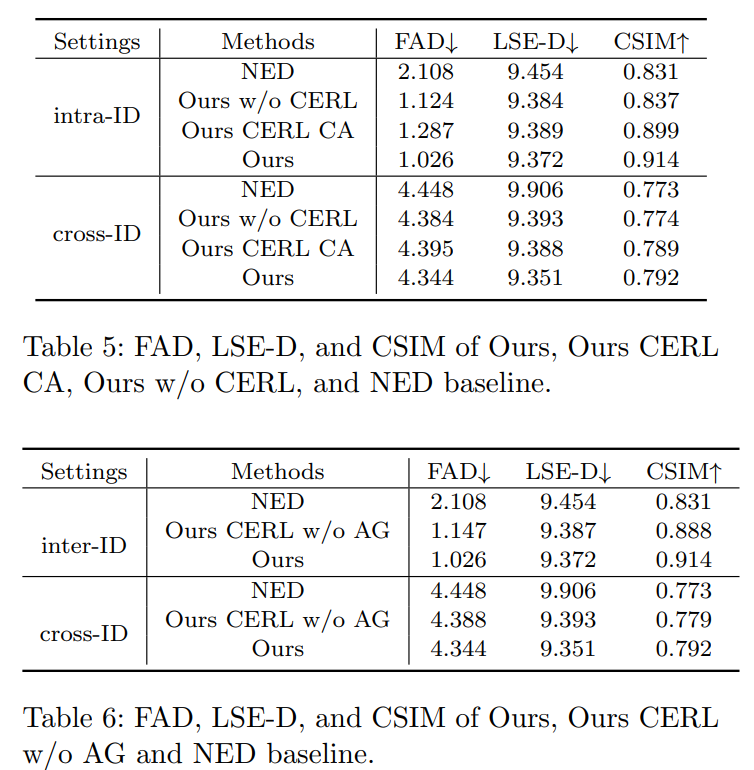
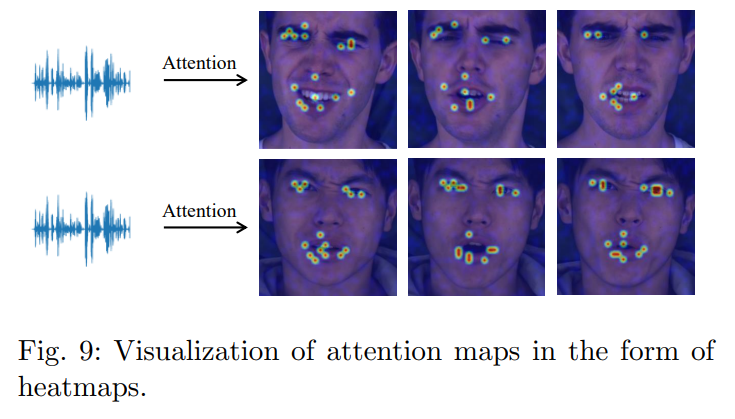

Conclusion
This work presents a Contrastive Decoupled Representation Learning (CDRL) algorithm, which learns decoupled content and emotion representation as more direct and accurate supervision signals to facilitate Speech-preserving Facial Expression Manipulation (SPFEM). It consists of Contrastive Content Representation Learning (CCRL) and Contrastive Emotion Representation Learning (CERL) modules, in which the former exploits audio as content prior to learning emotion-independent content representation while the latter introduces largescale visual-language model to learn emotion prior, which is then used to guide learning content-independent emotion representation. During CCRL and CERL learning, we use contrastive learning as the objective loss to ensure that content and emotion representation merely contain content and emotion information, respectively. During SPFEM model training, the decoupled content and emotion representation are used in the generation process, ensuring more accurate emotional manipulation together with audio-lip synchronization. Extensive experiments and evaluations across various benchmarks have demonstrated the effectiveness of the proposed CDRL algorithm.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab