Single-Person Human Parsing Track
1. Metrics
We use four metrics from common semantic segmentation and scene parsing evaluations that are variations on pixel accuracy and region intersection over union (IU). The metrics are reported by FCN. The four metrics are Pixel accuracy(%) , Mean accuracy(%), Mean IoU(%) and Frequency weighted IoU(%). The details show per-class IoU(%).
2. Submit format
A folder named sp_results.zip(Click to download a template file) contains your predicted images with .png format. Each pixel in the images is a label of class. The labels are defined in our Train/Val annotations(It's available at Google Drive and Baidu Drive.) The number of images should be the same of our Testing set. Make sure these and then package the folder with zip format. Submit your sp_results.zip and wait to see your rank.
3. Class Definition
- Background
- Hat
- Hair
- Glove
- Sunglasses
- Upper-clothes
- Dress
- Coat
- Socks
- Pants
- Jumpsuits
- Scarf
- Skirt
- Face
- Left-arm
- Right-arm
- Left-leg
- Right-leg
- Left-shoe
- Right-shoe
4. Dataset Examples
4.1 Full body




4.2 Upper body

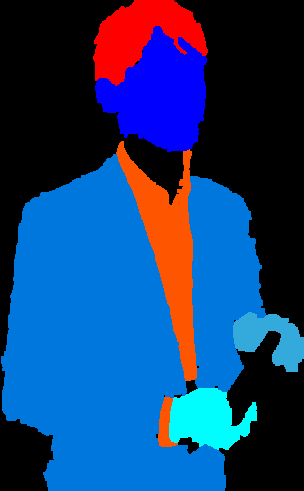


4.3 Lower body


4.4 Parts of body



4.5 Sitting




4.6 Back

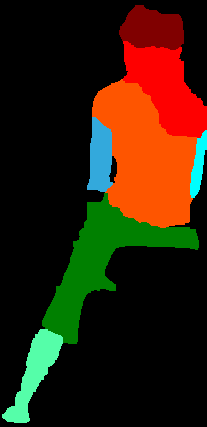

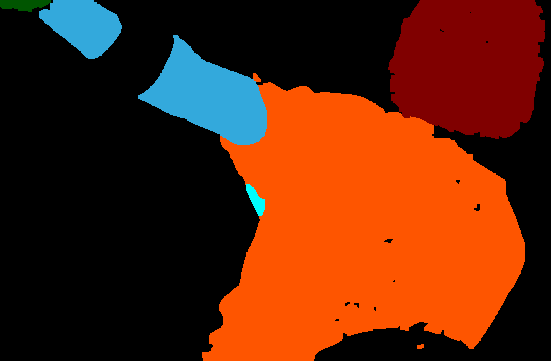
4.7 Occlusion



