
Abstract
This paper investigates a fundamental problem of scene understanding: how to parse a scene image into a structured configuration (i.e., a semantic object hierarchy with object interaction relations). We propose a deep architecture consisting of two networks: i) a convolutional neural network (CNN) extracting the image representation for pixel-wise object labeling and ii) a recursive neural network (RNN) discovering the hierarchical object structure and the inter-object relations. Rather than relying on elaborative annotations (e.g., manually labeled semantic maps and relations), we train our deep model in a weakly-supervised learning manner by leveraging the descriptive sentences of the training images. Specifically, we decompose each sentence into a semantic tree consisting of nouns and verb phrases, and facilitate these trees discovering the configurations of the training images. Once these scene configurations are determined, then the parameters of both the CNN and RNN are updated accordingly by back propagation. The entire model training is accomplished through an Expectation-Maximization method. Extensive experiments show that our model is capable of producing meaningful and structured scene configurations, and achieving more favorable scene labeling result on two challenging datasets compared to other state-of-the-art weakly-supervised deep learning methods. We also release a dedicated dataset for facilitating further research on scene parsing, which contains more than 5000 scene images with their sentence-based
CNN-RNN Architecture
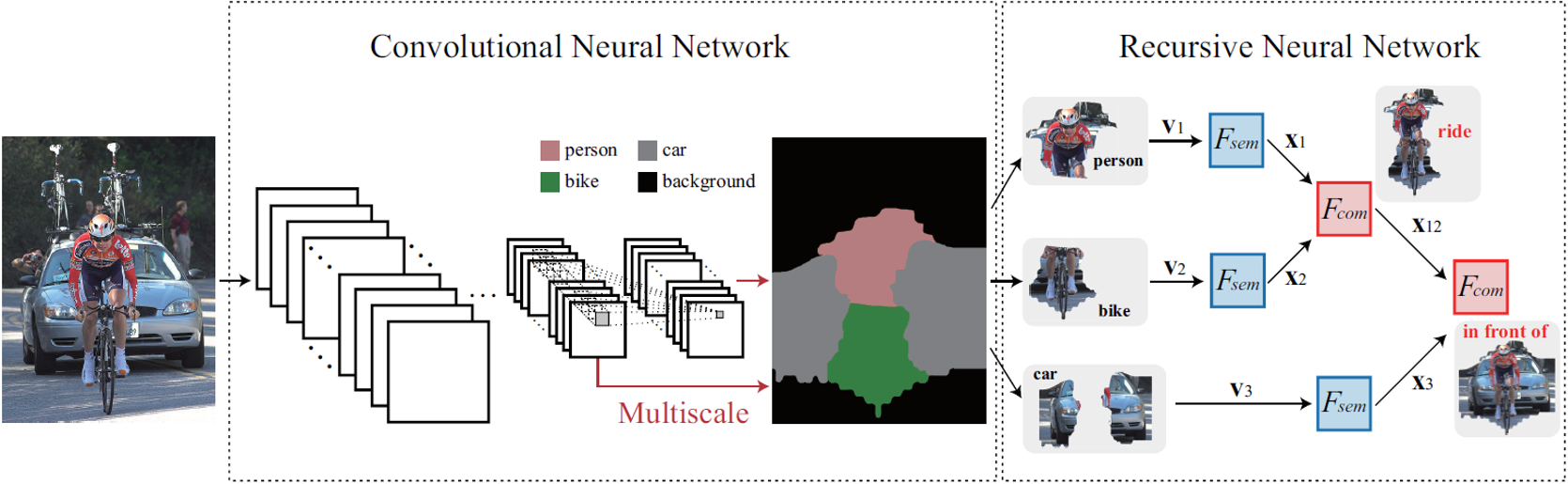
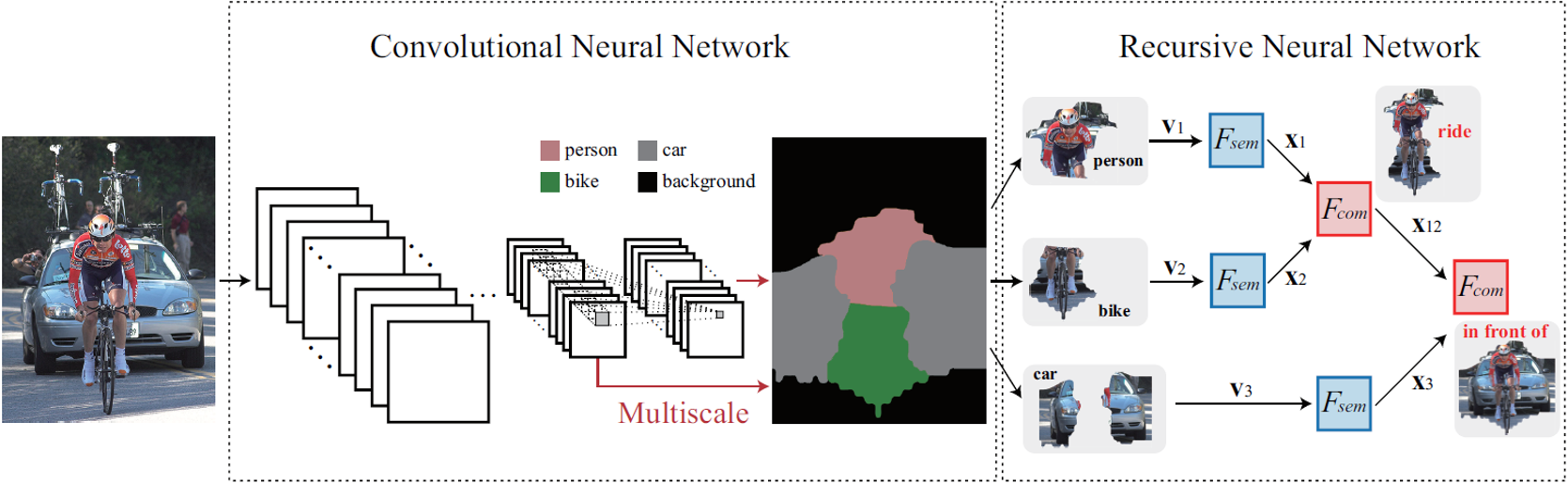
Figure 1. The proposed CNN-RNN architecture for structured scene parsing. The input image is directly fed into the CNN to produce score feature representation of each pixel and map of each semantic category. Then the model applies score maps to classify the pixels, and groups pixels with same labels to obtain feature representation v of objects. After that v is fed into the RNN, it is first mapped onto a transition space and then is used
to predict the tree structure and relations between objects. x denotes the mapped feature.
Experiments
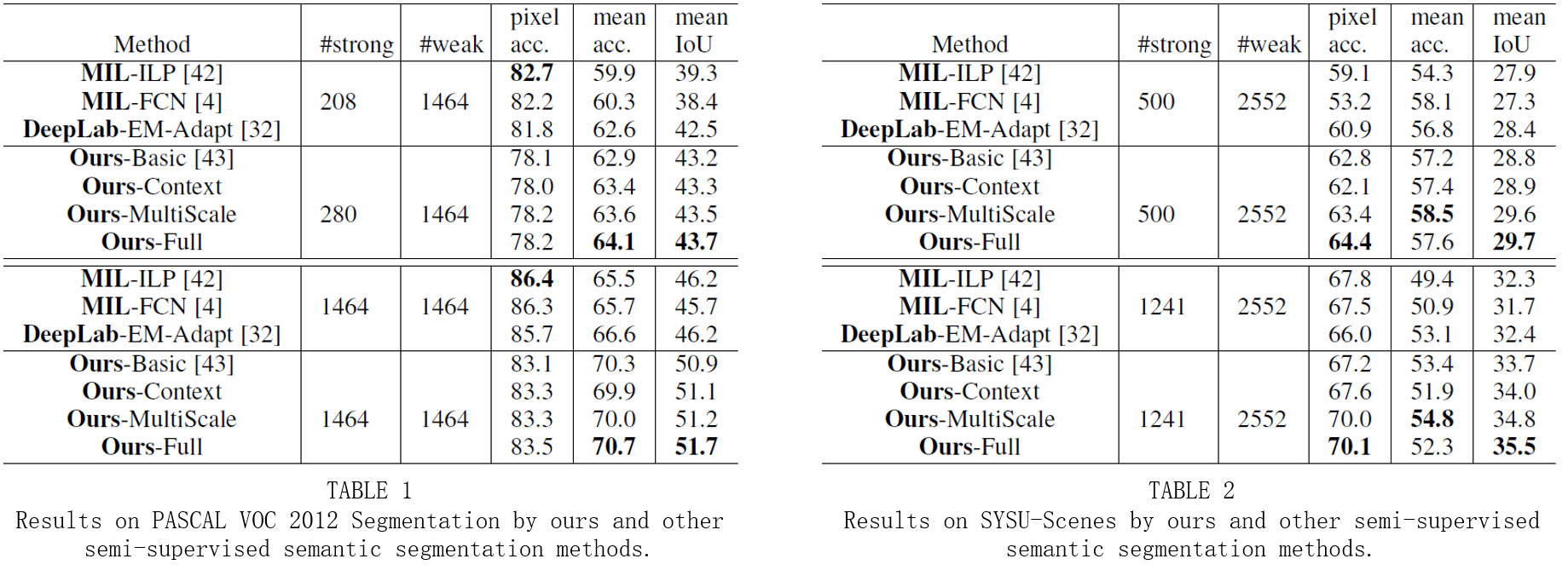


Figure 2. Visualized semantic labelling results of PASCAL 2012 val. (a) The input images; (b) The groundtruth labelling results; (c) Our proposed
method (weakly-supervised); (d) DeepLab (weakly-supervised); (e) MIL-ILP (weakly-supervised); (f) Our proposed method (semisupervised
with 280 strong training samples); (g) Our proposed method (semi-supervised with 1464 strong training samples); (h) DeepLab(semisupervised
with 280 strong training samples); (i) MIL-ILP (semi-supe.rvised with 280 strong training samples)
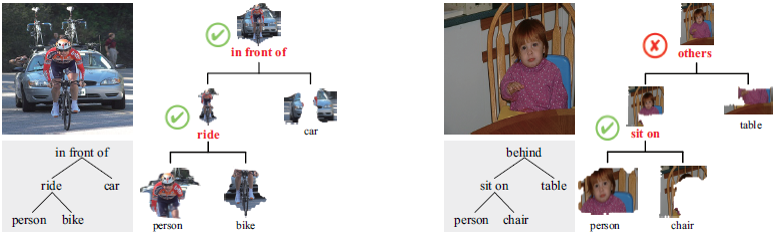
Figure 3. Visualized scene parsing results on PASCAL VOC 2012 under the weakly-supervised manner. The left one is a successful case, and the
right is a failure one. In each case, the tree on the left is produced from descriptive sentence, and the tree on the right is predicted by our method.
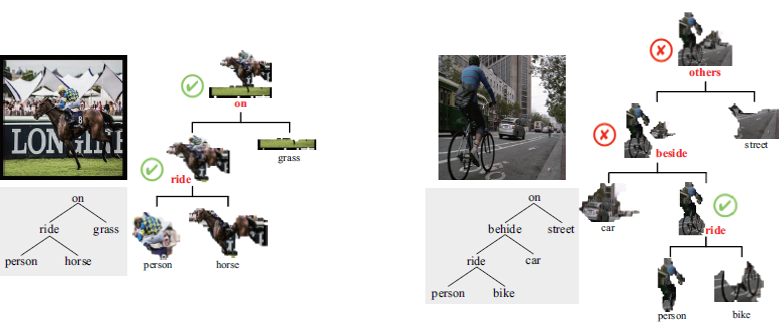
Figure 4. Visualized scene parsing results on SYSU-Scenes under the semi-supervised manner (i.e. with 500 strongly-annotated images). The left
one is a successful case, and the right is a failure one. In each case, the tree on the left is produced from descriptive sentence, and the tree on the
right is predicted by our method.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab