
CVPR 2025
Empowering Large Language Models with 3D Situation Awareness
Abstract
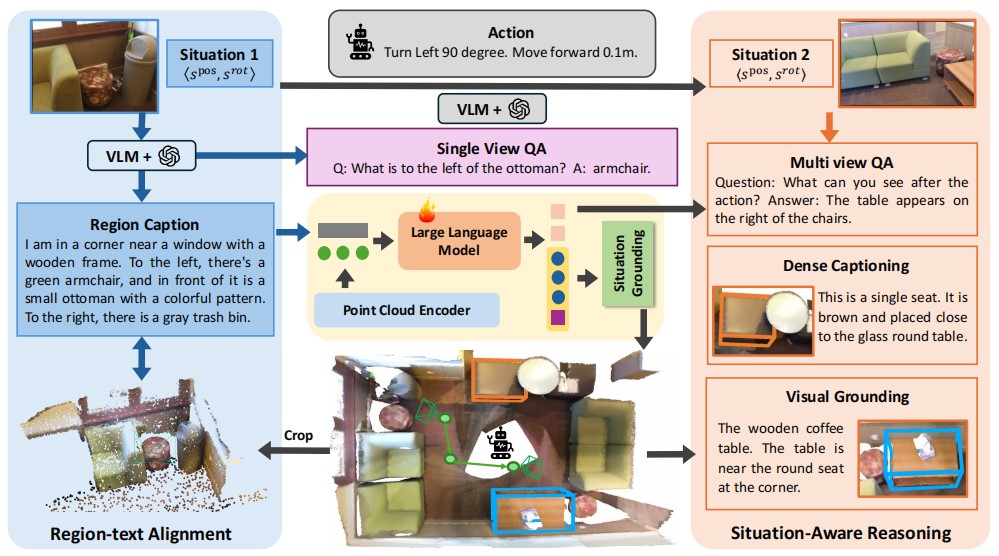
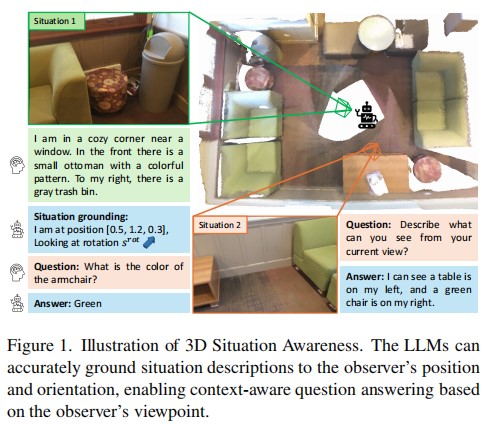
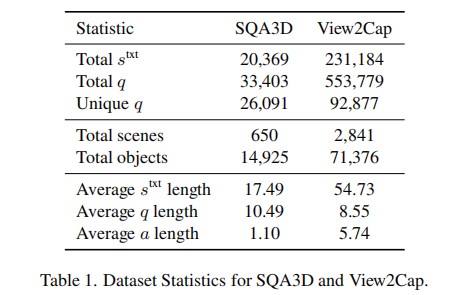
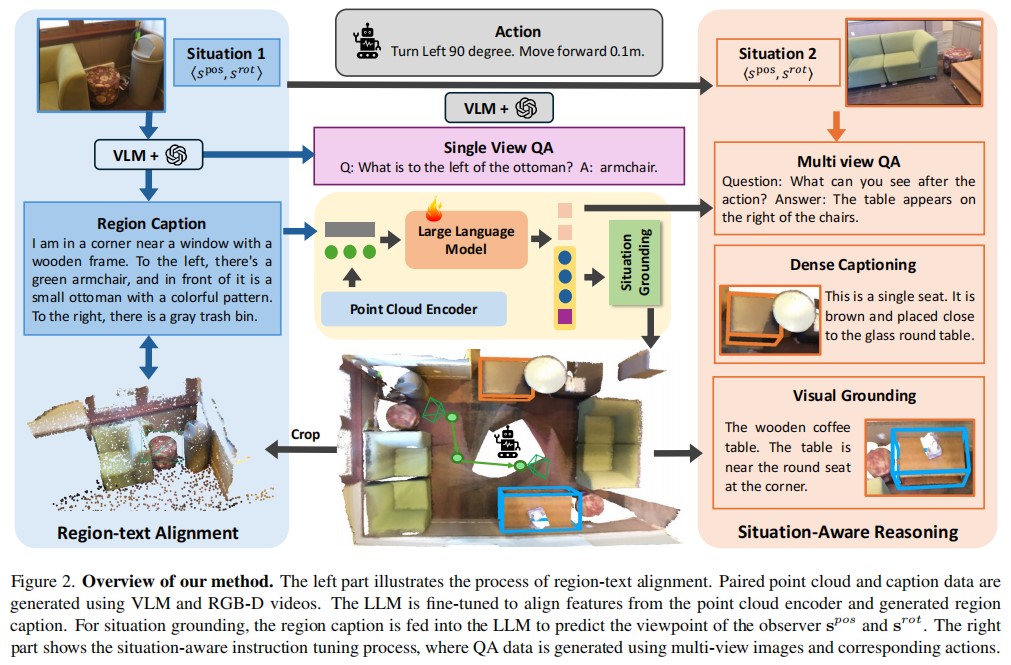
Driven by the great success of Large Language Models (LLMs) in the 2D image domain, their application in 3D scene understanding has emerged as a new trend. A key difference between 3D and 2D is that the situation of an egocentric observer in 3D scenes can change, resulting in different descriptions (e.g., “left” or “right”). However, current LLM-based methods overlook the egocentric perspective and use datasets from a global viewpoint. To address this issue, we propose a novel approach to automatically generate a situation-aware dataset by leveraging the scanning trajectory during data collection and utilizing Vision-Language Models (VLMs) to produce high-quality captions and question-answer pairs. Furthermore, we introduce a situation grounding module to explicitly predict the position and orientation of the observer’s viewpoint, thereby enabling LLMs to ground situation descriptions in 3D scenes. We evaluate our approach on several benchmarks, demonstrating that our method effectively enhances the 3D situational awareness of LLMs while significantly expanding existing datasets and reducing manual effort.
Framework
Experiment
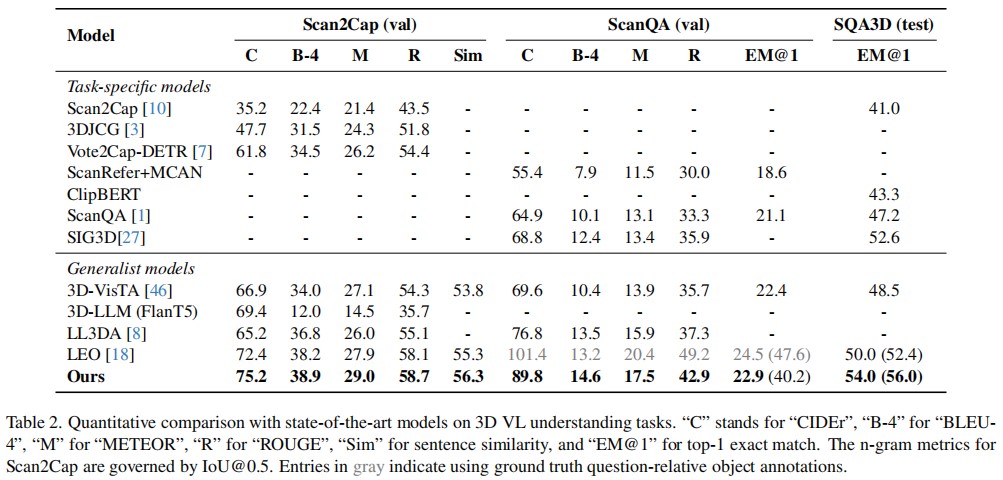
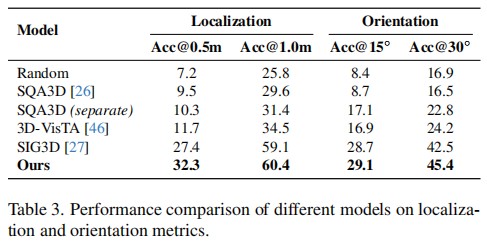
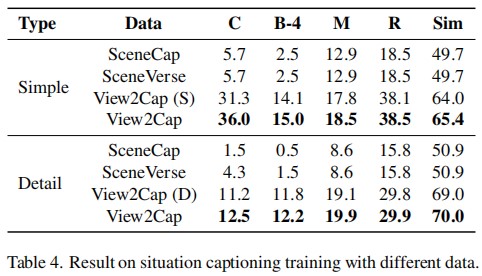

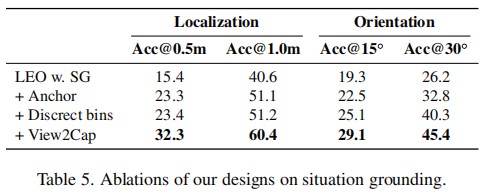
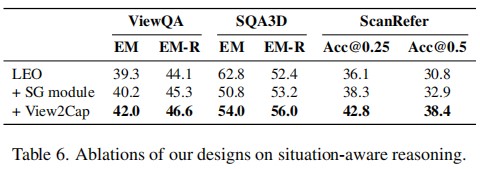
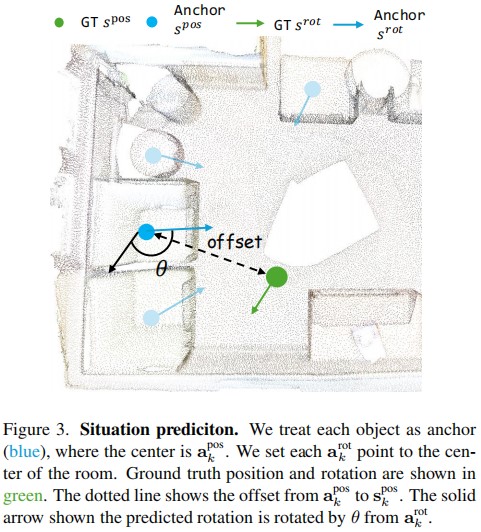
Conclusion
In this paper, we presented a novel approach to enhance 3D LLMs with situational awareness. Recognizing the limitations of existing methods that overlook the egocentric perspective inherent in 3D environments, we proposed the automatic generation of a situation-aware dataset called View2Cap. By leveraging the scanning trajectories from RGB-D video data and utilizing powerful VLMs, we produced high-quality captions and QA pairs that capture the dynamic viewpoints of an observer moving through a 3D scene. Furthermore, we introduced a situation grounding module, enabling LLMs to ground textual descriptions to situations in 3D space explicitly. We hope our work will advance the first-person 3D understanding of embodied tasks.
中山大学人机物智能融合实验室
Human Cyber Physical Intelligence Integration Lab
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号
Official Account

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab
©2026 HCP in SYSU 粤ICP备2021037607号
©2026 HCP in SYSU
粤ICP备2021037607号