
Abstract
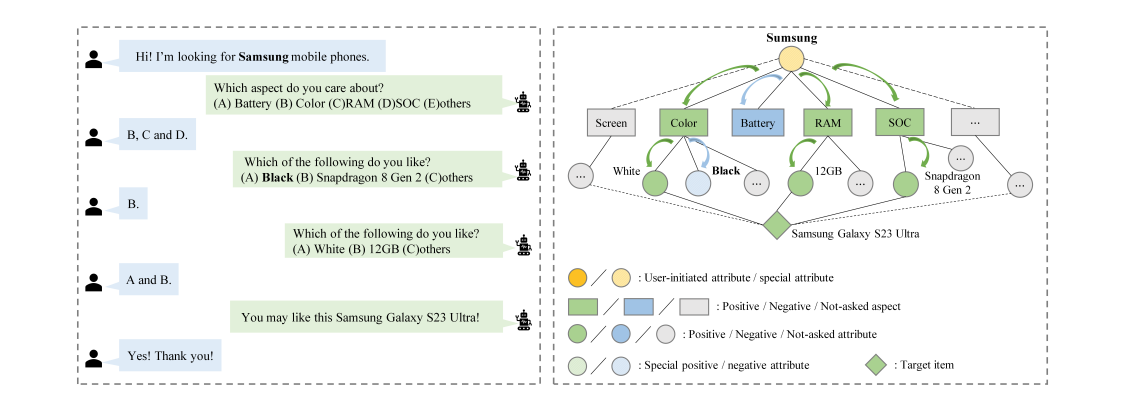
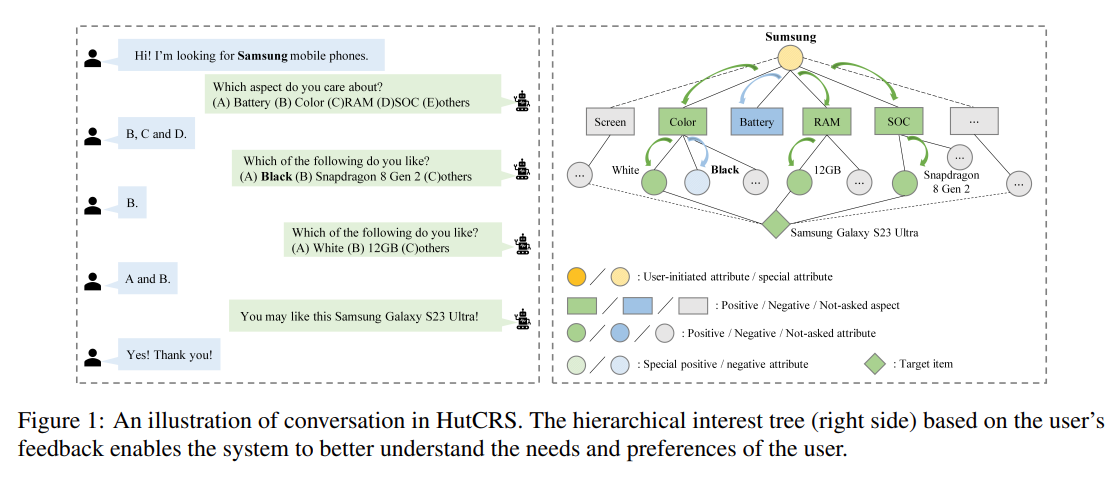
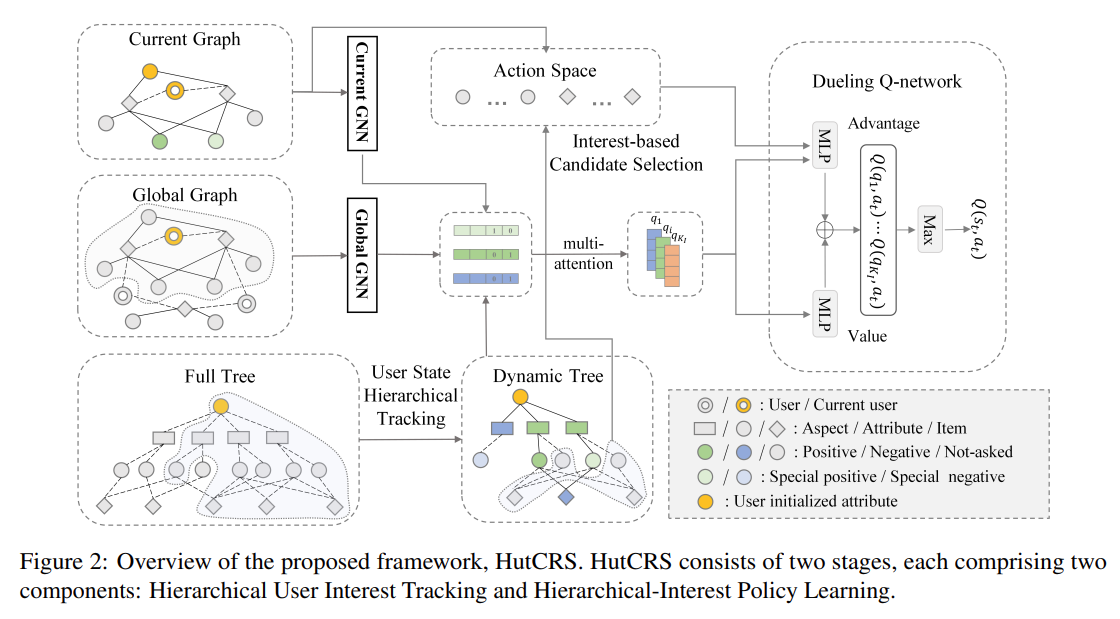
Conversational Recommender System (CRS) aims to explicitly acquire user preferences towards items and attributes through natural language conversations. However, existing CRS methods ask users to provide explicit answers (yes/no) for each attribute they require, regardless of users’ knowledge or interest, which may significantly reduce the user experience and semantic consistency. Furthermore, these methods assume that users like all attributes of the target item and dislike those unrelated to it, which can introduce bias in attribute level feedback and impede the system’s ability to accurately identify the target item. To address these issues, we propose a more realistic, user-friendly, and explainable CRS framework called Hierarchical User-Interest Tracking for Conversational Recommender System (HutCRS). HutCRS portrays the conversation as a hierarchical interest tree that consists of two stages. In stage I, the system identifies the aspects that the user prefers while the system asks about attributes related to these positive aspects or recommends items in stage II. In addition, we develop a Hierarchical-Interest Policy Learning (HIPL) module to integrate the decision-making process of which aspects to ask and when to ask about attributes or recommend items. Moreover, we classify the attribute-level feedback results to further enhance the system’s ability to capture special information, such as attribute instances that are accepted by users but not presented in their historical interactive data. Extensive experiments on four benchmark datasets demonstrate the superiority of our method. The implementation of HutCRS is publicly available at https://github.com/xinle1129/HutCRS.
Framework
Experiment
Conclusion
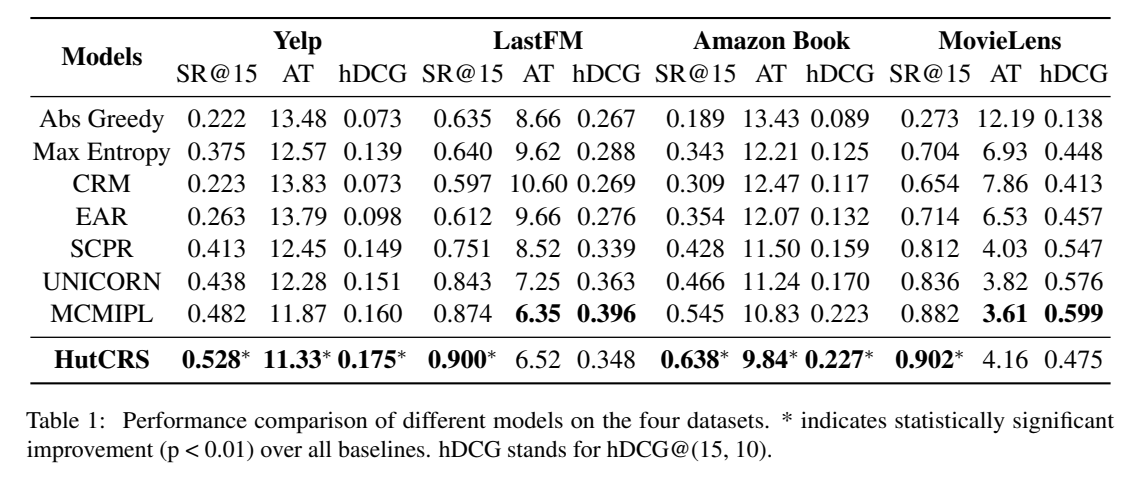
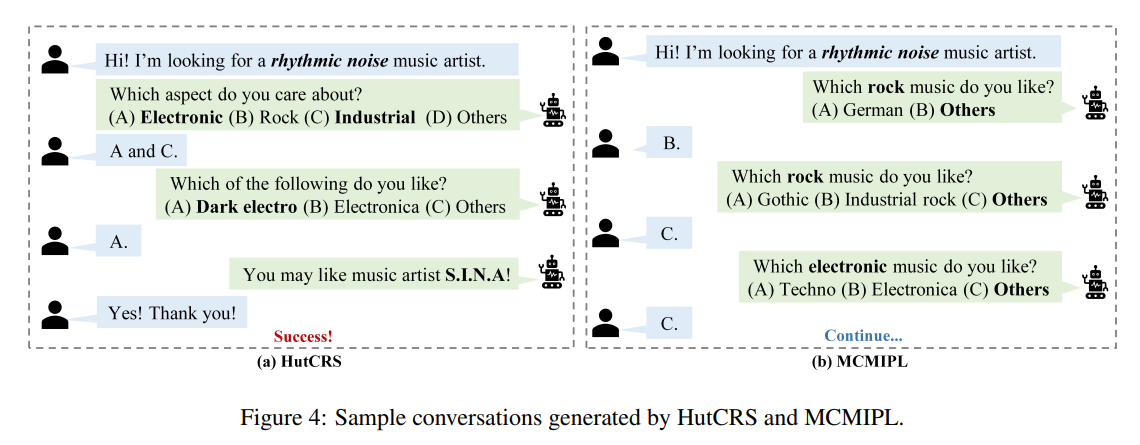
In this paper, we propose a more realistic, user-friendly, and explainable framework HutCRS, which portrays the conversation as a hierarchical interest tree consisting of two stages. In addition, we design a HIPL module to integrate the decision making process and classify attribute-level feedback to capture special information. Extensive experiments on four benchmark datasets demonstrate the superiority of our method.
Acknowledgement
This work is supported in part by the National Key R&D Program of China under Grant No.2021ZD0111601; in part by the National Natural Science Foundation of China under Grant No.U21A20470, Grant No.61836012, and Grant No. 62206314; in part by the GuangDong Basic and Applied Basic Research Foundation under Grant No. 2023A1515011374 and Grant No. 2022A1515011835; in part by the Guangdong Province Key Laboratory of Information Security Technology; and in part by the China Postdoctoral Science Foundation Funded Project under Grant No. 2021M703687.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab