

Description
We present a new large-scale dataset focusing on semantic understanding of person. The dataset is an order of magnitude larger and more challenge than similar previous attempts that contains 50,000 images with elaborated pixel-wise annotations with 19 semantic human part labels and 2D human poses with 16 key points. The images collected from the real-world scenarios contain human appearing with challenging poses and views, heavily occlusions, various appearances and low-resolutions. This challenge and benchmark are fully supported by the Human-Cyber-Physical Intelligence Integration Lab of Sun Yat-sen University.
Citation
If you use our datasets, please consider citing relevant papers:
"Instance-level Human Parsing via Part Grouping Network”
Ke Gong, Xiaodan Liang, Yicheng Li, Yimin Chen, Ming Yang, Liang Lin;
European Conference on Computer Vision (ECCV Oral), 2018.
"Adaptive Temporal Encoding Network for Video Instance-level Human Parsing”
Qixian Zhou, Xiaodan Liang, Ke Gong, Liang Lin;
ACM International Conference on Multimedia (ACM MM), 2018.
"Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark”
Xiaodan Liang, Ke Gong, Xiaohui Shen, and Liang Lin;
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2018.
"Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing"
Ke Gong, Xiaodan Liang, Dongyu Zhang, Xiaohui Shen, Liang Lin;
2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017).
“Human Parsing With Contextualized Convolutional Neural Network”
Xiaodan Liang, Chunyan Xu, Xiaohui Shen, Jianchao Yang, Si Liu, Jinhui Tang, Liang Lin, Shuicheng Yan;
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), DOI: 10.1109/TPAMI.2016.2537339, 2016.
License
This LIP Dataset is made freely available to academic and non-academic entities for non-commercial purposes such as academic research, teaching, scientific publications, or personal experimentation. Permission is granted to use the data given that you agree to our license terms.

Description
We introduce a new large-scale 2D dataset, named SODA10M, which contains 10M unlabeled images and 20k labeled images with 6 representative object categories. SODA10M is designed for promoting significant progress of self-supervised learning and domain adaptation in autonomous driving. It is the largest 2D autonomous driving dataset until now and will serve as a more challenging benchmark for the community.
Citation
Jianhua Han and Xiwen Liang and Hang Xu and Kai Chen and Lanqing Hong and Jiageng Mao and Chaoqiang Ye and Wei Zhang and Zhenguo Li and Xiaodan Liang and Chunjing Xu, "SODA10M: A Large-Scale 2D Self/Semi-Supervised Object Detection Dataset for Autonomous Driving", NeurIPS 2021 Datasets and Benchmarks Track (Round 2), 2021

Description
No weakly supervised Re-ID dataset is publicly available. To fill this gap, we contribute a new ReID dataset named SYSU-30k in the wild to facilitate studies. We download many short program videos from the Internet. TV programs are considered as our video source for two reasons. First, the pedestrians in a TV program video are often cross-view and cross-camera because there are many movable cameras to capture the shots for post-processing. Reidentifying pedestrians in a TV program video is exactly a ReID problem in the wild. Second, the number of pedestrians in a program is suitable for annotation. On average, each video contains 30.5 pedestrians walking around.
Citation
Guangrun Wang et al. “Weakly Supervised Person Re-ID: Differentiable Graphical Learning and a New Benchmark” IEEE Transactions on Neural Networks 32 (2021): 2142-2156.
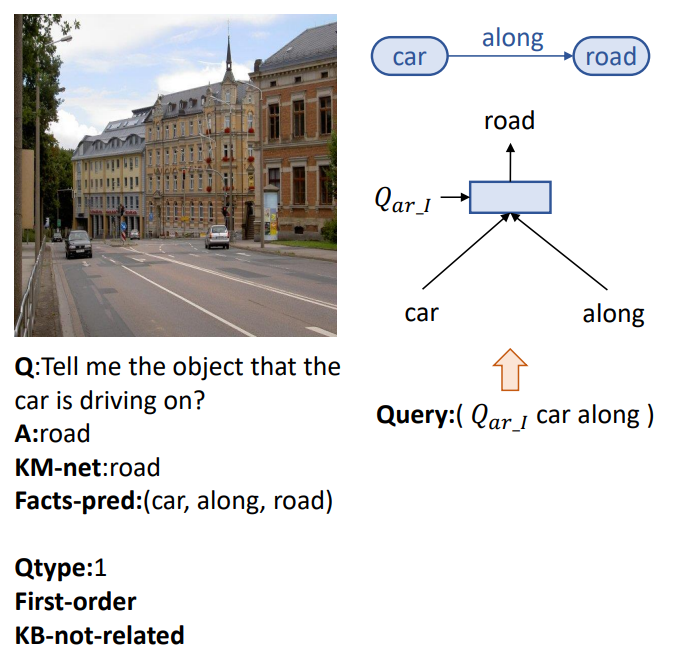
Description
The proposed Knowledge-Routed Visual Question Reasoning(KRVQA) dataset aims to evaluate the reasoning ability of external knowledge while prevent the models from exploiting superficial relations. It consists of 32, 910 images and 157, 201 question-answer pairs of different types for testing a variety of skills of the given VQA model. Compared with previous datasets, our proposed KRVQA has the following advantages: i) We use the tightly controlled program on explicit scene graph and knowledge base to minimize the bias on both image and knowledge; ii) We provide the groundtruth program to enable inspection on the reasoning behavior of a VQA model; and iii) each knowledge triplet only appears once for all questions to pose the new challenges for deep embedding networks to correctly embed the knowledge base and handle the unseen questions.
Citation
Qingxing Cao et al. “Knowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding..” IEEE Transactions on Neural Networks (2021): 1-10.

Description
We collected 50 grayscale-thermal video clips under different scenarios and conditions, e.g., office areas, public roads, and water pool, etc. Each grayscale video is paired with one thermal video. We manually annotated them with ground truth bounding boxes. All annotations are done by a full-time annotator, to guarantee consistency.
Citation
Chenglong Li, Hui Cheng, Shiyi Hu, Xiaobai Liu, Jin Tang, and Liang Lin, “Learning Collaborative Sparse Representation for Grayscale-Thermal Tracking”, IEEE Transactions on Image Processing, 2016.

Description
It is urgent need to study the multi-model moving object detection due to its own shortness of inadequate of single model videos. However, almost no complete good multi-model datasets to use, thus, we proposed a multi-model moving object detection dataset and the specific details as followings.Our multi-model moving object detection dataset mainly considered 7 challenges, i.e. interminttent motion, low illumination, bad weather, intense shadow, dynamic scene, background clutter, thermal crossover et al.
The following main aspects are taken into account in creating the grayscale-thermal video:
1. Scene category. Including laboratory rooms, campus roads, playgrounds and water pools et al.
2. Object category. Including rigid and non-rigid objects, such as vehicles, pedestrians and animals.
3. Intermittent motion.
4. Shadow effect.
5. Illumination condition.
6. Background factor.
Citation
Chenglong Li, Xiao Wang, Lei Zhang, Jin Tang, Hejun Wu, Liang Lin*, “WELD: Weighted Low-rank Decomposition for Robust Grayscale-Thermal Foreground Detection”, IEEE Transactions on Circuits and Systems for Video Technology (T-CSVT), DOI: 10.1109/TCSVT.2016.2556586, 2016.

Description
The Office Activity (OA) dataset collected by us is a more complex activity dataset which covers the common daily activities happened in office. It is a large dataset with 1180 RGB-D activity sequences. To capture human activities in multi-views, we set three RGB-D sensors in different viewpoints for recording and each subject is asked to perform twice in one activity. To increase the variability of the activities, we record them in two different scenes, i.e., two different offices. More importantly, we not only consider the single human activity, but also deal with the problem with more than one people.
Citation
Liang Lin, Keze Wang, Wangmeng Zuo, Meng Wang, Jiebo Luo, and Lei Zhang, “A Deep Structured Model with Radius-Margin Bound for 3D Human Activity Recognition”, International Journal of Computer Vision (IJCV), 118(2): 256-273, 2016.

Description
This database includes general and realistic challenges for people re-identification in surveillance. We record videos using 3 cameras from different views and extract individuals as well as video shots within the videos. We also annotate the body part configurations for each query instance and annotate ID and locations (bounding box) for each video shot. In total, there are 370 reference images (normalized to 175 pixels in height), for 74 individuals, with IDs and locations provided. We extract 214 shots (640 x 360) containing 1519 target individuals. Note that the targets often appear with diverse poses/views or occluded by other people within the scenarios.
Citation
Yuanlu Xu, Liang Lin*, Wei-Shi Zheng, and Xiaobai Liu, “Human Re-identification by Matching Compositional Template with Cluster Sampling”, Proc. of IEEE International Conference on Computer Vision (ICCV), 2013

Description
The SYSU-CT and SYSU-US are both provided by the first affiliated hospital, Sun Yat-sen University. The SYSU-CT data set is constructed by seven CT volumetric images of liver tumor from different patients:all the patients were scanned using a 64 detector row CT machine (Aquilion64, Toshiba Medical System). The SYSU-US data set consists of 20 US image sequences of abdomen with liver tumor.
Citation
Liang Lin, Wei Yang, Chenglong Li, Jin Tang, and Xiaochun Cao. Inference with Collaborative Model for Interactive Tumor Segmentation in Medical Image Sequences. IEEE Transactions on Cybernetics (T-Cybernetics), 2015

Description
The dataset is a large scale benchmark for person search, containing 18,184 images and 8,432 identities.
The dataset can be divided into two parts according to the image sources: street snap and movie: In street snap, images were collected with hand-held cameras across hundreds of scenes and tried to include variations of view-points, lighting, resolutions, occlusions, and background as much as possible.We choose movies and TV dramas as another source for collecting images, because they provide more diversified scenes and more challenging viewpoints.
Citation
Tong Xiao*, Shuang Li*, Bochao Wang, Liang Lin, Xiaogang Wang. Joint Detection and Identification Feature Learning for Person Search. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Spotlight, 2017
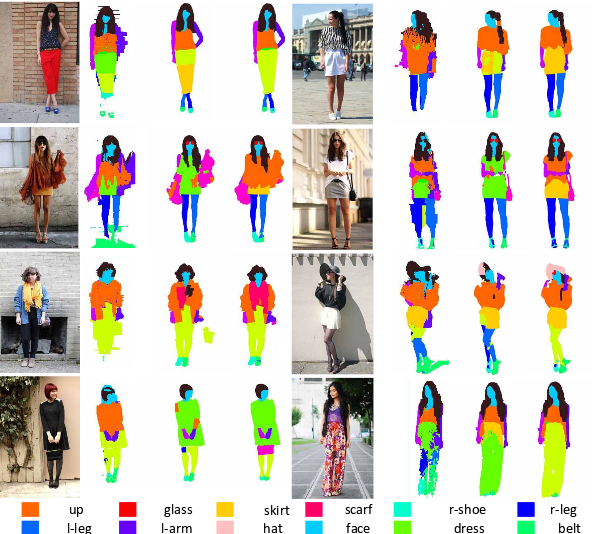
Description
This human parsing dataset includes the detailed pixel-wise annotations for fashion images, which is proposed in our TPAMI paper “Deep Human Parsing with Active Template Regression”, and ICCV 2015 paper “Human Parsing with Contextualized Convolutional Neural Network”. This dataset contains 7700 images.We use 6000 images for training,1000 for testing and 700 as the validation set.
Citation
Xiaodan Liang, Si Liu, Xiaohui Shen , Jianchao Yang, Luoqi Liu, Jian Dong, Liang Lin, Shuicheng Yan, “Deep Human Parsing with Active Template Regression” , IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), in press, 2015.
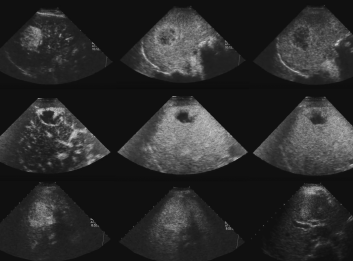
Description
The dataset consists of CEUS data of FLLs in three types: 186 HCC, 109 HEM and 58 FNH instances (i.e. 186 malignant and 167 benign instances). The equipment used was Aplio SSA-770A (Toshiba Medical System), and all videos included in the dataset are collected from pre-operative scans
Citation
Xiaodan Liang, Liang Lin, Qingxing Cao, Rui Huang, Yongtian Wang, “Recognizing Focal Liver Lesions in CEUS with Dynamically Trained Latent Structured Models”. IEEE TRANSACTIONS ON MEDICAL IMAGING (T-MI), 2015

Description
TCD contains 800 commodity images (dresses, jeans, T-shirts, shoes and hats) from the shops on the Taobao website. The ground truth masks of the TCD dataset are obtained by inviting common sellers of Taobao website to annotate their commodities, i.e., masking salient objects that they want to show from their exhibition. These images include all kinds of commodity with and without human models, thus having complex backgrounds and scenes with highly complex foregrounds. Pixel-accurate ground truth masks are given.
Citation
Keze Wang, Liang Lin, Jiangbo Lu, Chenglong Li, Keyang Shi. “PISA: Pixelwise Image Saliency by Aggregating Complementary Appearance Contrast Measures with Edge-Preserving Coherence.”, in IEEE Trans. Image Process., vol. 24, no. 10, pp. 3019-3033, 2015. (A shorter previous version was published in CVPR 2013.)

Description
SYSU-Shapes dataset is a new shape database including elaborately annotated shape contours. Compared with the existing shape databases, this database includes more realistic challenges in shape detection and localization, e.g., cluttered backgrounds, large intraclass variations, and different poses/views, in which part of the instances were originally used for appearance-based object detection.
There are 5 categories, i.e. airplanes, boats, cars, motorbikes, and bicycles, and each category contains 200~500 images.
Citation
Liang Lin, Xiaolong Wang, Wei Yang, and JianHuang Lai, Discriminatively Trained And-Or Graph Models for Object Shape Detection, IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), DOI: 10.1109/TPAMI.2014.2359888, 2014.

Description
This Object Extraction newly collected by us contains 10183 images with groundtruth segmentation masks. We selected the images from the PASCAL[1], iCoseg[2], Internet [3] dataset as well as other data (most of them are about people and clothes) from the web. We randomly split the dataset with 8230 images for training and 1953 images for testing.
Citation
Xiaolong Wang, Liliang Zhang, Liang Lin*, Zhujin Liang, Wangmeng Zuo, “Deep Joint Task Learning for Generic Object Extraction”, NIPS 2014.

Description
Kinect2 Human Gesture Dataset (K2HGD) includes about 100K depth images with various human poses under challenging scenarios. As illustrated in Fig.~\ref{fig:dataset}, this dataset consists of 19 body joints of 30 subjects under ten different challenging scenes. The subject is asked to perform both normal daily poses and unusal poses. The human body joints are defined as follows: \emph{Head, Neck, MiddleSpine, RightShoulder, RightElbow, RightHand, LeftShoulder, LeftElbow, LeftHand, RightHip, RightKnee, RightFoot, LeftHip, LeftKnee, LeftFoot.}. The ground truth body joints are firstly estimated via the Kinect SDK, and further refined by active users.
Citation
Keze Wang, Shengfu Zhai, Hui Cheng, Xiaodan Liang, and Liang Lin. Human Pose Estimation from Depth Images via Inference Embedded Multi-task Learning. In Proceedings of the ACM International Conference on Multimedia (ACM MM), 2016.

Description
SYSU-Clothes dataset is a new clothing database including elaborately annotated clothing items.
- 2, 098 high-resolution street fashion photos with totally 59 tags
- Wide range of styles, accessaries, garments, and pose
- All images are with image-level annotations
- 1000+ images are with pixel-level annotations
Citation
“Clothes Co-Parsing via Joint Image Segmentation and Labeling with Application to Clothing Retrieval”, Xiaodan Liang, Liang Lin*, Wei Yang, Ping Luo, Junshi Huang, and Shuicheng Yan,IEEE Transactions on Multimedia (T-MM), 18(6): 1175-1186, 2016.(A shorter previous version was published in CVPR 2014.)

Description
Butterfly-200 is a dataset for multi-granurality image recognition.
- 25,279 high-resolution butterfly images, including natural images with the butter y in their natural living environment and standard images with the butter y in the form of specimens
- Covering 200 common species, 116 genera, 23 subfamilies, and 5 familiese.
- All images are with four-level categories.
Citation
“Fine-Grained Representation Learning and Recognition by Exploiting Hierarchical Semantic Embedding”, Tianshui Chen, Wenxi Wu, Yuefang Gao, Le Dong, Xiaonan Luo, Liang Lin

Description
SYSU16K is a large-scale dataset for Facial Landmark Localization in the Wild.
- It contains 7317 images with 16K faces collected from the Internet.
- Each face is accurately annotated with 72 landmarks.
- The faces on this dataset exhibit various pose, expression, illumination and resolution, and may have severe occlusions.
Citation
“Facial Landmark Machines: A Backbone-Branches Architecture with Progressive Representation Learning”, Lingbo Liu, Guanbin Li, Yuan Xie, Yizhou Yu, Qing Wang, and Liang Lin.
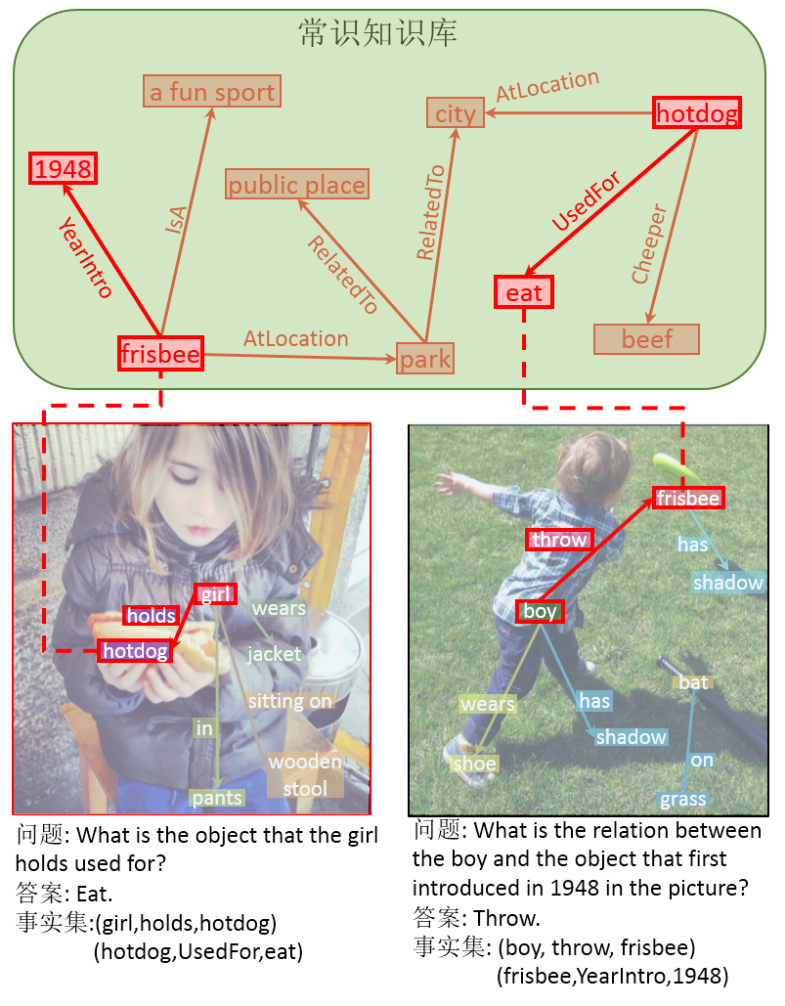
Description
We propose a novel dataset named Knowledge-Routed Visual Question Reasoning for VQA model evaluation. Considering that a desirable VQA model should correctly perceive the image context, understand the question, and incorporate its learned knowledge, our proposed dataset aims to cutoff the shortcut learning exploited by the current deep embedding models and push the research boundary of the knowledge-based visual question reasoning. Specifically, we generate the question-answer pair based on both the Visual Genome scene graph and an external knowledge base with controlled programs to disentangle the knowledge from other biases. The programs can select one or two triplets from the scene graph or knowledge base to push multi-step reasoning, avoid answer ambiguity, and balanced the answer distribution. In contrast to the existing VQA datasets, we further imply the following two major constraints on the programs to incorporate knowledge reasoning:
- Multiple knowledge triplets can be related to the question, but only one knowledge relates to the image object. This can enforce the VQA model to correctly perceive the image instead of guessing the knowledge based on the given question solely.
- All questions are based on different knowledge, but the candidate answers are the same for both the training and test sets.
Citation
“Knowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding”, Qingxing Cao, Bailin Li, Xiaodan Liang, Keze Wang, Liang Lin.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab