
Abstract
Large Multimodal Models (LMMs) have demonstrated exceptional comprehension and interpretation capabilities in Autonomous Driving (AD) by incorporating large language models. Despite the advancements, current data-driven AD approaches tend to concentrate on a single dataset and specific tasks, neglecting their overall capabilities and ability to generalize. To bridge these gaps, we propose DriveMM, a general large multimodal model designed to process diverse data inputs, such as images and multi-view videos, while performing a broad spectrum of AD tasks, including perception, prediction, and planning. Initially, the model undergoes curriculum pre-training to process varied visual signals and perform basic visual comprehension and perception tasks. Subsequently, we augment and standardize various AD-related datasets to fine-tune the model, resulting in an all-in-one LMM for autonomous driving. To assess the general capabilities and generalization ability, we conduct evaluations on six public benchmarks and undertake zero-shot transfer on an unseen dataset, where DriveMM achieves state-of-the-art performance across all tasks. We hope DriveMM as a promising solution for future end-to-end autonomous driving applications in the real world. Project page with code: this https URL.
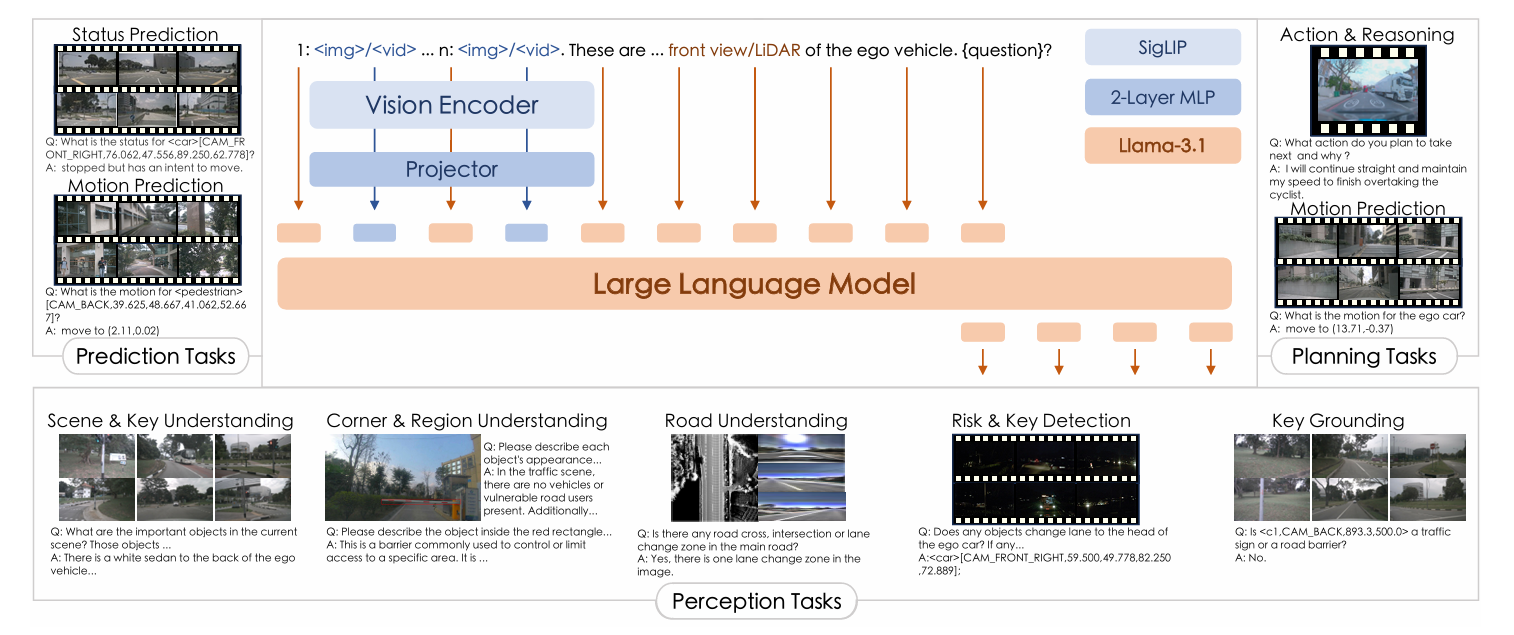
Framework
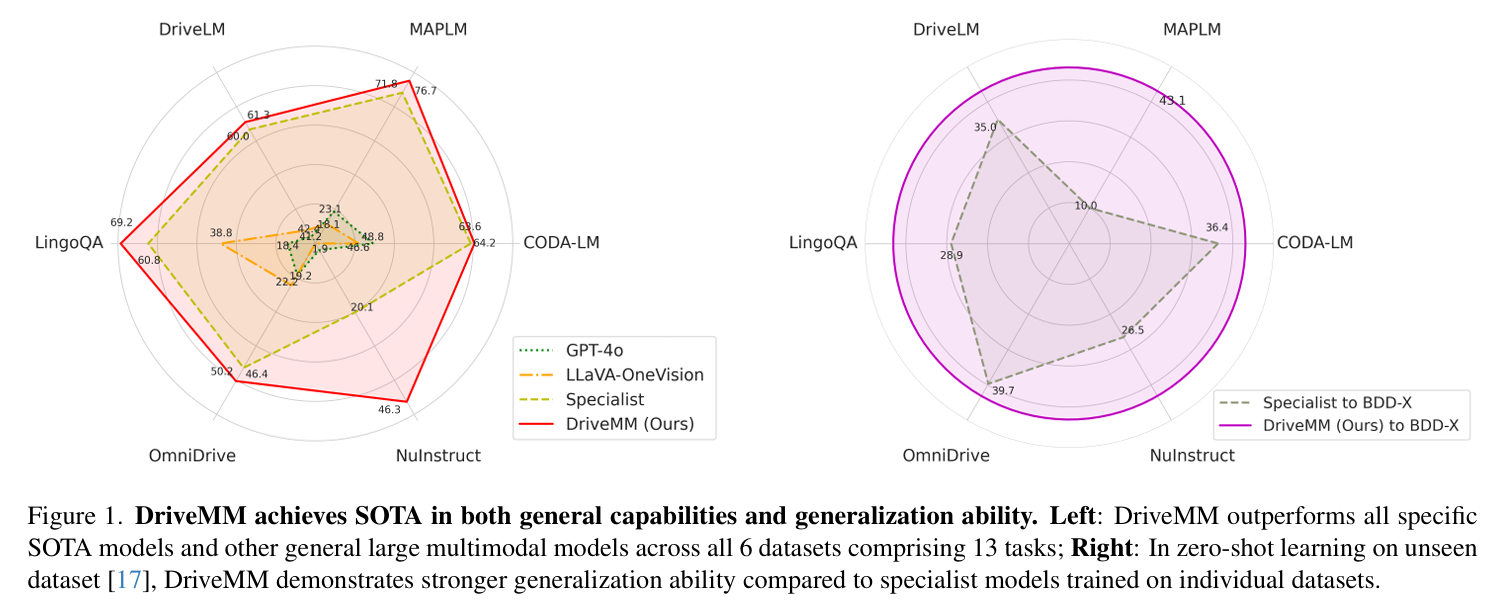
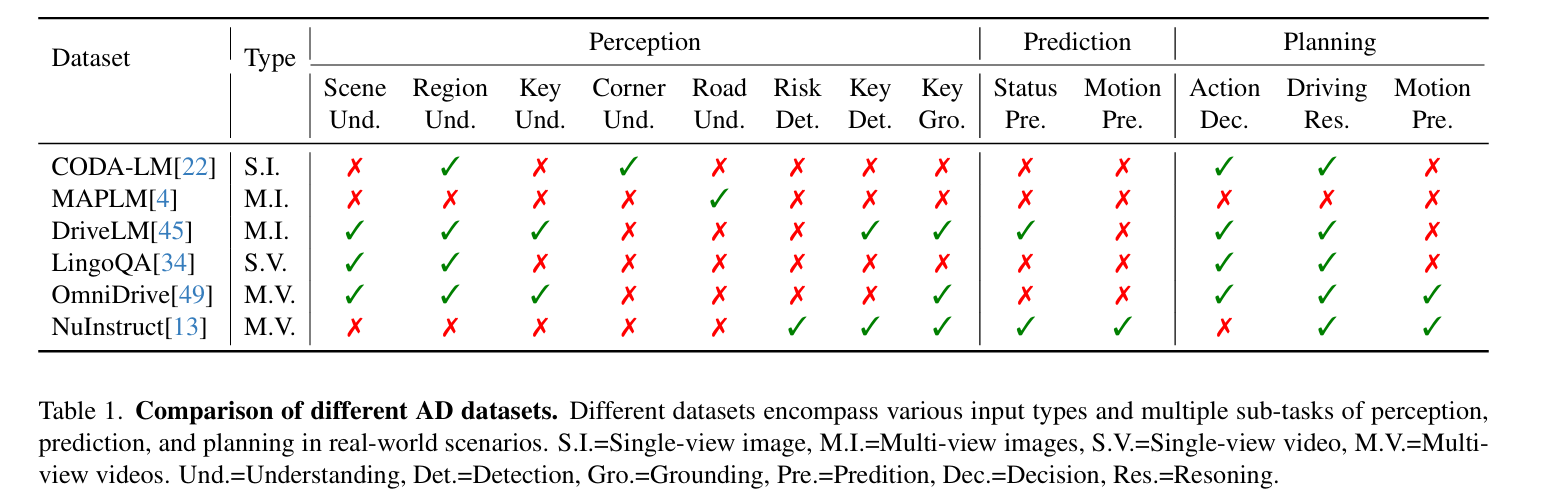
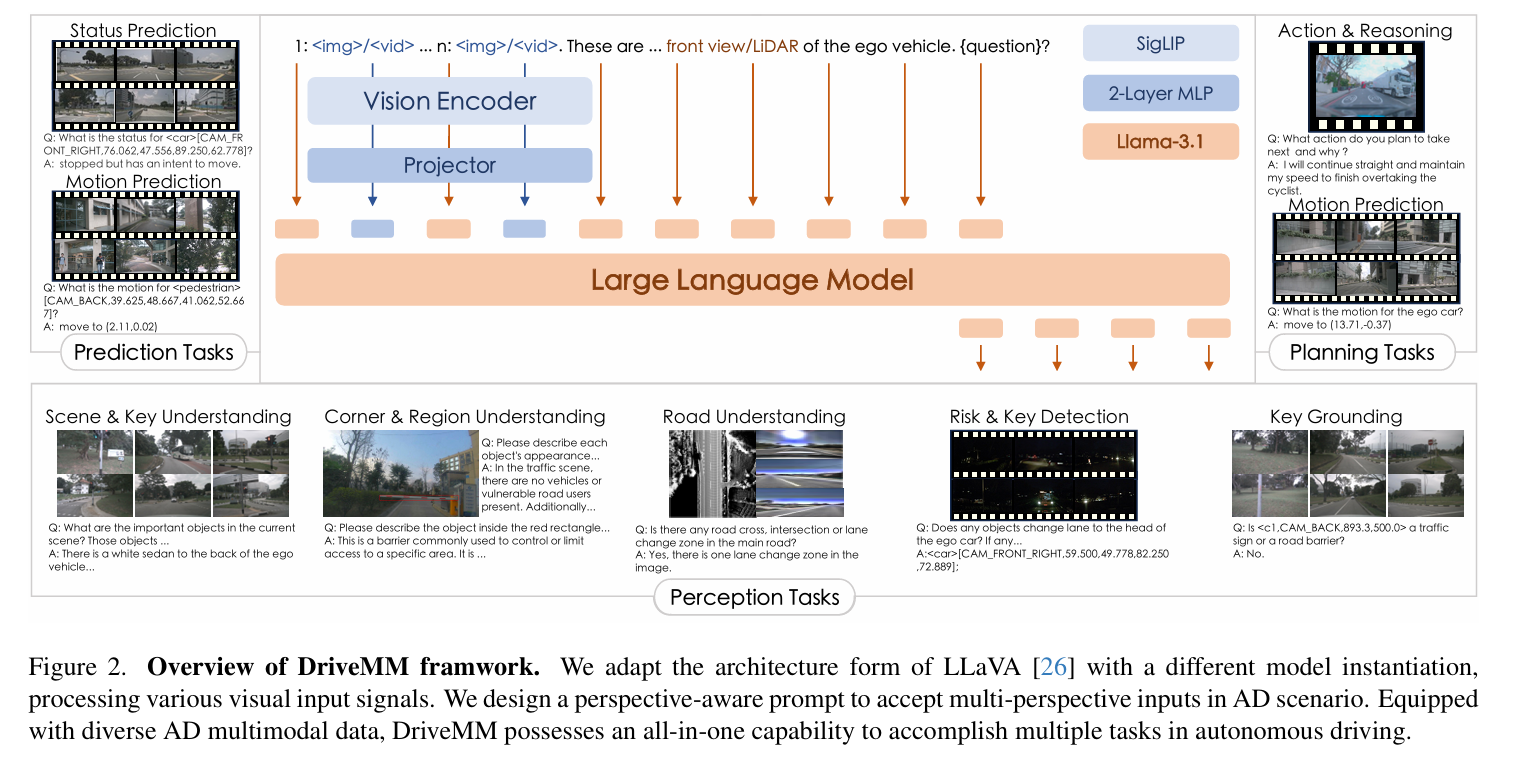

Experiment

Conclusion
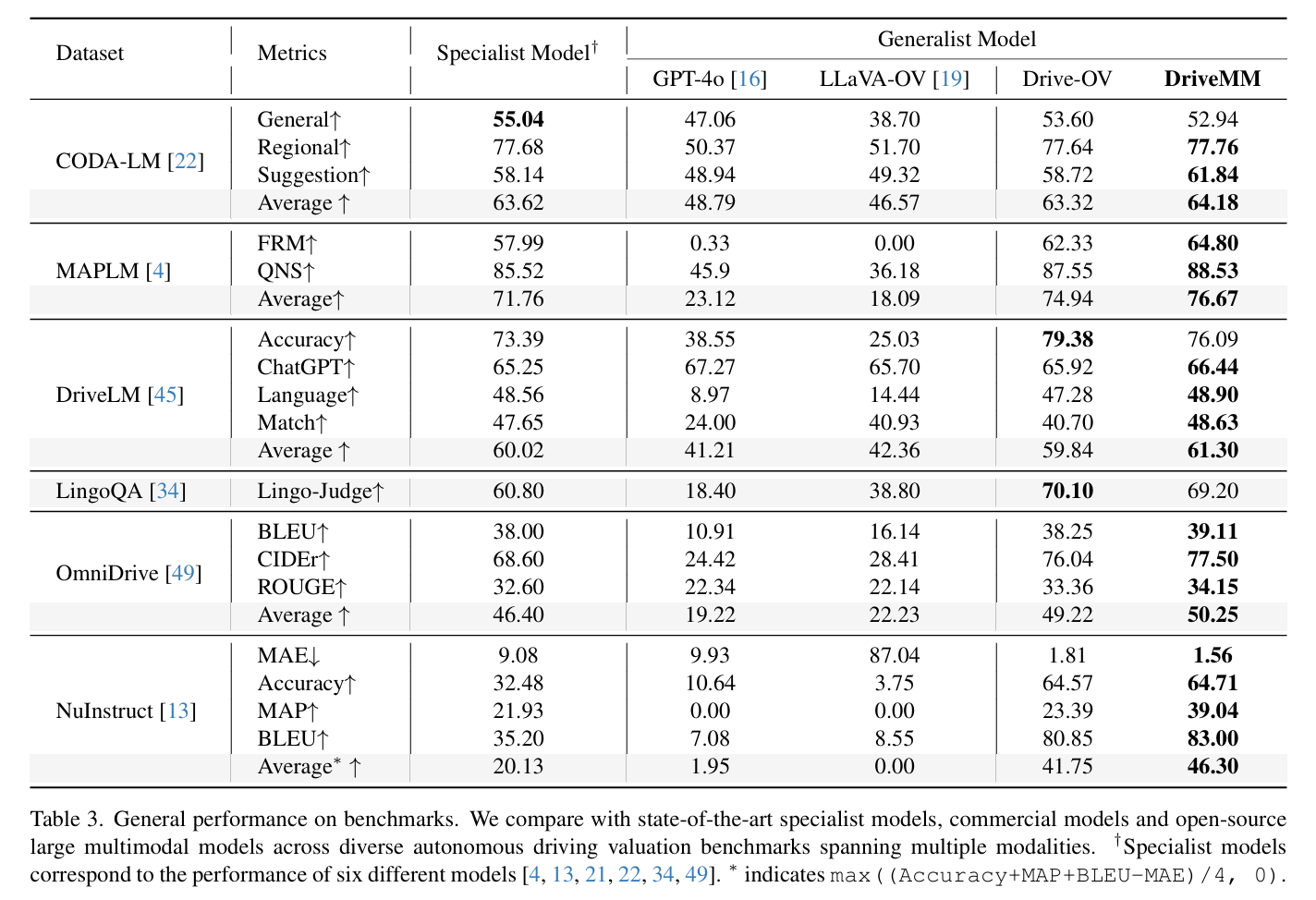
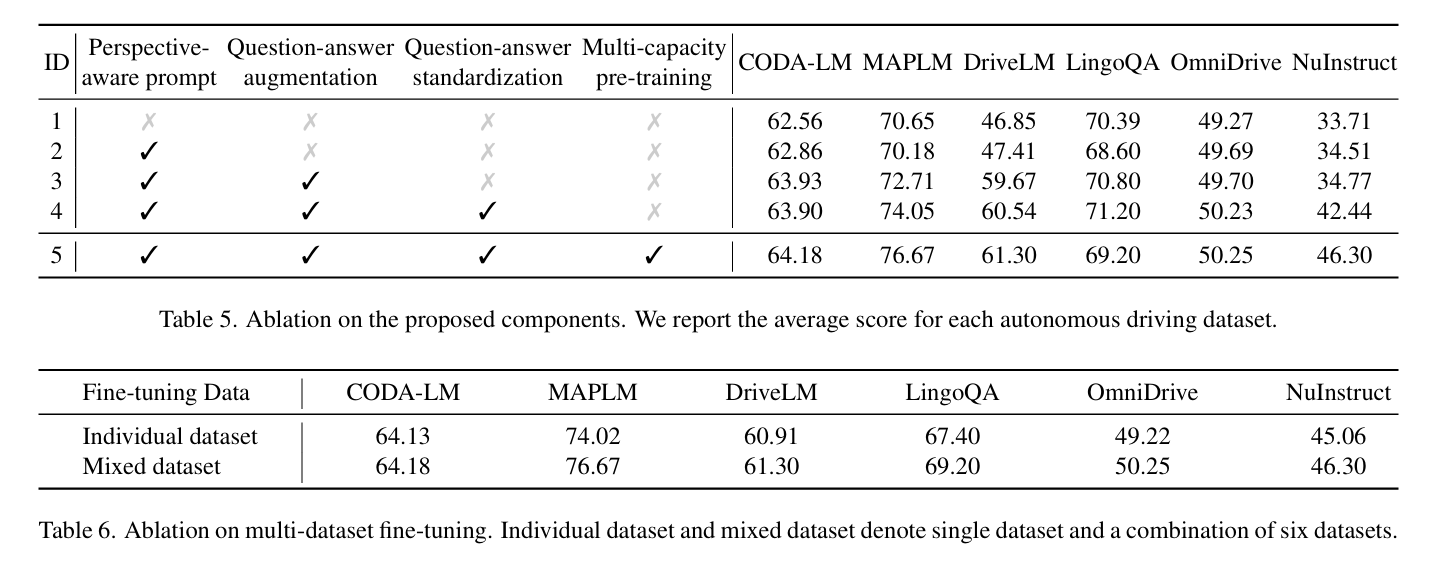
In this paper,we present an all-in-one large multimodal autonomous driving model,DriveMM,which can handle various types of data and perform multiple driving tasks in real-world scenarios, demonstrating excellent generality and robustness. To our knowledge, we are the first to develop a comprehensive model for AD and evaluate the model across multiple datasets in various AD scenarios. By augmenting and standardizing several open-source datasets and designing data-related prompts, we conduct multi-steppre-training and fine-tuning of the model from scratch. DriveMM achieves state-of-the-art performance across various data and tasks in the real-world scenarios.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab