
https://github.com/HCPLab-SYSU/CRA-GQA
Abstract
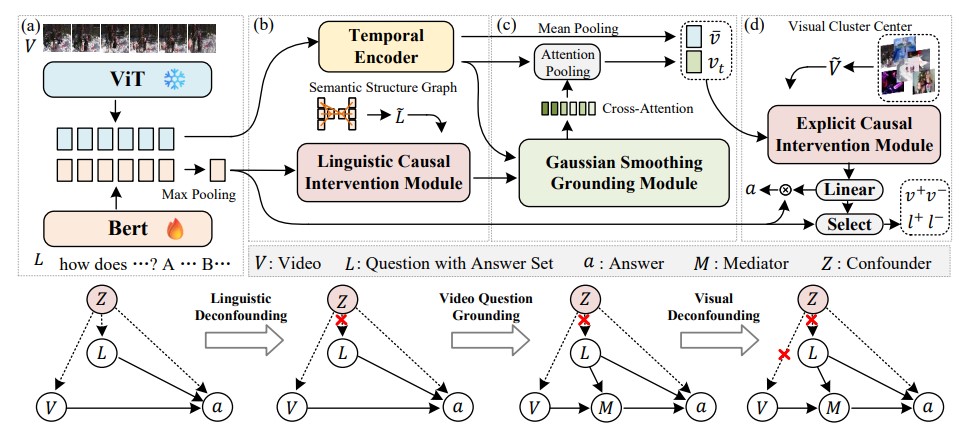
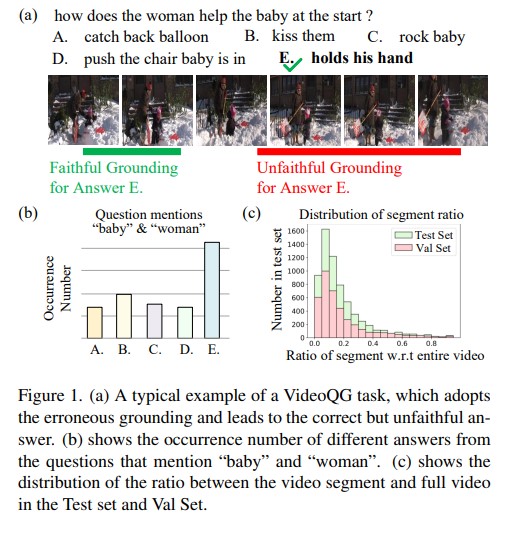
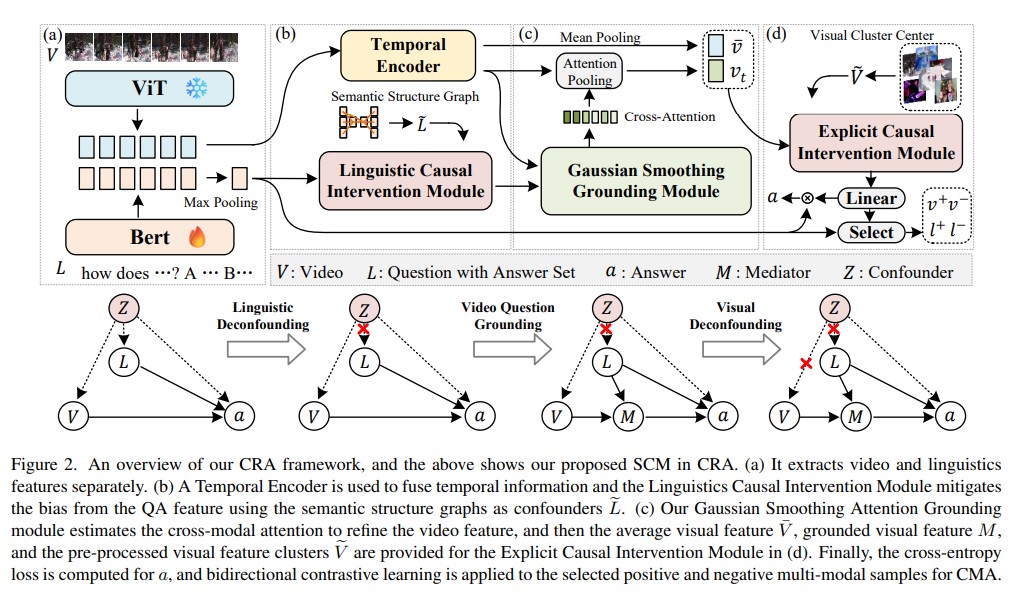
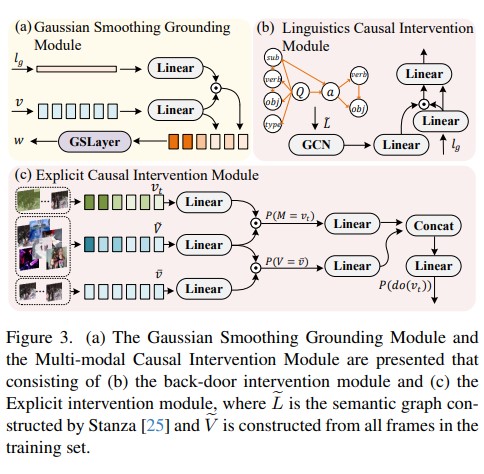
Video question grounding (VideoQG) requires models to answer the questions and simultaneously infer the relevant video segments to support the answers. However, existing VideoQG methods usually suffer from spurious cross-modal correlations, leading to a failure to identify the dominant visual scenes that align with the intended question. Moreover, vision-language models exhibit unfaithful generalization performance and lack robustness on challenging downstream tasks such as VideoQG. In this work, we propose a novel VideoQG framework named Cross-modal Causal Relation Alignment (CRA), to eliminate spurious correlations and improve the causal consistency between question-answering and video temporal grounding. Our CRA involves three essential components: i) Gaussian Smoothing Grounding (GSG) module for estimating the time interval via cross-modal attention, which is de-noised by an adaptive Gaussian filter, ii) Cross-Modal Alignment (CMA) enhances the performance of weakly supervised VideoQG by leveraging bidirectional contrastive learning between estimated video segments and QA features, iii) Explicit Causal Intervention (ECI) module for multimodal deconfounding, which involves front-door intervention for vision and back-door intervention for language. Extensive experiments on two VideoQG datasets demonstrate the superiority of our CRA in discovering visually grounded content and achieving robust question reasoning.
Framework
Experiment
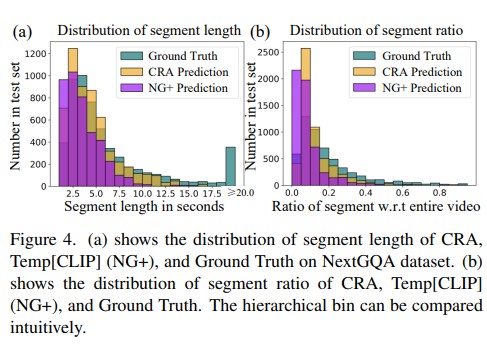



Conclusion
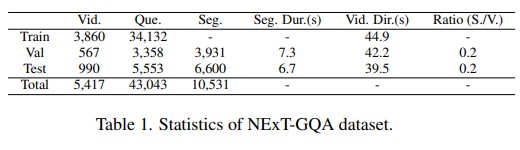
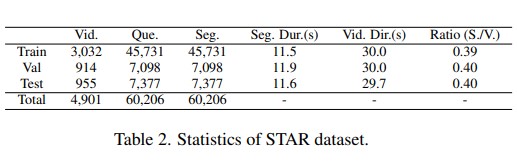
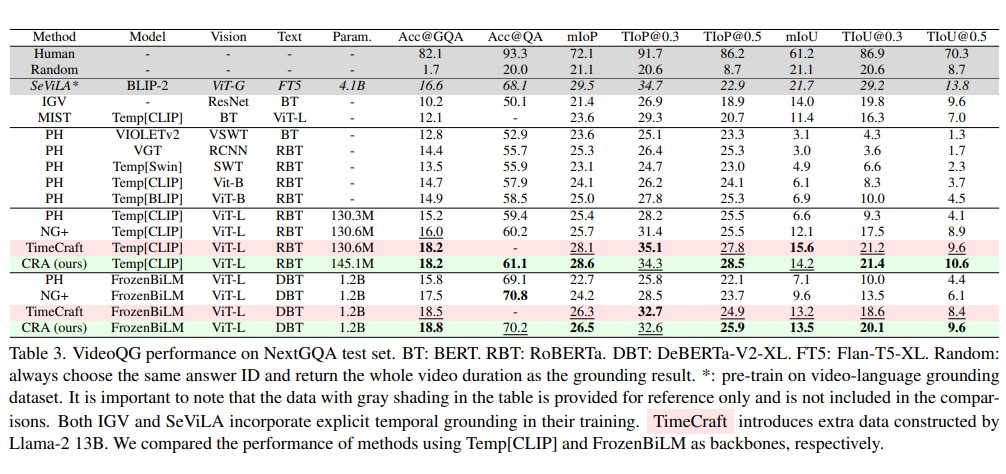
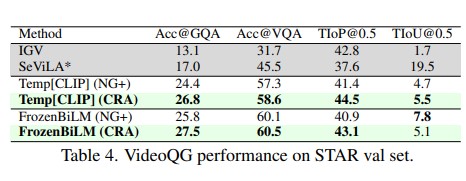
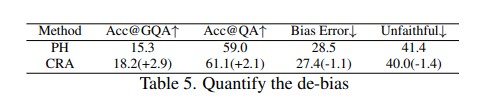
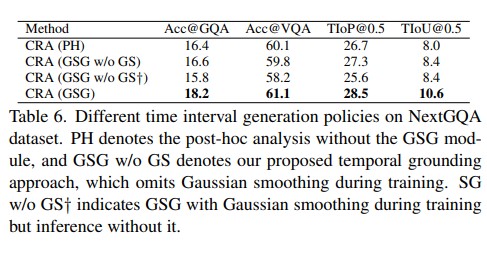
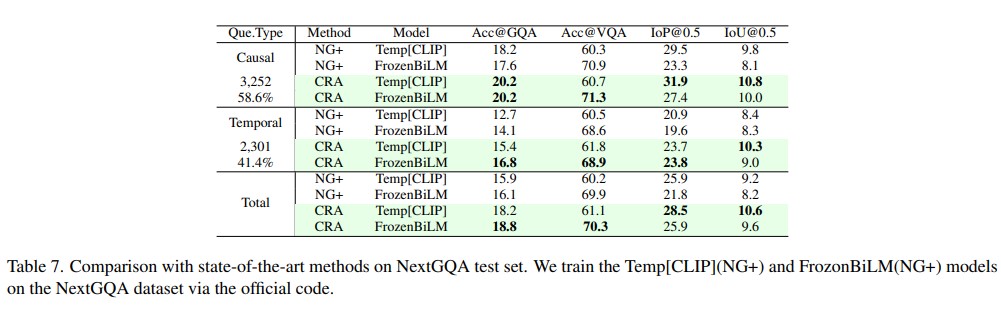
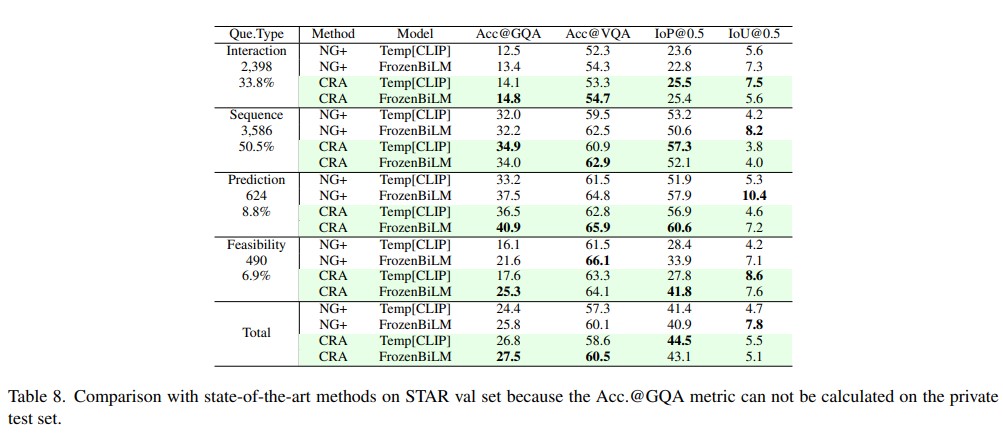
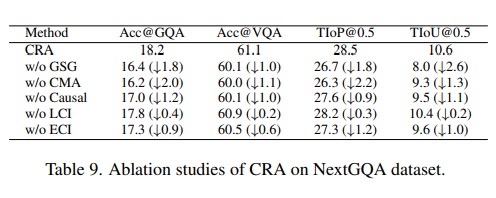
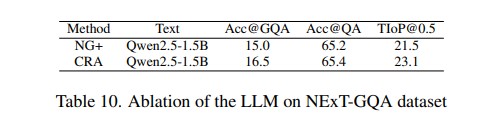
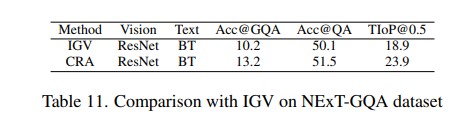
This paper aims to perform cross-modal causal relation alignment to interpret grounded video segments during the question-answering process in VideoQG. We propose a weakly supervised VideoQG model that leverages existing VideoQA datasets and introduce cross-modal alignment to further enhance feature alignment across modalities. Additionally, we incorporate an explicit causal intervention module to eliminate spurious cross-modal correlations, thereby improving the causal consistency between question-answering and temporal grounding. Extensive experiments on NextGQA and STAR datasets demonstrate the effectiveness of our approach. The promising results, including high Acc@GQA and IoU@0.5 scores, show that our CRA achieves robust and reliable VideoQG performance, effectively grounding visual content and supporting accurate question reasoning.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab