
CVPR 2025
LLM-driven Multimodal and Multi-Identity Listening Head Generation
Abstract
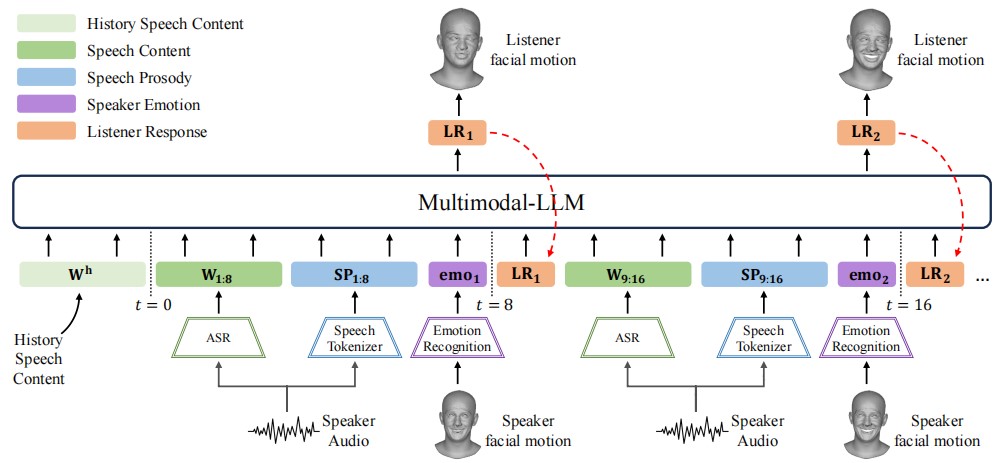
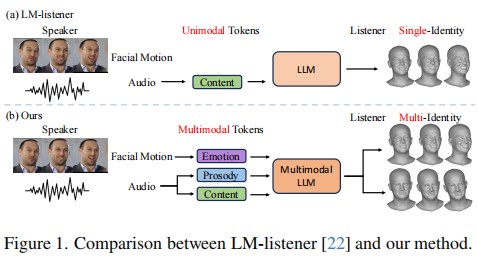
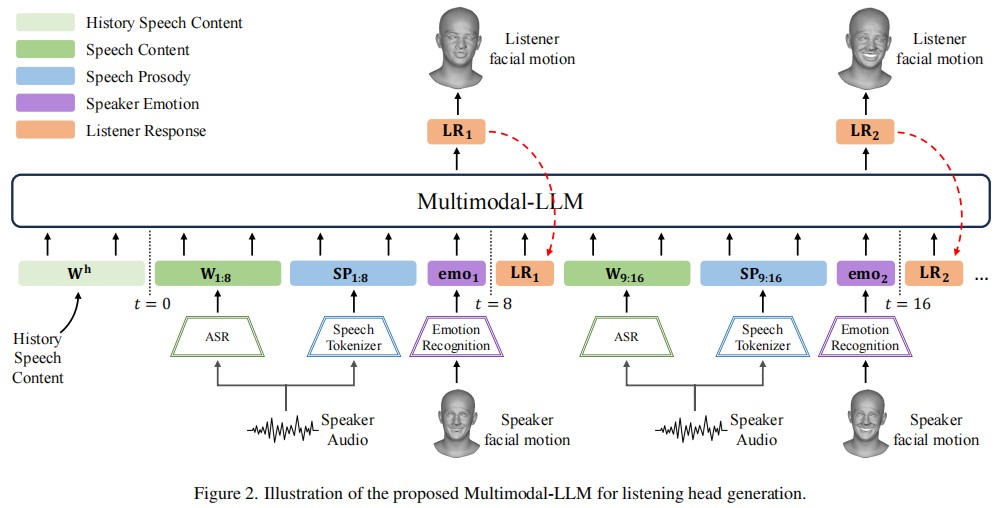
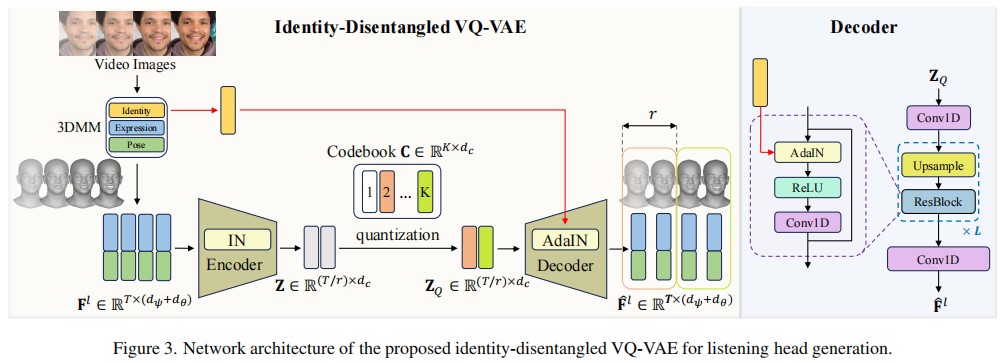
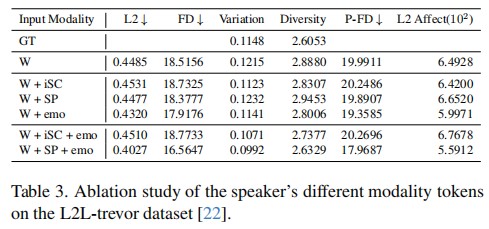
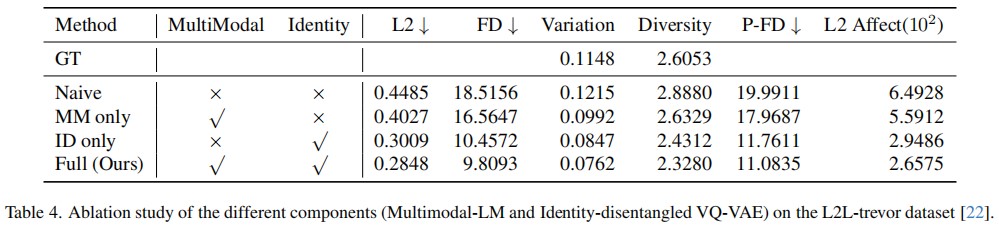
Generating natural listener responses in conversational scenarios is crucial for creating engaging digital humans and avatars. Recent work has shown that large language models (LLMs) can be effectively leveraged for this task, demonstrating remarkable capabilities in generating contextually appropriate listener behaviors. However, current LLM-based methods face two critical limitations: they rely solely on speech content, overlooking other crucial communication signals, and they entangle listener identity with response generation, compromising output fidelity and generalization. In this work, we present a novel framework that addresses these limitations while maintaining the advantages of LLMs. Our approach introduces a Multimodal-LM architecture that jointly processes speech content, prosody, and speaker emotion, capturing the full spectrum of communication cues. Additionally, we propose an identity disentanglement strategy using instance normalization and adaptive instance normalization in a VQ-VAE framework, enabling high-fidelity listening head synthesis with flexible identity control. Extensive experiments demonstrate that our method significantly outperforms existing approaches in terms of response naturalness and fidelity, while enabling effective identity control without retraining.
Framework
Experiment

Conclusion
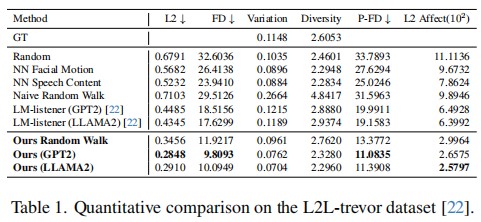
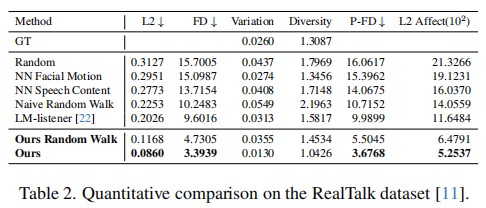
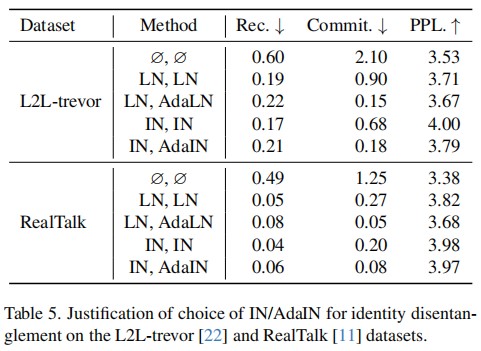
In this work, we propose a novel framework that advances listening head generation by addressing two key limitations of LLM-based approaches: i) Our method extends the LLM framework to jointly consider speech content, prosody, and speaker emotion through a carefully designed token organization strategy; ii) Our identity disentanglement approach using IN and AdaIN in the VQ-VAE framework enables high-fidelity listening head synthesis while providing flexible identity control without model retraining. Extensive experiments demonstrate the effectiveness of our approach.
中山大学人机物智能融合实验室
Human Cyber Physical Intelligence Integration Lab
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号
Official Account

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab
©2026 HCP in SYSU 粤ICP备2021037607号
©2026 HCP in SYSU
粤ICP备2021037607号