
CVPR 2025
Reproducible Vision-Language Models Meet Concepts Out of Pre-Training
Abstract
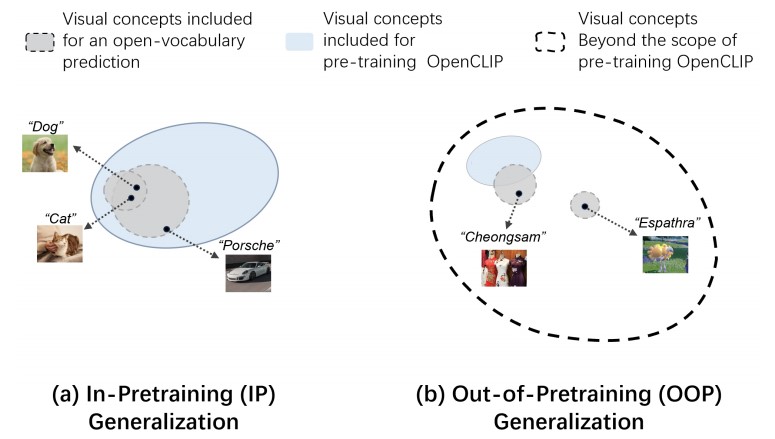
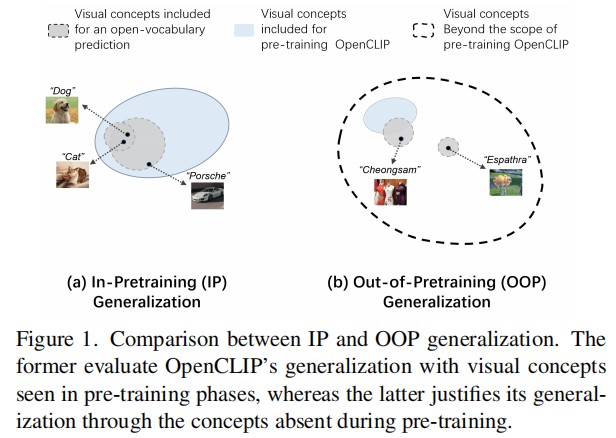
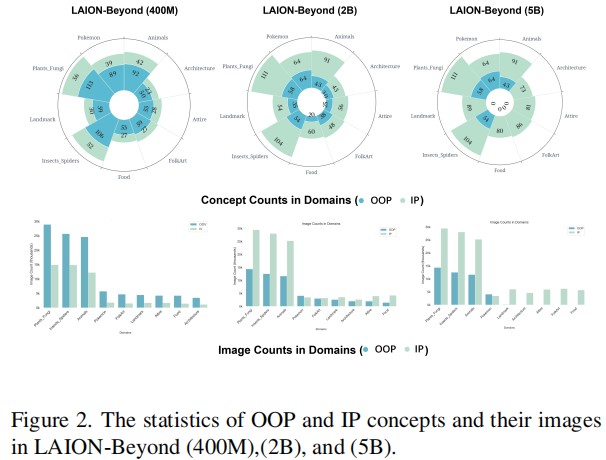
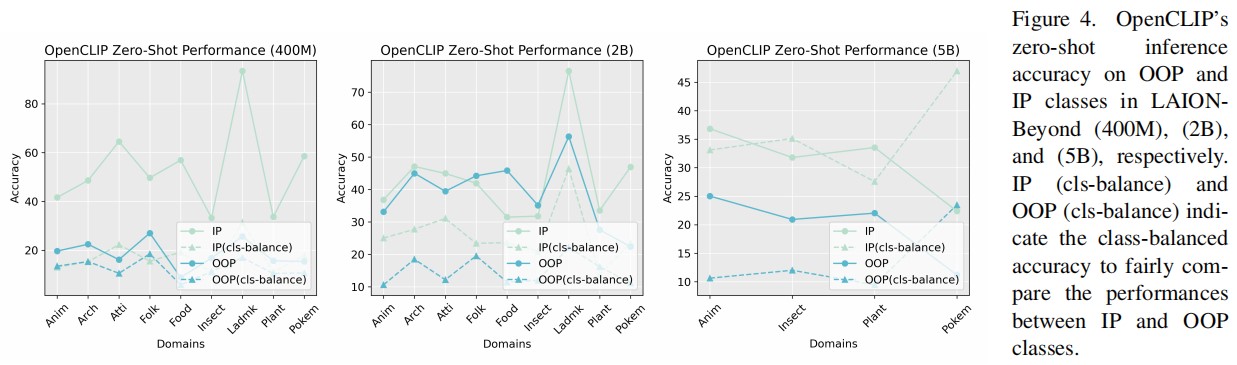
Contrastive Language-Image Pre-training (CLIP) models as a milestone of modern multimodal intelligence, its generalization mechanism grasped massive research interests in the community. While existing studies limited in the scope of pre-training knowledge, hardly underpinned its generalization to countless open-world concepts absent from the pre-training regime. This paper dives into such Out-of-Pre- training (OOP) generalization problem from a holistic perspective. We propose LAION-Beyond benchmark to isolate the evaluation of OOP concepts from pre-training knowledge, with regards to OpenCLIP and its reproducible variants derived from LAION datasets. Empirical analysis evidences that despite image features of OOP concepts born with significant category margins, their zero-shot transfer significantly fails due to the poor image-text alignment. To this, we elaborate the “name-tuning” methodology with its theoretical merits in terms of OOP generalization, then propose few-shot name learning (FSNL) and zero-shot name learning (ZSNL) algorithms to achieve OOP generalization in a data-efficient manner. Their superiority have been further verified in our comprehensive experiments.
Framework


Experiment
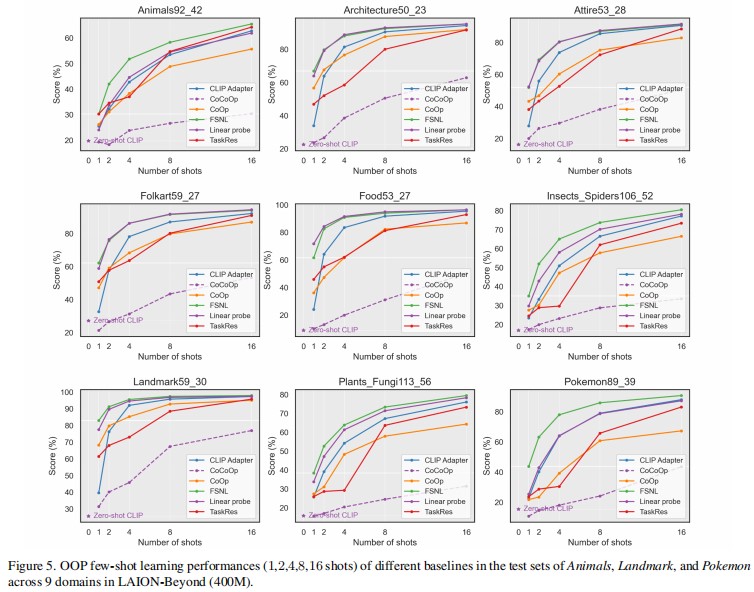
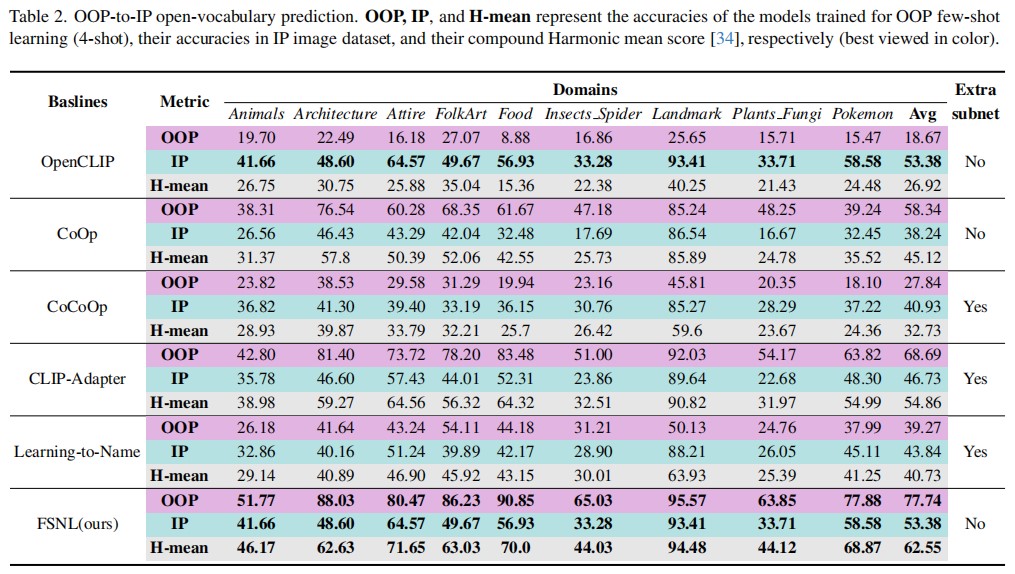
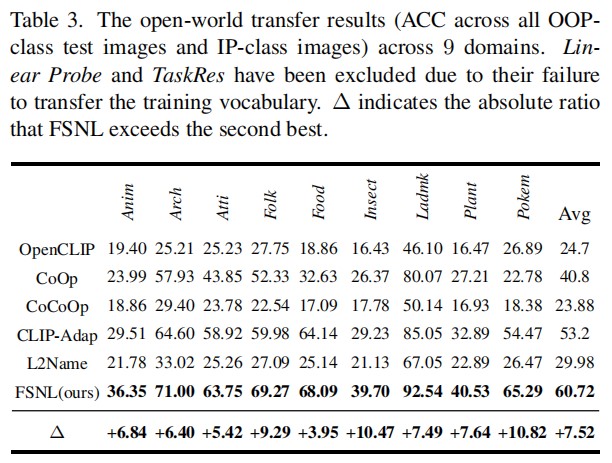
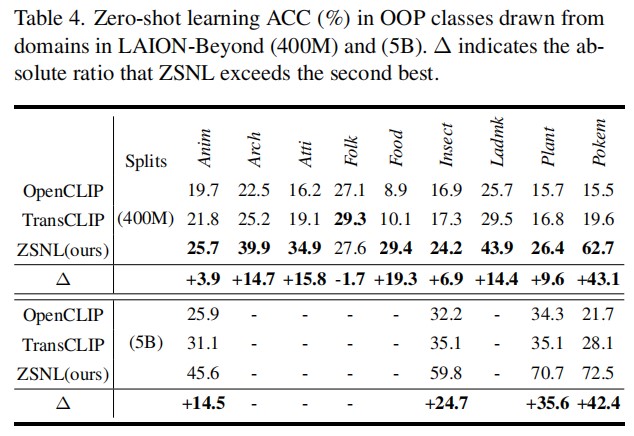
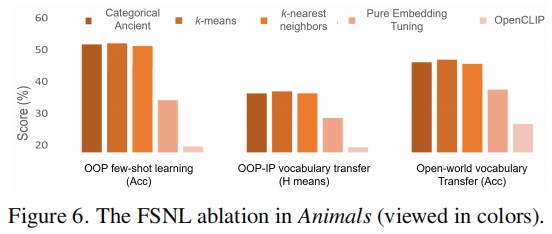
Conclusion
This research propose LAION-Beyond, not only illuminating the abilities and limitations of vision-language models in OOP concepts but also enlightens few-shot and zero-shot learning strategies to OOP generalization, contributing to the advancement of more adaptable multimodal systems.
中山大学人机物智能融合实验室
Human Cyber Physical Intelligence Integration Lab
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号
Official Account

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab
©2026 HCP in SYSU 粤ICP备2021037607号
©2026 HCP in SYSU
粤ICP备2021037607号